|
|||||||||||||
|
|
|||||||||||||
|
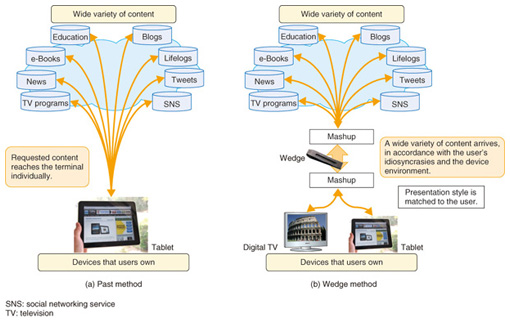
Feature Articles: Next-generation Web Platform Vol. 11, No. 4, pp. 27–32, Apr. 2013. https://doi.org/10.53829/ntr201304fa4 Personal Information StyleAbstractNTT Service Evolution Laboratories has developed the personal information style, which is a technique of providing an IT (information technology) usage environment that is customized to each user’s individual style. This article introduces a technique for obtaining information related to a video that a user is watching and casually displaying the information on the terminal in front of the user. This related information can be personalized at the touch of a fingertip, as in the interaction between a television and a tablet terminal.  1. Overview of personal information styleRecent technological advances have resulted in a huge explosion in the amount of available information, and along with this, there has been a rapid increase in content and web services that are attractive to users. At the same time, the widespread use of smartphones and tablet terminals is enabling users to use web services to access information on the web that was virtually inaccessible to ordinary people in the past, and as a result, the user layer is clearly expanding. There is a range of environments that enable users to utilize web content and services effortlessly. This has been spurred by factors such as improved usability of terminals. However, there is still no environment that will efficiently enable any user, no matter how much experience they have in using the web, to readily track down the content or web services that they want from among the huge volume of information. There is a difference in the information that can be acquired by people who can effectively combine suitable keywords that should be input to the search engine, for example, and those who cannot. Thus, a problem exists in which searching out necessary information from among the huge quantity of content and web servers depends on the skills and information technology (IT) literacy of the user. This article introduces a personal information style that is aimed at a user-centric information acquisition environment that is closer to the user than content providers and services. This personal information style provides content and services that are matched to factors such as the user’s profile, context, and the device environment. We implement an information acquisition environment that reduces the load on the user by bringing that information closer to the user rather than making the user get closer to the content and services, and that does not depend on skills or IT literacy. 2. ApproachTo implement a personal information style, a wedge method is first used to create associations between the user and the content (Fig. 1). Conventionally, the configuration is such that users actively search for their own preferred content and web services, and only the requested content is delivered to the device that made each request, as shown in Fig. 1(a). With the proposed approach, a wedge is inserted between the devices owned by the user and the content, as shown in Fig. 1(b). The wedge acts as a gateway when information on the Web is accessed from devices owned by the user, with the format being such that the wide variety of content on the web arrives in accordance with the user’s idiosyncrasies and the device environment. This gives rise to the following three benefits:
(1) Integrated provision of related content from other media sources: Up to now, content was provided from a single media source specified by the user. However, inserting this wedge makes it possible to integrate and provide related content that is thought to be of interest to the user, from other media sources. (2) Customization of design and interface for each user: The design and interface that has been customized for each user can be modified by interposing the wedge into a design that has been integrated in media units. Content that has been coordinated between devices owned by the user can also be presented by creating a mashup*1 of the devices. (3) No interference to service providers: The provision of content that is integrated with other media has no effect on the media provision interface on the service provider side since it is implemented on the wedge side.
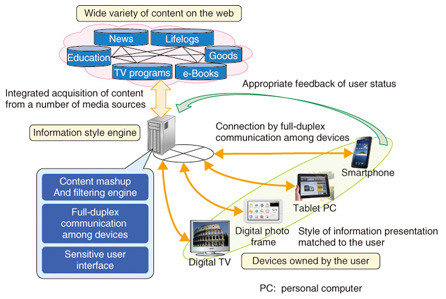
3. ArchitectureThe architecture for implementing the wedge method is shown in Fig. 2. The information style engine acts as a wedge to implement the wedge method. It has a content mashup and filtering engine, full-duplex communication functions between devices, and a sensitive user interface.
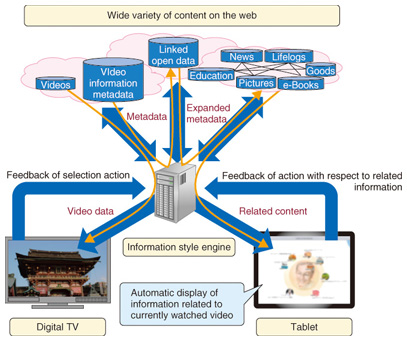
(1) Content mashup and filtering engine This engine acquires a mixture of content from a number of media sources, either based on the user’s actions or on the idiosyncrasies or devices owned by the user, and sends the results to the devices owned by the user. This makes it possible to create a mashup of web content and provide it to the user. (2) Full-duplex communication function between devices This function provides full-duplex communication to each of the devices owned by the user to enable data transfer between them. Connecting devices by full-duplex communication enables device cooperation (mashup between devices) so that an action taken by the user on one device acts as a trigger to automatically display content on a separate device. (3) Sensitive user interface This interface displays information in a way that is sensitive to the user’s direct actions and lifestyle, instead of in the one-sided manner of the past. This enables appropriate review of the content that should be included in the mashup and display of content that matches its status, by responding swiftly with respect to changes that occur on the user side. As described above, the wedge method performs a cycle of operations that include presenting the result of a content mashup depending on the user’s actions or changes in device states, obtaining feedback with respect to that result, and filtering the content on the web. 4. Use case of content recommendation coordinated with currently watched videoHere, we introduce a system that finds content that is related to a video the user is currently watching and displays it on a smartphone or tablet in front of the user, in coordination with the video, as an example use of personal information style. The user can get more information by utilizing this system. The information might consist of details of a restaurant that has been introduced in the video, or access to sites for purchasing the literary works of the performers or the accessories they are wearing, without actively searching for such information. This system is implemented in HTML5 (hypertext markup language, fifth revision), so we give details of the system and explain the advantages of using HTML5. 4.1 System overviewAn overview of the content recommendation system that is coordinated with the video that the user is currently watching is shown in Fig. 3. The user possesses a digital TV or tablet terminal, and full-duplex communication is enabled for this terminal through an information style engine server by the HTML5 WebSocket*2.
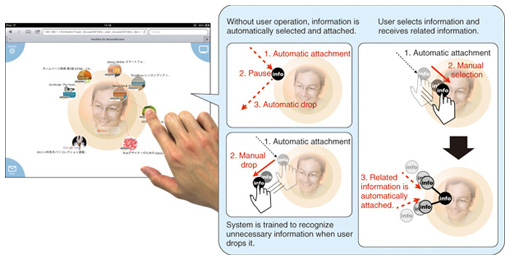
Using WebSocket reduces communication traffic and the load on the web server, in comparison with conventional full-duplex communication. The information style engine server can access various types of content on the Web and is configured to temporarily store the acquired content in the server itself. We describe this operation below. If the user selects a video on digital television (TV), information on that selection is transmitted to the information style engine server. The server acquires metadata containing pertinent video data and keywords related to that video from the web. The video data are transmitted to the digital TV, and replay is started. The acquired metadata are input as parameters to Linked Open Data (LOD)*3 applications such as DBpedia*4, and related keywords in the metadata are acquired from the LOD. Since the metadata will not always exist in sufficient quantity, going through the LOD will expand or bulk out the related keywords. The system uses the expanded metadata to search for content on the web and acquires content related to the video being watched. The acquired related content is displayed on the tablet terminal in front of the user, enabling the user to browse content that is related to the video being watched. The user’s actions with respect to the displayed related content are also fed back to the information style engine server. The system acquires new related content based on this feedback, and modifies the displayed related content to match the user’s actions. In addition, if the user changes the video he is watching, the system is designed to restart the above processing; then, content related to the new video footage will be displayed. 4.2 Content rejection/selection user interfaceAnother feature of the system is an interface that is swiftly responsive to the user’s actions. This interface operates the feedback cycle smoothly and displays or manipulates the related content. A display screen of this user interface is shown in Fig. 4. The image shows the method of manipulation and depicts how the display appears when related content is rejected or selected. Related content is displayed as icons on this user interface, more detailed information will appear when the user taps the icons. Content icons appear automatically as small animations that congregate from outside the screen into a central circle. These automatically disappear from the screen if the user does nothing, and icons for new content appear as similar animations. This display method ensures that the user need only act when wanting to know more details and reduces the pushiness that often exists with recommendation techniques. It is possible not only to tap content icons but also to drag-and-drop them. If an icon enters the central circle, information related to that content automatically gathers around the central circle from outside the screen. This enables the user to collect content of interest by simply moving promising icons into the circle, without having to input keywords. Conversely, the user can deliberately erase content by flicking the icon toward the outside of the screen. Since these actions are also fed back to the information style engine server, it is possible to easily inform the system which information is unwanted. In this manner, the user can readily search for content of interest through the simple actions of pulling in or flicking out the icons that continue to appear.
This user interface is also implemented in HTML5. Since the icons displayed in Fig. 4 are rectangular images when acquired from the web, they are trimmed into circles by using a Scalable Vector Graphics (SVG)*5 filtering function for display. The content icon display and animation are all defined as inline SVG*6, so it is possible to represent any display state as HTML tags. This enables coordination with different systems and interaction with other devices utilizing HTML tags, and will also provide expandability.
5. Future plansThe example of personal information style we described in this article involved interaction with digital TV, but personal information styles can also be applied in the presentation of related content using techniques such as digital signage or position information as the trigger, without using a TV. Note that the NTT Plala video delivery service of Hikari TV has provided a Nagarami Assist (assistance while watching) service that utilizes this technology since November 2012. However, at this point, the service can only cope with a limited number of contexts, and it has not yet reached the ideal form of the wedge method proposed in Fig. 1. We will therefore continue our research and development in the future, with the aim of implementing a service that is sensitive to a large variety of contexts such as the user’s idiosyncrasies, behavior, and preferences, and the environment and state of the devices, to provide the greatest user experience regardless of circumstances. |
|||||||||||||