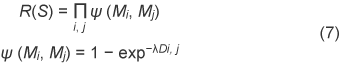|
|||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||
       |
Vol. 5, No. 11, pp. 17–24, Nov. 2007. https://doi.org/10.53829/ntr200711sf3 3D Human Tracking for Visual MonitoringAbstractIn this article, we introduce a three-dimensional (3D) human tracking system for visual monitoring. It tracks human movement in three dimensions with high accuracy. A 3D environmental model that replicates the 3D structure of the real world is introduced to handle cases in which some objects obstruct the camera's view, i.e., occlusions. Experiments show that our system can stably track multiple humans who interact with each other and enter and leave the monitored area. This system is expected to be useful not only for surveillance but also for collecting marketing data. 
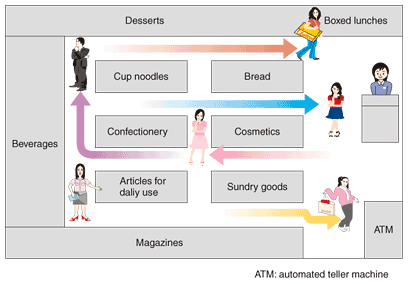
1. IntroductionThere is a lot of interest in visual monitoring systems to ease growing public fears. Tracking humans is one of the most critical aspects of visual monitoring because the movements of humans correlate well with human behavior. A human tracking system is expected to be useful not only for surveillance but also for collecting marketing data (Fig. 1).
One major problem for a practical three-dimensional (3D) tracking system is that other objects in the environment can obstruct the camera's view of the target. This phenomenon is known as occlusion. In practice, any tracking system should be robust when there are: (1) mutual occlusions caused by interacting targets, (2) occlusions caused by fixed objects in the environment, and (3) variable targets to be tracked representing entry to and departure from the monitored area. Many methods of tracking targets on a two-dimensional (2D) image plane in these situations have been proposed. Methods of stably tracking multiple targets in the presence of occlusions caused by fixed objects in the scene and mutual occlusions have been reported [1], [2]. To track variable interacting targets, the MCMC (Markov chain Monte Carlo) particle filter has been used [3]–[5]. Compared with the 2D approach, the 3D approach is more effective in accurately estimating position in space and is more effective for handling the above-mentioned situations. However, few studies have attempted to utilize a 3D approach. 3D position has been estimated by integrating the tracking results on a 2D ground plane from multiple stereo camera modules [6], [7]. Unfortunately, if the tracking result from one stereo camera module is false, the whole system becomes unstable. 3D positions of humans in very cluttered environments have been tracked using multiple cameras located far from each other [8], [9]. However, in those studies, an ideal environment with no objects other than humans was assumed because the approaches were based on volume intersection. The problems with the above methods mainly arise from the difficulty of solving the inverse problem (reconstructing 3D information from 2D images). To tackle the inverse problem, a method of tracking humans by directly predicting their 3D positions in a 3D environment model and evaluating the predictions using 2D images from multiple cameras was investigated [10]. This approach avoids the inverse problem because 3D information is not explicitly reconstructed. However, the computation cost is very high because multiple humans must be tracked by using several single-object trackers in parallel. In this article, we present a new approach to the stable tracking of variable interacting targets in the presence of severe occlusions in 3D space. We formulate the state of multiple targets as the union state space of all the targets and recursively estimate the multibody configuration and the position of each target in the 3D space by using the framework of trans-dimensional MCMC [11]. In surveillance applications, environmental information is very useful because surveillance cameras are stationary in the environment. This article is organized as follows: Section 2 introduces the 3D environment model and its application to tracking, Section 3 describes our tracking algorithm. Section 4 describes our experiments and presents our conclusions. Future work is mentioned in Section 5. 2. Our 3D environmental modelOur approach is to construct a 3D environment model that replicates the real-world's 3D structure in advance of tracking. We use this 3D environment model to handle occlusions caused by fixed objects in environment. We also define the entry and departure areas in the 3D environment model to enable reliable estimation of the number of targets in the monitored area because the areas through which people enter or leave are definitely fixed in the environment. If we know about such areas, we can suppress needless predictions of the appearance and disappearance of humans. We construct a 3D environmental model that replicates the real-world's 3D structure from the image sequences captured by all the cameras in the environment. We capture an image sequence and move the viewpoint to the position used in the tracking process. We use the combination of a factorization method and multiview stereo [12] to reconstruct dense 3D points. A typical image sequence is shown in Fig. 2.
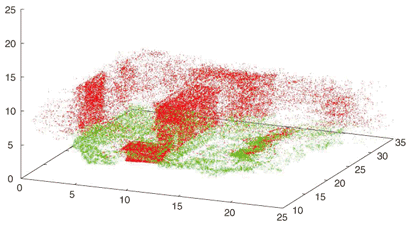
After reconstructing the 3D points from all the cameras, we integrate all 3D points in world coordinates and detect the ground plane as the plane with the largest area by applying the 3D Hough transform [13]; the 3D points are converted so that the X-Y plane lies on the ground. This allows us to use 2D coordinate values (x, y) to express the 3D positions of humans because human motion is strongly restricted to the 2D ground plane. A typical set of integrated 3D points is shown in Fig. 3.
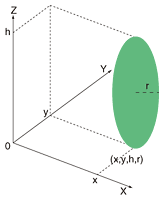
Finally, the 3D surface is approximated by a triangular mesh; depending on the environment, we can set the entrance and departure areas manually. 3. Tracking with the 3D environmental modelIn this section, we introduce a multiple human tracking method with a 3D environmental model. Tracking means the sequential estimation of the state of multiple humans St; it represents the 3D position of humans in the 3D environmental model at time t. State St is estimated by directly predicting the 3D position of humans in the 3D environmental model and the predictions are validated by using 2D images from multiple cameras. In addition, we can restrict the predictions of the positions of humans because the 3D environmental model replicates the real-world's 3D structure and we are aware of the entrance and departure areas and of occlusions caused by fixed objects in the environment. 3.1 Handling multiple humansWe track humans using a 3D model that represents the human body as an ellipsoid. The state of human i is represented as a 4D vector Mi = (xi, yi, hi, ri), where (xi, yi) is the position on the 2D ground plane and (hi, ri) give the ellipsoid's height and radius (this allows us to handle shape differences between individuals), as shown in Fig. 4.
The state of multiple humans is defined as the union state space of all the humans. Consider a system tracking K people in the t-th image frame. St is represented as the 4K-dimensional vector St = (M1, M2, …, MK). 3.2 MCMC-based tracking algorithmThe number of dimensions of the state space estimates varies with the number of humans being tracked. To deal with this trans-dimensional state space, we use an estimation algorithm based on trans-dimensional MCMC [11]. First, in each time step, we compute the initial state of the Markov chain at time t using the state of previous time St−1 according to the motion model. After initialization, we generate B + P new samples by changing the current state depending on a random selection of move type (MCMC sampling step) to obtain P samples because the first B samples are assumed to vary widely. We use four move types: entry of the target into the space, departure of the target, update of the target's position, and update of the target's shape. We decide to accept or reject a new sample as a new state by computing the likelihood of the new sample. After B + P iterations, we compute state St as the maximum a posteriori (MAP) state using samples generated using the last P samples. The flow of our MCMC-based tracking algorithm is given below. (1) Initialize the MCMC sampler (2) Perform MCMC sampling a) Select the move type randomly and generate a new sample b) Compute the likelihood of the new sample c) Decide whether to accept or reject the new sample by computing the acceptance ratio (3) Estimate the MAP (1) MCMC sampler initialization: We initialize the MCMC sampler at time t using the state of previous time St−1 according to the motion model, for which we use simple linear prediction. The initial state of the Markov chain at time t (2) Move type: We use the following move types to traverse the union state space: 1) Target Addition (entry of a new target) 2) Target Removal (departure of the target) 3) Position Update (update of the target's position) 4) Shape Update (update of the target's shape) In each iteration, one of the above move types is selected randomly. If the present state a) Target Addition: A new human state Mn is added to the present state b) Target Removal: A selected human state Mi is removed from the present state c) Position Update: The position parameters (xi, yi) of randomly selected human state Mi are updated by d) Shape Update: The shape parameters (hi, ri) in randomly selected human state Mi are updated by 3) Likelihood of the state: The state is simulated by using 3D models of humans and the environment. We capture this scene using virtual cameras that have the same camera parameters as real cameras. The likelihood of the state is computed by comparing the real camera image with the corresponding virtual camera image. We can predict how the target will be occluded by objects in the environment because we use a full 3D model that includes the targets and the environment. A real camera image, background subtracted image, virtual camera image, and ellipsoid detection image are shown in Fig. 5.
We compare the background-subtracted image with the ellipsoid detection image using
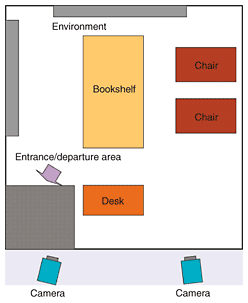
In addition, we introduce the following penalty functions using 3D information. a) Penalty based on position in the environment: The probability that humans are floating above the floor is low, so we define penalty function E (S) based on the position in the environment as b) Penalty based on relative distance among targets: Since multiple humans cannot occupy the same position, we define penalty function R (S) based on the relative distance among targets as Finally, likelihood L is computed by 4) Acceptance ratio: We decide whether to accept or reject the state by using acceptance ratio a, which is given by 5) MAP estimation: After repeating sampling B + P times, we compute state St by We use only the last P samples to compute state St because the first B samples are assumed to vary widely and include different target configurations. 4. Experiment4.1 System and conditionsOur system consisted of a personal computer (CPU: AMD Athlon 64 × 2 4800+) and two color CCD cameras (FLEA made by Point Grey Research). Each captured image had a resolution of 640 × 480. The intrinsic and extrinsic camera parameters were estimated in advance. In this experiment, the number of iterations B + P was set to 300. For MAP estimation, we use the last P=100 samples. The system ran at 5 frames per second in this non-optimized implementation. The images from the cameras are shown in Fig. 6 and a bird's eye view of the experimental environment is shown in Fig. 7. We defined the shaded region in Fig. 7 as the entrance/departure area.
4.2 Multiple human trackingTo evaluate the basic tracking performance of our system, we used an image sequence in which three humans entered and left the monitored area at different times (sequence #1). The images selected from the monitoring results of sequence #1 are shown in Fig. 8. Our system could correctly capture the movements of the three humans. In the 268th frame, most of one subject's body was occluded by a shelf, and in the 305th frame, two humans completely overlapped. Even under these severe occlusions, the tracking error was not significant as a result of our use of the entrance/departure area constraint.
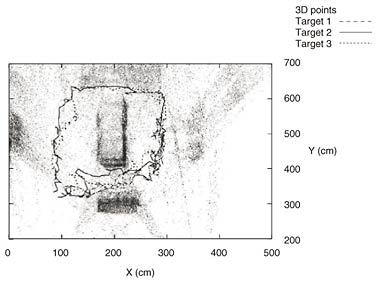
The trajectories on the X-Y plane overlaid by reconstructed 3D points are shown in Fig. 9. The continuation of trajectories even in the case of severe occlusions caused by fixed objects in the environment and mutual occlusions demonstrates the robustness of our system to occlusions.
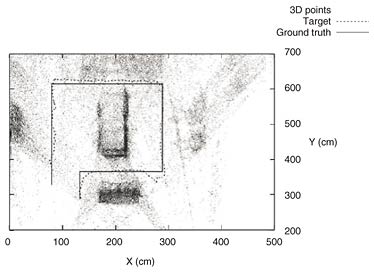
4.3 Evaluation of the tracked positionFor a rough evaluation of the position tracked by the system, we used an image sequence in which a subject walked around a prearranged route (sequence #2). We compared the estimated motion trajectory with the actual trajectory on the ground (ground truth trajectory). The estimated motion trajectory and the ground truth trajectory on the X-Y plane overlaid by 3D points are shown in Fig. 10. The estimated and ground truth trajectories are very close, so this result confirms that our system offers high accuracy. The mean and maximum errors of the estimated distance were 4.86 and 29.43 cm, respectively.
5. Conclusions and future workIn this article, we introduced a 3D human tracking system that can track variable interacting targets in the presence of severe occlusions caused by both fixed objects in the environment and target movement. The next step is to extend the system to cope with crowded scenes, which we expect to be fairly difficult. Evaluations of such systems should lead to a better system design in terms of factors such as camera locations. References
|
||||||||||||||||||||||||||||||||||||||

 t,0 is computed by
t,0 is computed by