|
|||||||||||||||
|
|
|||||||||||||||
|
Global Standardization Activities Vol. 23, No. 7, pp. 43–47, July 2025. https://doi.org/10.53829/ntr202507gls Standardization of Codec for Immersive Voice and Audio Services (IVAS) at 3GPPAbstractThe 3rd Generation Partnership Project (3GPP) Service and System Aspects Working Group 4 (SA4) established the main specifications of the speech/audio coding standard: Immersive Voice and Audio Services (IVAS), in 2024 through a fully open collaboration by 11 organizations. IVAS is an extension of Enhanced Voice Services (EVS), which was established in 2014 and is widely used for smartphones worldwide. IVAS has signal-processing tools that support various multi-channel signal formats. During the development of the standard, NTT and Orange proposed an active downmix tool for stereo signals to enhance the quality of the compatible communications with EVS. Keywords: IVAS, EVS, downmixing  1. IntroductionThe 3rd Generation Partnership Project (3GPP) Service and System Aspects Working Group 4 (SA4) has established coding technologies for video and audio and related protocols. The audio subgroup has defined a new high-compression codec of speech and audio signals, suitable for real-time interactive communication with low delay constraints. Enhanced Voice Services (EVS) was established in 2014 through a global collaboration of 13 organizations, resulting in super-wideband, high-compression, low-delay, and high-quality speech/audio coding. Due to its efficient performance, EVS has been successfully deployed to the fourth-generation/fifth-generation (4G/5G) mobile telephone networks and used on almost all smartphones worldwide [1]. Although EVS greatly enhances the quality of monaural telecommunication, there is a potential need for various extended services that make use of multi-channel and multi-stream processing. A new standardization plan for Immersive Voice and Audio Services (IVAS) was initiated in 2018. A completely open collaboration scheme among 11 organizations (in alphabetical order: Dolby, Ericsson, FhG, Huawei, Nokia, NTT, Panasonic, Orange, Philips, Qualcomm, VoiceAge) has been carried out over 3GPP GitLab. In 2024, the main specifications and associated floating-point software were established. IVAS would be the first standard for real-time interactive communication, enabling immersive experiences. Note that there are more activities such as fixed-point implementations and subjective listening tests for characterization. 2. IVAS2.1 Application areas of IVASWe expect IVAS to have various application areas listed in Fig. 1. IVAS’s multi-channel and multi-stream functions allow for immersive representation of sound for real-time interactive communication. Some user devices, far beyond current smartphones, may support these application areas. Eyeglasses or goggle devices may be such immersive-communication tools with which users can share acoustic environments and experiences over networks.
2.2 Features of IVASIVAS is designed under the constraints shown in Fig. 2 and suitable for various applications of immersive communication. IVAS contains coding/decoding/rendering processing for various formats of multi-channel signals, such as stereo, binaural, channel-based, scene-based, object-based, metadata-assisted audio, and their combinations. IVAS has additional functions necessary for network transmission, including discontinuous transmission, packet-loss concealment, jitter-buffer management, and a set of associated protocols.
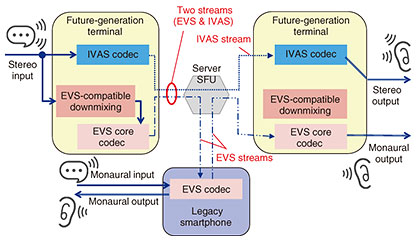
Although the International Organization for Standardization/International Electrotechnical Commission (ISO/IEC) Moving Picture Experts Group (MPEG) has established a standard codec for immersive communication, it is suitable only for one-way communication, such as streaming and broadcasting, due to a longer (around 100 ms) algorithmic delay. In contrast to MPEG, which defines only the syntax and decoder, IVAS has defined all specifications and ensures the quality between independent user devices. 2.3 Coding technologies of IVASFundamental compression-encoder processing consists of a spatial analysis part, which extracts spatial parameters of an audio signal, a downmix part, which reduces the number of channels of waveforms, and core coding of the waveforms for compression. The decoder retrieves waveforms and special parameters. The renderer creates the final waveform of the specified format, combining waveforms and special parameters. Detailed algorithm descriptions are highly complicated and fully described in the standard specification documents and associated software [2, 3]. 2.4 Compatible communication with EVSAmong the many new features of IVAS for multi-channel and multi-stream processing, retaining compatibility with EVS is important for communicating well with a huge number of legacy terminals. NTT and Orange have proposed an active downmix tool for converting signals from stereo to monaural to enhance the quality of the EVS codec without additional delay. An arbitrary downmix can generally be employed before the encoder, but this could cause additional delays and no guarantee of quality at the end of legacy terminals. On top of direct connections to legacy terminals, downmixing in an encoder can be helpful in a multi-party teleconference system, as shown in Fig. 3, where two IVAS terminals and one legacy terminal are connected by a select and forward unit (SFU). It is assumed that the IVAS encoder simultaneously produces stereo streams and a downmixed EVS-compatible stream. If we use the above teleconference system, we can maintain the quality of all terminals by making the SFU provide the appropriate stream to each terminal. These streams offer rich stereo sounds for IVAS-equipped terminals and clear monaural sound for a legacy smartphone without extra delay for all terminals.
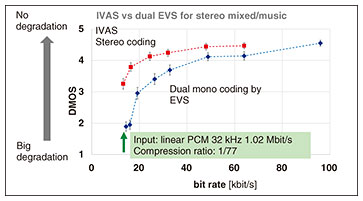
2.5 Active downmixThe simple downmix from stereo to monaural is a passive downmix, which produces only average values from two channels. This process may not provide the best quality for a monaural coder/decoder, depending on various conditions of sound sources and microphones. The active-downmix process, proposed by NTT and Orange, and finally specified in IVAS, has two modes that are adaptively switched according to the characteristics of input signals. One mode is simply an adaptively weighted sum of two channels, and the other has phase compensation before the weighted addition. For both cases, a bigger weight is applied for the preceding channel. 3. Quality evaluation3.1 Subjective quality of IVASSubjective evaluations by independent organizations are essential for deploying standard technologies to actual applications. For floating-point implementation, evaluation was carried out for various conditions (many languages, recording conditions, and formats), and the results have been analyzed and reported [4]. Only one example of these results for stereo signals of music or mixed signals is shown in Fig. 4, comparing the IVAS stereo coding with independent monaural EVS coding. The vertical axis shows the average and 95% confidential interval of scores in a five-point-scale differential mean opinion score (DMOS) (5: No impairment, 4: Small impairment, 3: Moderate impairment, 2: Large impairment, 1: Very large impairment) against the reference, considering both differences in the sound quality and in spatial representation. The horizontal axis shows the total bit rates. We can see that the IVAS stereo coding provided significantly better quality than the independent coding. Note that the lowest bit-rate coding consumed only 1/77 that of the original waveform in linear pulse code modulation.
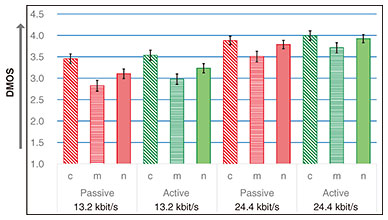
3.2 Subjective quality of downmixQuality-evaluation experiments were carried out at NTT, which involved comparing the standardized active downmix and passive downmix, as shown in Fig. 5. The vertical axis is also a five-point-scale DMOS, but we see the maximum scores saturated around 4 because the reference is always stereo, while the evaluated signals were always monaural. We used 90 input signals, which are categorized into clean speech, music, and noisy speech. The distance of stereo microphones varied from 5 to 200 cm, and the number of listeners was 24.
The results indicate that the active downmix provides significantly better quality than the passive downmix at 24.4 kbit/s for all categories and is significantly better for music signals at 13.2 kbit/s [5]. 4. Future perspectiveAs EVS has been widely used worldwide for telephone networks, IVAS is assumed to be used for IP (Internet protocol) Multimedia Subsystem (IMS), an international standard specifying IP telephone networks provided by telecommunication operators. However, it can also be helpful for various devices in combination with the best-effort network. The best-effort network is extremely flexible and easily available, but the connection quality may sometimes be poorer than that of IMS. It is not feasible to standardize all functionalities of applications in IMS. It would therefore be best to combine IMS for speech communication and the Internet for flexible and prompt extensions of various immersive services. To this end, activities are essential for defining interoperable protocols and application programming interfaces between WebRTC and IMS [6, 7]. 5. ConclusionWe introduced 3GPP IVAS standardization, focusing on downmixing to ensure a compatible connection to legacy smartphones on the basis of EVS. We expect IVAS to be widely used for various immersive or multi-stream communication services. References
|
|||||||||||||||