|
|
|
|
|
|
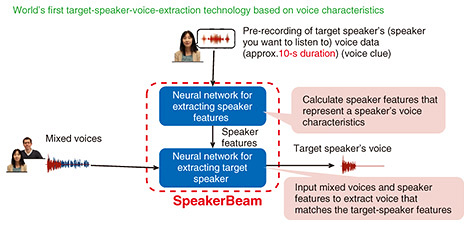
Rising Researchers Vol. 23, No. 8, pp. 13–17, Aug. 2025. https://doi.org/10.53829/ntr202508ri1  Using Neural Networks to Enable Computers to Listen to Voices Selectively as Humans DoAbstractWe live our lives surrounded by many sounds. People are capable of “selective listening,” which allows them to distinguish specific voices or sounds even when multiple people are speaking simultaneously; however, computers find selective listening difficult. If a computer could extract only desired voices or sounds, it would be possible to eliminate noise and enable the listener to hear, for example, only the sound of a doorbell or phone through headphones. This would help people working from home and those who need visual or hearing support. On this issue, we spoke with Marc Delcroix, a distinguished researcher at NTT Communication Science Laboratories, who has successfully developed technologies for extracting the voice of a desired speaker from voices of multiple speakers. Keywords: selective listening, SpeakerBeam, SoundBeam, neural network  Technology for extracting only a specific person’s voice from a conversation involving multiple people—Would you tell us about the type of research you are conducting? One of my major research themes is computational selective hearing, namely, extracting only specific sounds from multiple sounds. We humans gather information from sounds in various situations. We also sometimes speak to personal computers, smartphones, or voice recorders, record our speech, then transcribe it. My research group aims to develop technology that enables computers to understand and support human communication in natural conversations in a manner that goes beyond simply understanding what a single user is saying. We are frequently immersed in various sounds. Some of these sounds we want to hear, some we don’t need to hear, but all reach our ears. During an online meeting, for example, we may hear unnecessary sounds that we do not need to hear at that time, such as phones ringing, sirens sounding outside, dogs barking, and the sounds of family life. Normally we just want to hear the meeting audio. Even in these situations, we humans are basically able to focus on the people and sounds we want to hear and ignore the sounds that we do not need to hear. This ability is called “selective listening,” and I want to give computers this ability, so I am developing technology that can extract only the voice of a specific speaker when multiple people are talking. This technology can be combined with other technologies and applied to various use cases. For example, by combining it with speech-recognition technology, it becomes possible to extract only one person’s voice from among multiple speakers’ voices and transcribe only the words spoken by that person. For other use cases, we upgraded this technology to extract only the sounds one wants to hear, such as telephones ringing and dogs barking, in addition to human voices, from among many other sounds. We have been researching selective listening since around 2017 and succeeded in developing technologies for extracting the voice of a specific speaker from voices of multiple people on the basis of the speaker’s voice characteristics. For example, when extracting the voice of a specific speaker from audio data of two people talking, we first record the voice of the speaker to be heard (the target speaker) in advance and use a neural network to analyze and learn the target speaker’s voice features. A second neural network is then used to extract voices that match the voice features of the target speaker from data that contain a mixture of multiple voices. This technology is called “SpeakerBeam” (Fig. 1). It can be applied even when it is unclear how many people are speaking. In other words, even if three or more speakers, rather than just two, are speaking, it is possible to extract the voice of a specific person from the mixed voices.
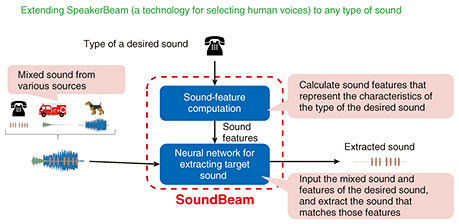
While SpeakerBeam can extract any type of voice with high accuracy on average, we found that its performance drops when the voices are similar; for example, when two women or two men are speaking together. It has evolved since we initially developed it, so its performance has improved to a certain extent in such cases. However, when the voices are similar it still has difficulty distinguishing them. For a solution to this problem, we proposed a multi-modal version that uses not only recorded audio data but also captured video showing lip movements as a clue to who is speaking. These improvements enable the technology to reliably extract the voice of the desired speaker even when similar voices are mixed. —What are the unique strengths of your research? My original research was on speech recognition, which involved adapting a speech-recognition system to the voice of a specific speaker to improve the performance of speech-to-text transcription. My research group consists of a speech-recognition team and speech-enhancement team (working on themes such as noise reduction and sound-source separation). I started new research with the idea that I might be able to extract the voice of a specific person by combining the speaker-adaptation technology I previously mentioned with neural-network technology for sound-source separation, and that combination led to the development of SpeakerBeam. I believe that it was only because people from different research fields joined forces to work in the same group that we were able to create this world’s first technology. SpeakerBeam is a versatile technology, and one of its strengths is that it can be used to extract not only a specific voice but also specific (non-speech) sounds. Using this strength, we also proposed a technology called “SoundBeam.” For example, if you are working from home and a siren is going off outside, the sound will become noise. On the contrary, when you are driving a car, sirens are an important sound that you must be able to hear. To achieve this optimal selective listening suited to the situation, we are teaching SoundBeam many sounds and expanding the types of sounds that it can handle; as a result, by simply inputting the command “I want to hear [a certain sound] in [a certain situation.]” into the computer, the desired sound will be rendered audible and other sounds will be muted (Fig. 2). I believe that if this technology can be implemented, it will have many applications such as customizing the noise-canceling functions of hearing devices, e.g., earphones, headphones, and hearing aids. It will also be possible to set car-audio systems so that the sounds of car horns and sirens are emphasized while music is playing in the car. The technology could also be used for sound post-production, e.g., to extract sounds to be emphasized during editing of the sound track of videos, etc. so that they become easier to hear.
Generally, SoundBeam can extract sounds with high accuracy as long as it can identify the type of sound; however, it can only extract the types of sounds that it has been trained with (“seen” during training). For example, if SoundBeam is trained with the sounds of dogs and cats, it can extract those sounds from audio data, but it cannot extract the roar of a lion, which it has not been trained with (“unseen”). In response to this limitation, we proposed a technology that enables SoundBeam to handle unseen-sound types, as well as the seen-sound types. This is a relatively new research field, and this technology has been under development for less than five years. I believe it still has room for improvement, so we are developing it further. SpeakerBeam and SoundBeam for comfortable listening in noisy environments—Would you tell us about the future prospects of this research? I hope this research will be useful in people’s daily lives. My goal is to make it possible to select important sounds from among a mixture of different sounds and clearly recognize the information expressed by those sounds. For example, the ability to hear a baby crying without the sound of the television or the ability to make one’s own voice heard more clearly on the phone or during video conferences can help eliminate people’s burden and make life more comfortable. Even in situations outside of everyday life, for example when talking to journalists, I often hear them say, “I wish that when recording various conversations or lectures with a voice recorder, I could precisely extract only the voices of the people I want to hear.” Many artificial-intelligence technologies, such as automatic speech recognition or machine translation, have been developed and are improving day by day; however, when they are used in a noisy environment, their translation accuracy inevitably decreases. Naturally, the performance of each technology is improving, but while it is easy to distinguish between noise and human voices, the characteristics of multiple voices differ from those of background noise, so it is not always easy for current speech-recognition or machine-translation technologies to distinguish the sound of the target speaker from multiple voices. However, I believe that if the technologies we are researching can be used effectively, they could be applied in a variety of ways, such as making it possible to hear clearly and translate the target party’s voice correctly (even when using machine translation in a noisy place) or to distinguish who said what in a meeting accurately and create minutes of the meeting. We are striving to improve the accuracy of voice extraction while considering how to make voice-extraction technology useful to a wide range of people in the many situations in which they hear sounds. —What are the challenges and key points in your research? What issues remain to be solved? When I began researching this technology, it was important to establish the basic theory first. We then demonstrated our voice-extraction technology at the NTT Communication Science Laboratories Open House in 2018. We thus demonstrated that the technology works not only in theory but also in a real environment with many visitors and much noise. However, several issues remain, and as I explained earlier, it will be necessary to increase the types of sounds that can be handled in the future. We already know that it is possible to satisfy that necessity to a certain extent, but I believe that to improve accuracy and performance of the technology, it must be possible to learn many more types of sounds, and that attaining that possibility is one of our future challenges. Another issue is the recording environment. It is necessary to anticipate dynamic changes in the environment such as a quiet place, very noisy place, or place where unusual sounds are produced. Unless the technology works properly in a variety of recording environments, not just in experimental environments, it cannot be put to practical use. For that reason, I am pursuing research with the consideration of the need to change processing automatically according to the recording environment. For example, certain sounds can be expected to be heard at home, while different sounds can be expected to be heard in the office; accordingly, to handle both situations, we need to develop technology that can specify the type of sound environment in addition to the type of sound to be heard. We are not yet satisfied with the quality of voice extraction and are aiming to extract higher quality, more realistic voices. We envision earphones and hearing aids as devices using voice extraction; however, when our technology is implemented in small devices that are worn in the ear, reducing the size of the neural network becomes essential. Although the performance of neural networks has improved, the computing power of small devices is limited, so we need to improve the technology so that it can maintain high accuracy even on small devices. —Finally, what is your message to young researchers and students? Research has various phases, from theoretical considerations to verification with a real system. For SpeakerBeam and SoundBeam, I was involved in both creating the theory and developing the demonstration systems. I was happy to have created a theory for voice extraction, but I was especially pleased to see that it worked as predicted in a real environment. Research thus enables you to contribute to the world in many different ways, from theory to practice, and you can experience a sense of accomplishment in either. I have also had the opportunity to conduct research with many people, including colleagues and interns at NTT laboratories, and joint research with multiple universities. For example, SpeakerBeam was developed in collaboration with Brno University of Technology, Czech Republic. I am currently conducting joint research with universities in Germany, the United States, and other countries. In addition to cooperating with overseas universities, NTT has a variety of research laboratories, and several deal with speech and audio processing research, so we work closely together with them on several projects. NTT laboratories have high implementation capabilities, and the support of the laboratories made it possible to handle the above-mentioned Open House demonstration. I feel that I am in a very fortunate environment in which I can conduct research with highly capable researchers who excel in both research and development. Another feature of NTT is that it enables you to pursue your research in a global environment, even within Japan. Our group conducts research activities globally, host many outstanding interns from overseas, and have several internationally renowned and gifted researchers on our staff. I think these circumstances are amazing. Many people think that researchers conduct their research alone. This can be true depending on the person, but others succeed by talking to many people and coming up with good ideas as they pursue their research. I encourage young researchers and students to talk to as many people as possible when they have a problem instead of keeping it to themselves and to enjoy their research.
■Interviewee profileMarc Delcroix received an M.Eng. from the Free University of Brussels, Belgium, and the Ecole Centrale Paris, France, in 2003 and Ph.D. from the Graduate School of Information Science and Technology, Hokkaido University in 2007. After joining NTT in 2010, he has been researching speech and acoustic signal processing, including speech enhancement, speech recognition, and target-speech extraction. He is a member of the Institute of Electrical and Electronics Engineers (IEEE) and the Acoustical Society of Japan. |