|
|||||||||||||||
|
|
|||||||||||||||
|
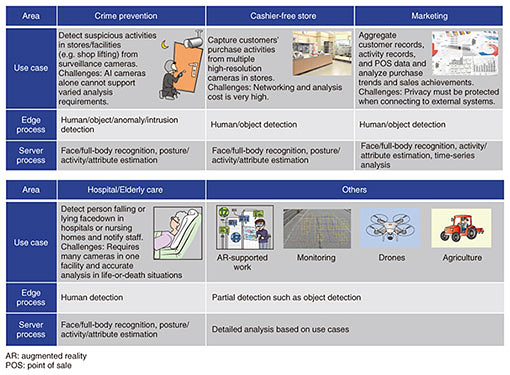
Feature Articles: Phygital-data-centric Computing for Data-driven Innovation in the Physical World Vol. 18, No. 1, pp. 15–21, Jan. 2020. https://doi.org/10.53829/ntr202001fa2 Carrier Cloud for Deep Learning to Enable Highly Efficient Inference Processing―R&D Technologies as a Source of Competitive Power in Company ActivitiesAbstractThis article introduces efficient inference technology as an important element in applying deep learning to business and an inference cloud service that is combined with NTT Group assets such as telephone exchange buildings and base stations. Keywords: cloud-based inference, regional edge, deep learning optimization  1. Solving social problems with deep learningIt has been almost eight years since the overwhelming win by Geoffrey Hinton and his group at the 2012 ImageNet Large Scale Visual Recognition Challenge (ILSVRC). As a result, various deep learning technologies are now being investigated worldwide. Past research on deep learning revealed that trials and proof of concept demonstrations were early topics. Today, however, there is now much discussion about solving social problems through deep learning. As a disruptive technology, deep learning is no longer a topic limited to researchers—it has become a technology for solving real social problems [1]. This trend began with use cases applying image recognition as a substitute for the human eye. Many use cases now include speech recognition and language processing. As a result, deep learning is on the road to becoming a commonly accepted technology. 2. Necessary element for accelerating the solving of social problemsAt NTT Software Innovation Center (SIC), we have developed critical technology for accelerating the solving of social problems ahead of the competition. Specifically, we have redefined the meaning of surveillance camera service by giving Takumi Eyes [2], a commercial surveillance service launched by NTT Communications in 2017, the capability of conducting real-time analysis of surveillance-camera video. In the past, such video simply served as material to be examined after the occurrence of an event to determine what happened before being handed over to a law enforcement agency. Needless to say, this ability to conduct real-time analysis of video has significantly broadened the range of social problems that can be solved (effective use cases). The managing of surveillance cameras in commercial facilities and office buildings is typical of the work conducted today by security businesses, but trials have been held on searching for elderly individuals suffering from dementia [3], a phenomenon expected to become a major problem as society ages in Japan. 3. Specific technologies enabling real-time video analysisReal-time surveillance camera service was achieved through the development of the following key technologies for achieving efficient inference processing in deep learning. (1) Technology for densification of inference tasks This technology includes the batch transfer of multiple inference tasks to a graphics processing unit (GPU), a close-packing processing method for parallelizing post-processing after inference,*1 and a stream-merge method for reducing GPU memory through batch processing of multiple data streams. The idea is to decrease the cost per task by multiplexing inference tasks in a high-density manner through a variety of patent-pending efficiency-enhancement technologies. (2) Lightweight filter technology for inference When analyzing stream data, of which video is one example, there are many cases in which the entire stream does not need to be analyzed due, for example, to the absence of individuals in certain segments of that video. However, processing without taking this into consideration means that computing resources will be monopolized even for video not requiring any analysis. This problem is solved by applying a lightweight filter that determines whether analysis is necessary according to the inference model being used so that only those locations that require analysis are targeted for inference processing. This technology reduces processing cost. (3) Server/edge distributed processing technology This technology makes it possible to use the same query language to describe server/edge linking without having to worry about the individual roles of edge devices, servers, or other components. For example, combining this technology with lightweight filter technology means that simple analysis tasks can be processed at the edge while more detailed analyses can be offloaded to servers, which reduces network and facility costs. At the same time, preprocessing conducted at the edge in this manner makes it possible to protect highly confidential information that should not be uploaded to an external server (Fig. 1).
(4) Deep-learning-model-optimization technology supporting heterogeneous devices This technology makes it possible to deploy a model that makes maximum use of the performances of individual devices by preparing an execution environment for multiple inference accelerators (CPUs (central processing units), GPUs, etc.) and making calls to these devices from a stream-processing engine. Combining this technology with a training-model compiler (such as NVIDIA TensorRTTM or Intel OpenVINOTM) can also improve capacity by conducting different types of optimization such as model compression and low-precision processing. (5) Technology for building inference microservices This technology enables dedicated processes that perform only inference processing to be built as inference microservices on separate servers. Combining this technology with server/edge distributed processing technology also makes it possible to uncouple computationally intensive inference processing from relatively powerless edge devices and to apply inference-task densification technology on the inference-microservice side where many inference tasks are concentrated. Combining all technologies described above improves capacity by more than ten times and enables real-time video analysis.
4. Service creation toward a golden era of deep learning and business scalingIn creating a commercial service, it is essential to compare the value that can be obtained from such a service with what must be paid for it (cost effectiveness) from the customer’s perspective. Regardless of whatever benefits a customer can receive from a service using deep learning technology, if the cost of just an inference infrastructure reaches about 100 million yen, it is very difficult for a mid-sized company to decide on whether to introduce such a service. In other words, the ability to inexpensively construct and use an infrastructure for an execution environment (inference environment) is key. In response to this need, the technologies introduced above for achieving real-time processing have come to the forefront. For a mid-sized company, the application of these technologies to enable efficient, real-time use of an inference environment can bring the cost effectiveness of using a deep-learning service up to a level commensurate with its benefits. For this reason, providing a service that enables efficient use of an inference environment on an inference cloud*2 to all types of customers at an appropriate price should enable NTT to gain a competitive edge over its competitors.
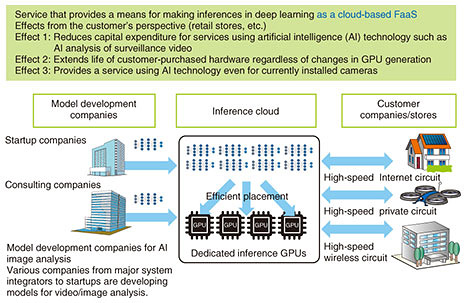
5. Carrier Cloud for Deep Learning—expanding from surveillance cameras to deep learningApplication of technologies for achieving an efficient inference environment described in section 3 is not limited to surveillance-video-analysis services. It can also be applied to nearly all services that use deep learning. The means of generalizing these technologies is called Carrier Cloud for Deep Learning (Fig. 2). Given expectations that models using deep learning and machine learning will increase in number and continue to be used in the years to come, Carrier Cloud for Deep Learning is an execution environment for running such models when they are put to commercial use [4].
At the same time, a framework conducive to these technologies is taking shape, as summarized below. (1) Acceleration of service development using deep learning We can expect even services that have so far been provided in the form of ordinary rule-based programs to be developed on a deep learning basis together as huge volumes of data are accumulated. For example, translation services based on deep learning are more powerful than rule-based forms of these services. This trend is expected to accelerate. (2) Unbundling of training (learning) and runtime (inference) It has been necessary to consistently use the same deep learning framework (TensorFlow, Caffe, etc.) from training to inference, but technical standards (such as ONNX: Open Neural Network Exchange) for exporting/importing previously trained models are progressing, making it easy to select the means of training and inference separately. (3) Development of many accelerators (semiconductors) for inference processing Only GPUs from NVIDIA were previously used for deep-learning purposes, but a variety of companies are developing and selling accelerators [5]. Regarding major companies, Intel provides the Nervana Neural Network Processor for Inference (NNP-I) and Myriad X, while Google provides Edge TPU. However, more than 100 companies including startups are now providing accelerators. 6. Regional carrier edge providing enhanced security and low latency for a more competitive inference cloudPlacing the Carrier Cloud for Deep Learning in regional NTT telephone exchange buildings and other NTT assets enables the provision of a low-cost, high-security, and low-latency service called regional carrier edge. What can be provided to customers through low-latency services? We introduce some use cases. The first use case relates to xR, which is the general term for the combination of virtual reality (VR), augmented reality (AR), and mixed reality (MR). The term VR sickness is well known. This is a phenomenon in which a user using a VR headset experiences nausea, drowsiness, or other disorientating effects when the processing speed lags, generating a delay. Regional carrier edge may be able to eliminate such VR sickness, so this may be one use case of a low-latency service. The second use case is cloud gaming. This is a service that runs a game at a datacenter and forwards screens and operations to a terminal. In cloud gaming, a large delay limits the extent to which a game can be played. While a game such as a puzzle can be played and enjoyed regardless of delay, a game with real-time characteristics cannot be played with a large delay. For example, if the user sees that a bullet is coming his/her way and operates the controller to avoid the bullet, a large delay would cause the bullet to hit the user before that operation information arrives at the datacenter. Technologies for constructing inference clouds with regional carrier edge in NTT telephone exchange buildings and between 5G (fifth-generation mobile communication) antenna and the Internet are being developed at SIC. Therefore, many services that can be provided thanks to low latency, such as quality inspection on factory production lines, will be provided in the future. 7. Wanted! Partners wanting a game changerThe inference cloud introduced in this article includes technologies that can be developed by other companies or using open source software, but on the whole, it is a world that presents a new challenge that no company has ever achieved. At SIC, we strongly believe that technology can change the world and are investigating game-changing technology regarding inference clouds. To this end, we are seeking partners to achieve such game-changing breakthroughs together. Some courage is probably needed to propose technologies with no established track record to customers. Proposing technology that a customer is not familiar with, managing a project, and delivering it on time are very difficult. With this in mind, our plan is to first provide such technologies to the NTT Group then conduct tests so that we can later include them in services we provide to customers. We would like to create such an environment together with our partners. References
Trademark notesAll brand, product, and company/organization names that appear in this article are trademarks or registered trademarks of their respective owners. |
|||||||||||||||