|
|||||||||||||||||
|
|
|||||||||||||||||
|
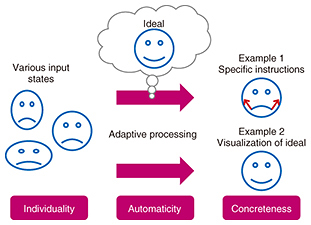
Feature Articles: Communication Science that Enables corevo®—Artificial Intelligence that Gets Closer to People Vol. 15, No. 11, pp. 13–18, Nov. 2017. https://doi.org/10.53829/ntr201711fa2 Generative Personal Assistance with Audio and Visual ExamplesAbstractThe rapid progress of deep learning is affecting the world we live in. Media generation (i.e., image and audio generation) is a typical example of this progress, and impressive research results are being reported around the world. In this article, we first overview this very active research field. Then we introduce our efforts in developing a generative personal assistance system with audio and visual examples. Specifically, we explain how our new deep-learning approach will overcome the limitations encountered in existing studies on personal assistance systems. Finally, we discuss future directions in the media generation field. Keywords: deep learning, media generation, personal assistance  1. Rapid progress in deep learningThe rapid progress achieved recently in deep learning is having an impact on the world we live in. Media generation (i.e., image and audio generation) is a typical example of this progress. Many studies are being done in this field, and amazing research results are being reported around the world. For example, StackGAN [1] can automatically synthesize photorealistic images only from a text description. Neural style transfer [2] can convert arbitrary images to arbitrary-style ones (e.g., Gogh-style or Monet-style images) without any manual processing. Until a few years ago, the main objective in deep learning was to improve accuracy for comparatively easily defined tasks such as image classification and speech recognition. However, more complex tasks have recently been tackled by introducing new models and theory. Also, a major breakthrough was recently achieved in the media generation field due to the emergence of deep generative models. Consequently, expectations for media generation are rising as a tool to embody various wishes. 2. Generative personal assistanceWhen we do new things (e.g., try to throw a ball faster, try to pronounce English more fluently, or try to acquire an appropriate facial expression according to the time, place, or occasion), it is sometimes difficult to know what the most effective methods for doing so are, and this can cause frustration. One conceivable solution is to find a teacher and have him or her teach us; another is to search via the Internet or books by oneself. The former approach is useful because it provides detailed instructions, but it is not always easy to find a suitable teacher. The latter approach is useful because it does not require help from anyone else, but it is not easy to find the optimal solution to fit the individual. To solve this problem, we aim to develop a generative personal assistance system as a means of learning new things. It is advantageous in that it offers individuality and concreteness provided in the former approach above, as well as automaticity provided in the latter approach. 3. Generative personal assistance with audio and visual examplesThe concept of our proposed generative personal assistance system providing audio and visual examples is illustrated in Fig. 1. We achieve individuality by analyzing the relevant data based on the data provided by the user (i.e., images and audio). We achieve concreteness by visualizing or auralizing the specific instructions or the ideal state. We achieve automaticity by ensuring the above process is conducted automatically.
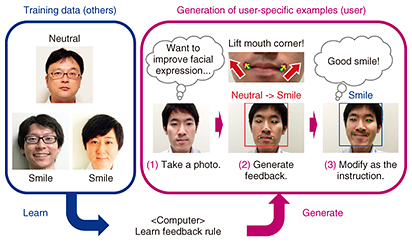
An operation example of the system [3] developed to provide visual feedback to someone who wants to improve their facial expression is shown in Fig. 2. In this system, we learn the feedback rule using the pre-prepared data. We assume that the data are collected not from the actual user but from the general public. Moreover, we assume that we can only collect one-shot data (i.e., one facial expression) for one person. This condition enables us to achieve automaticity without requiring a large data collection effort.
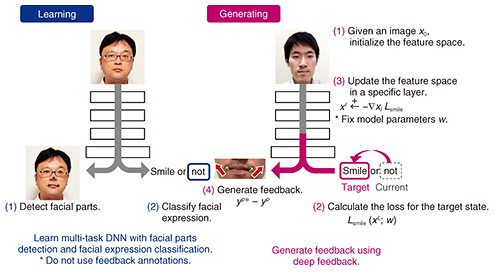
In generating feedback, we achieve individuality by analyzing and calculating feedback based on the user-provided image. We then display improvement guidelines with arrows. This feedback is concrete and interpretable, enabling the user to achieve the target state by following the instructions. This example targets facial expression improvement, but the same idea can be applied to other tasks (e.g., improving pitching in baseball or improving pronunciation). 4. Input variation and output concretenessTwo challenges need to be overcome in order to achieve this system. The first is how to apply it to various input data. This system is aimed for use by a diverse range of people with different ages, genders, and races. Therefore, it is necessary to adapt the system to provide the optimal feedback for each person. The main approach used in previous feedback systems is rule-based, in which the feedback rule is defined manually. This imposes a large rule-creation cost when there is a large amount of variation data. We propose to solve this problem by using a learning-based approach. The second challenge is not only to recognize the current state but also to generate detailed feedback based on it. Previous systems also used a learning-based approach that can be applied to various inputs, but they can only recognize the current state; for example, they can only classify facial expressions, estimate the degree of a smile, and detect the different parts of the face. It is not easy to extend this approach to generate feedback because the typical learning scheme requires the pair data of input and output, that is, the user image and correct feedback in this case. In general, feedback annotations require professional knowledge. Therefore, it is not easy to collect a large amount of data. This limitation makes it difficult to develop a feedback system using a learning-based approach. 5. Feedback generation with deep feedbackTo overcome these two challenges, we propose a new deep neural network (DNN)-based method that can learn and generate feedback without the annotations of correct feedback. The process flow of this method is shown in Fig. 3. In the learning step, we train a multitask DNN in facial parts detection and facial expression classification. This model also requires annotation data—that is, facial expression annotations and facial parts annotations—for training, but they are easier to collect than feedback annotation because they do not require professional knowledge. In the resulting model, the feature space has relevance to input images, facial parts, and facial expression classes that are key factors for generating feedback.
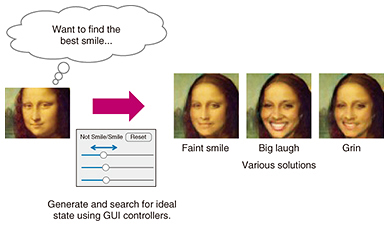
In the generating step, we apply a novel propagation method called deep feedback to extract the feedback information from the feature space. (1) Given an image, the system initializes the feature space and estimates the current position of facial parts and the facial expression class. (2) For the classification output, the system calculates the loss of the target state. (3) The system reduces this loss by optimizing the feature space in a specific layer using back-propagation. In the experiment, we found nonlinear transformation through deep back-propagation is useful for adapting feedback to various inputs. Note that in general training the model parameters are updated while fixing the feature space, but in the deep feedback process the feature space is updated while fixing the model parameters. (4) The optimal facial parts position is calculated based on the optimized feature space using forward propagation. Finally, arrows indicating the difference between the current and optimal facial parts position are displayed. 6. Interactive operations for generating and searching for ideal stateIn the above framework, an algorithm finds and visualizes only one solution for smiling, but there are actually various solutions for smiling (e.g., a grin, faint smile, or big laugh). In such a case, it is not easy for a computer to select and generate an optimal one without the user’s interaction. We were motivated by this to develop a novel system [4] where a user can generate and search for his/her ideal state interactively using typical GUI (graphical user interface) controllers such as radio buttons and slide bars. A conceptual image of this system is shown in Fig. 4.
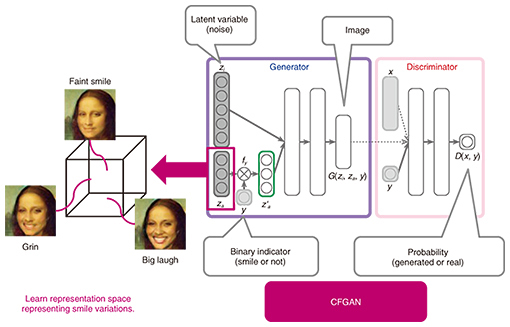
7. Representation learning using deep attribute controllerTo develop this system, we need to obtain a representation space that is disentangled, expressive, and controllable. First, attributes, for example, smiling, and identity need to be disentangled in the representation space in order to change the attributes independently from the identity. Second, the representation space needs to be expressive enough to represent the attribute variations. Third, controllability is important because our goal is to enable a user to intuitively control attributes. One of the challenges in learning such a representation space is to learn the space without a detailed description of attributes. This constraint is important because it is not easy to obtain a detailed description of attributes due to the complexity and difficulty in defining a rule for organizing them. To solve this problem, we propose a novel method called deep attribute controller to learn disentangled, expressive, and controllable representations only from the binary indicator representing the presence or absence of the attribute. In particular, we propose a conditional filtered generative adversarial network (CFGAN), which is an extension of the generative adversarial network (GAN) [5]. The GAN is a framework for training a generator and discriminator in an adversarial (min-max) process. The generator maps a noise to data space and is optimized to deceive the discriminator, while the discriminator is optimized to distinguish a generated and real sample and not to be deceived by the generator. The CFGAN incorporates a filtering architecture into the generator input, which associates an attribute binary indicator with a multidimensional latent variable, enabling the latent variations of the attribute to be represented. We also define the filtering architecture and training scheme considering controllability, enabling the attribute variations to be intuitively controlled. The CFGAN architecture is shown in Fig. 5.
The above explanation describes the case where the CFGAN is applied to learn smile variations, but the same scheme can be used to learn other attribute variations such as ages, hair styles, and genders. Moreover, it can be applied not only to images but also to audio data. For application to audio, we also developed some essential technologies consisting of realistic speech synthesis [6, 7] and realistic voice conversion [8] methods. 8. Future directionThe key objective of our approaches is to use media generation to develop an affinity with—that is, get close to—users. These technologies are essential for not only personal assistance but also for embodying users’ wishes through concrete media information. In the future, we aim to establish the technology to generate exceedingly high quality media to meet any expectation. To achieve this, we are working to cultivate the imagination, knowledge, and experience of media generation. References
|
|||||||||||||||||