|
|||||||||||||||||
|
|
|||||||||||||||||
|
Feature Articles: Toward More Robust Networks Vol. 21, No. 12, pp. 27–32, Dec. 2023. https://doi.org/10.53829/ntr202312fa3 Network Reliability Design and Control Technology for Robust NetworksAbstractNTT Network Service Systems Laboratories is engaged in research on network design and control technologies for further strengthening networks against large-scale disasters and failures. As a countermeasure against large-scale disasters, we are conducting research and development to enhance the disaster and fault tolerance of transmission routes. As a countermeasure against large-scale failures, we are investigating robust control-plane architectures that can prevent prolonged and large-scale failures. We are also investigating technologies for improving user-level connectivity by linking information-access devices and the cloud. Three of these technologies are introduced in this article. Keywords: redundant design, signal control, multipath control  1. End-to-end reliability designTo provide stable network services to customers at all times, it is necessary to improve the reliability of the network from end-to-end. It is necessary to maintain and improve end-to-end reliability, which covers access, transport, and core networks as well as devices and cloud services (Fig. 1). NTT Network Service Systems Laboratories (NS Labs) has been researching technologies for evaluating network reliability during the design phase and for supporting network operation after launch of services. In some cases, telecommunication services have been unavailable for long periods due to the occurrence of large-scale disasters or network failures that have affected the use of services by a large number of customers. As a countermeasure against large-scale disasters, advanced design techniques are key factors in reducing the impact of such disasters by making networks redundant. As a countermeasure against large-scale failures, it is necessary to implement mechanisms, such as control functions, in the network to avoid events such as congestion. It is important to maintain and improve end-to-end reliability, including that of access networks, transmission networks, core networks, and even terminals and cloud services. Network design and control not only protects network services from disasters and failures but also provides flexibility needed to increase network service levels by securing resources in cooperation with functions and systems outside the network. As network design and control technologies to improve end-to-end reliability, designing network redundancy, strengthening the control plane, and assuring end-to-end communication robustness are introduced in this article.
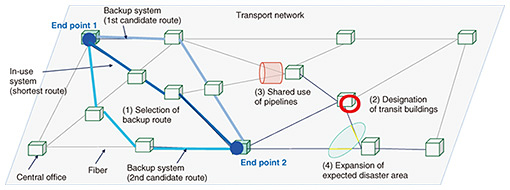
2. High network reliability through redundant route designAs networks continue to increase in speed, capacity, and latency, the requirements concerning reliability are becoming increasingly stringent. In particular, a transport network, which is the foundation of the whole network, accommodates a large number of users and services, so interruptions to services caused by failures can have a devastating impact. It is therefore important to ensure high reliability by implementing a combination of reliability measures such as equipment redundancy and decentralized arrangement [1]. Since transport networks can be damaged by external factors, such as disasters and failures, it is important to identify risk factors in advance and design physical routes that avoid those risks. It is also important to set up a backup route and—in case of emergency—use it as an alternative that maintains communications. While network redundancy usually minimizes the impact on services in the event of a failure, the disaster resilience of transmission routes depends on their length, shape, and geographic arrangement. In addition to the disaster resilience of each of the in-use and backup routes, it is important that either of the routes functions normally in the event of a disaster. To address these issues, NS Labs considered the following two requirements. The first requirement is that the in-use and backup routes must be highly fault-tolerant and disaster-resistant. For instance, a shorter route is less susceptible to disasters, and the probability of encountering a malfunction is lower when the route passes through fewer devices (Fig. 2(1)). In this case, it is important to reduce the distance and number of devices along the route. By preferentially selecting facilities constructed for disaster countermeasures, it is possible to design a highly disaster-resistant route (Fig. 2(2)). In this case, it is necessary to devise a procedure for selecting a route between the design target locations by specifying network facilities (such as central offices and links) to be routed or not routed. The second requirement is that the backup route must function properly in the event of a disaster or failure on the in-use route. For example, if two fiber routes are housed in the same pipeline, there is a risk of damage to both fibers in the event of a failure of the pipeline (Fig. 2(3)). A single failure can affect both routes, thereby posing a risk of interruption to services. As more network equipment is shared, the risk of service interruption becomes greater, and network redundancy becomes lower. The concept of a shared-risk link group (SRLG) is known as a state in which multiple network facilities share the same risk, and it is important to select routes in consideration of the risk of simultaneous failures of the in-use and backup routes. Even if the in-use route and the backup route are separate by some distance, if the expected area affected by a disaster (such as an earthquake or flooding) straddles both routes, both routes may be damaged in the event of a disaster (Fig. 2(4)). By defining a disaster or failure that affects multiple equipment and facilities simultaneously as a shared risk and assigning the same risk-group identifier (ID) to the facilities that share the risk, we have made it possible to search for routes that avoid the shared risk.
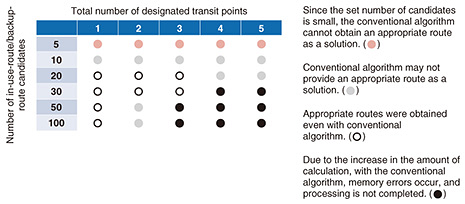
Many algorithms, such as Dijkstra’s algorithm, for finding the shortest route in a network are available. However, a route-search algorithm that satisfies the two above-mentioned requirements has not been considered. NS Labs therefore developed an algorithm for finding routes that satisfy the two requirements, and we verified it through simulation. To satisfy the first requirement, we developed a method that involves using the k-SPF (shortest-path first) algorithm, which is a heuristic-solution method that finds the number of routes (k) between specified destinations in order of ascending cost (length of route) [2]. To satisfy the second requirement, we then devised an algorithm for finding in-use and backup routes by assigning IDs to SRLGs such as pipelines and disaster-forecast areas and generating in-use and backup routes without duplicating those IDs [3]. In a previous study [4], it was not assumed that the search would specify a transit point or generate multiple in-use and backup routes between start and end points. We found that searching for a route that satisfies the two requirements by using the results of previous research would require a large amount of memory for computation owing to the huge amount of computation required. We also found that a candidate route that should be found by the search process may not be found if the amount of memory is insufficient. Therefore, applying our in-use-route/backup-route search algorithm, we divided the search sections into “start point to transit points,” “transit points to end point,” and “end point to transit points” and searched for routes from the start point to the transit points, from the transit points to the end point, and back to the start point in that order. This algorithm can reduce the search area by narrowing down the search targets so that the same route is not selected during the route-search process. Example results of comparing our algorithm and the conventional algorithm are shown in Table 1. The table shows the evaluation results for the optimal route for the total number of candidate routes and transit points specified for the in-use and backup routs. From these results, with the conventional algorithm, the amount of spatial calculation (i.e., amount of memory required for calculation) increases exponentially with the number of facilities; however, with our algorithm, it can be reduced to polynomial time, so it can be considered practical and effective. Our algorithm can reduce memory usage, so we expect it to be used in actual network-design phase.
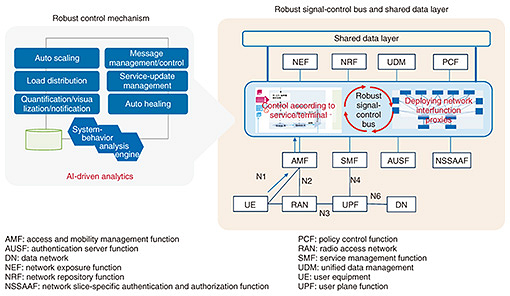
3. Toughening of control plane by signal-control busSeveral large-scale failures of telecommunications on mobile communication networks have occurred in Japan. There are three cited common causes and characteristics of such large-scale failures: (i) high load such as location-registration processing; (ii) failed control functions causing network congestion that spreads throughout the network; and (iii) problems such as data inconsistency that degrade database processing and increases recovery time. Several papers related to these issues have been published by the Institute of Electronics, Information and Communication Engineers (IEICE) [5]. At the 3rd Generation Partnership Project (3GPP) workshop held in June 2023 [6], the resilience of core networks was also raised concerning mobile communication networks, and future measures will be discussed by telecommunication carriers and vendors from now on. NS Labs has therefore been studying architectures aimed at toughening the control plane [7]. We are investigating implementing a robust signal-control bus composed of a group of network-control functions to manage and control the exchange of signals between network functions (Fig. 3). The signal-control bus has two characteristic features: (i) the control plane and user-data plane are separated and (ii) the control plane is based on a service-based architecture, which enables timely addition of functions in accordance with application characteristics and the development cycle of the application. We are also investigating a function to recover from performance degradation by automatically adding resources when user accesses become concentrated or processing load increases. Redundancy and automatic addition of resources to the control bus that connects functions can also avoid the effects of signal congestion and other problems. At 3GPP, a service communication proxy has been proposed as a function based on a similar concept. NS Labs is investigating a signaling-control scheme based on the type of service or terminal and the signaling load in the signaling-control bus as an additional feature to make the response more flexible when signaling congestion occurs. In the future, devices other than mobile communication devices will be connected to the network. We believe that controlling signals in accordance with the status of terminals and devices will help mitigate the effects of congestion by maintaining high-priority communication connections or reducing the amount of signals in the network in case of emergency.
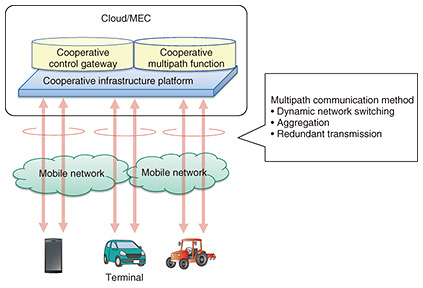
To detect failures and anomalies in the network and quickly mitigate their effects, the above-mentioned signal-control-bus architecture requires a mechanism to visualize the causes of failures and anomalies and enable quick predictive detection. For a mechanism for detecting service anomalies in the network, we are considering a function that uses probes to detect anomalies in each functional part of the network and notifies the signal-control mechanism when it detects an anomaly. We believe that such detection and notification of anomalies within the network and control of them in coordination with other functions will enable quicker response to failures. 4. Robust end-to-end communication through multipath control technologyIn addition to improving intra-network robustness, NS Labs is also working on multipath communication—which features increased end-to-end robustness—by using multiple networks between the terminal and the cloud/multi-access edge computing (MEC). Multipath communication is a form of communication that has multiple paths between terminals and servers in a manner that increases the robustness of the system. Using a combination of networks with different characteristics, such as mobile networks of different carriers or private fifth-generation mobile communication system (5G) and carrier 5G, makes it possible to minimize the impact of communication breakdowns due to a failure in one network, deterioration of radio-wave conditions, etc. by communicating via a normal network or a network with good radio-wave conditions. To improve the effect of robustness in multipath communication, a control technology that uses multiple networks is needed. Therefore, we are developing a cooperative infrastructure platform [8] for mission-critical services and investigating a cooperative multipath function as a multipath communication technology that connects terminals to the cloud and MEC (Fig. 4). The cooperative multipath function provides optimal multipath communication according to user and application requirements. Specifically, it provides three multipath communication methods: (1) dynamic network switching, which uses only a specific network under normal conditions and switches networks in the event of failure; (2) aggregation, which uses multiple networks simultaneously by sorting packets on a per-packet basis; and (3) redundant transmission, which sends copies of packets to multiple networks. These methods for improving robustness are effective, but they differ in terms of delay, bandwidth, and reliability. With method (1), network quality, such as delay and jitter, is expected to be stable because the same network continues to be used under normal conditions. Method (2) is expected to increase available bandwidth, although latency and jitter may fluctuate due to the use of different networks. Method (3) is less efficient in terms of bandwidth utilization because the same packet is sent multiple times; however, it is more tolerant of packet loss and is expected to reduce latency because the receiver can process packets that arrive first. The cooperative multipath function works with the cooperative control gateway, which executes cooperative control between the terminal and the cloud and MEC and provides appropriate multipath communication according to user and application requirements and network-communication conditions.
References
|
|||||||||||||||||