|
|||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||
       |
Letters Vol. 6, No. 4, pp. 22–27, Apr. 2008. https://doi.org/10.53829/ntr200804le1 Provision of Services According to Individual User Preferences over a Cross-section of Sites Implemented with “Personalized-service Platform”AbstractThis article describes the personalized-service platform that we are developing for next-generation network services. It can provide a cross-section of information and services selected from a large amount of data according to users' preferences and regardless of the type of service. It frees users from the need to actively perform any particular operations, such as entering preferences, and lets them passively receive services that are compatible with their preferences from a large body of information. The key technique for achieving this is user profiling. 
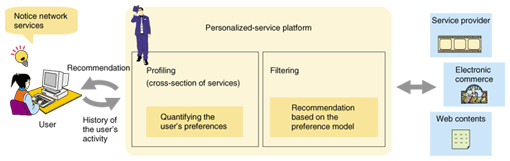
1. Personalization technology required for NGNsAs next-generation networks (NGNs) become widespread, people who have never used conventional network services will have much more opportunity to use network services in the near future. These services will be more convenient for users, allowing them to share photographs and other data from their homes easily, plan a holiday without going to a travel agent, and do their shopping and many other activities. However, in order to enjoy this new convenience, users must know what sorts of network services are available and where the information they want can be found. The main method for finding available services and information is to search using keywords, so in order to procure the desired services or information, one must first perform an appropriate search. However, users who have no experience with conventional networks and are not familiar with this sort of procedure will find it difficult to retrieve the required information from the vast amount of information available by selecting appropriate keywords. Furthermore, users may not even have a good understanding of the sorts of benefits available, so it will be difficult for them to take the first step of actively searching for the services they need. To support users of these types, there is an increasing need for personalized services that can present information compatible with the user's preferences from the system side, without the need for users to actively enter any particular information. We have proposed a personalized-service platform as a technical element required for the distribution of personalized information in NGNs [1]. It performs user profiling by using the history of the user's activity to quantify the user's preferences. Using this profile, the technology provides a scheme that helps users use network services passively, with minimal user input, by helping them notice network services that might interest them (Fig. 1).
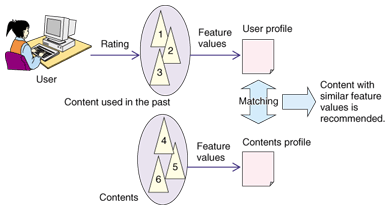
From the service-provider perspective, this technology may provide a way to reach latent users who are not using the network yet, so it could help expand businesses. Personalization is a basic service that provides benefits to both users and service providers. 2. Issues with existing personalized service technologiesExisting network services operate under the assumption that users will actively perform operations such as entering keywords to search for the services. However, the users targeted for the proliferation of NGNs will include so-called mass users who have no experience with conventional networks, such as the elderly. It is not practical to require them to actively perform any particular operations, so a scheme that allows more passive access to services should be effective. One way to let users use services more passively is for the system to make recommendations that match the user's preferences based on the history of the user's activity. Information about the user's preferences is first extracted from the activity history and used to build a preference model. This is called profiling. Then, recommendations are selected using the preference model extracted during profiling. This is called filtering. Existing recommendation methods can be broadly divided into two types: content-based filtering and collaborative filtering [2]. 2.1 Content-based filteringContent-based filtering performs profiling by extracting feature values (vectors expressing interests by, for example, applying weights to keywords) from content used in the past and recommending content with similar feature values (Fig. 2). These methods assume that metadata, such as keywords or genre data, will be provided with the content. This metadata is generally in the form of text, but there are also services that encode and make use of other data to perform filtering, such as Pandora [3], which uses music tempo and frequency components for filtering.
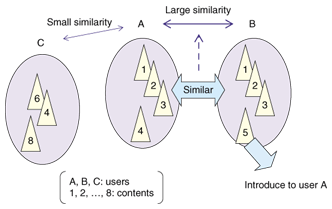
This method enables the system to make highly precise recommendations of content that is similar to content used earlier by the user. However, because the profiling makes use of metadata, only services that specify compatible metadata can be used, so it is difficult to provide recommendations over a cross-section of services. The method also has difficulty making serendipitous recommendations, which is a drawback. Another issue is the amount of processing required because the vectors must be recomputed every time the user accesses content. Consequently, the use of Bayesian nets for high-speed processing of recommendations has received a lot of attention recently, but the amount of time required for learning is still an issue. 2.2 Collaborative filteringIn collaborative filtering, a profile is created by evaluating content used by the user in the past, and recommendations are made by evaluating users with similar profiles, and hence similar interests (Fig. 3). The content itself is not used for profiling, so a recommendation service can be provided without preparing metadata. This method can also provide a larger number of serendipitous recommendations, so it is currently the most commonly used. A well-known example of this approach is the “Customers who bought this item also bought…” section [4] displayed on Amazon product pages [5].
Computation for this method increases exponentially as the number of users and the number of content items increases, so it is difficult to apply on a large scale. Moreover, unless a record of service-use across multiple services is available, comprehensive recommendations cannot be given. 3. The key to personalized services: profilingTo implement personalized services on NGNs, it will be necessary to provide services over a cross-section of sites within a large-scale environment. However, existing methods are difficult to implement because they (1) have difficulty providing a cross-section of services, (2) do not scale well due to the amount of processing required, and (3) place a great burden on service providers and end users in terms of the need to maintain metadata or enter evaluation criteria. Thus, the key to personalized services is to develop profiling technology that satisfies the following conditions:
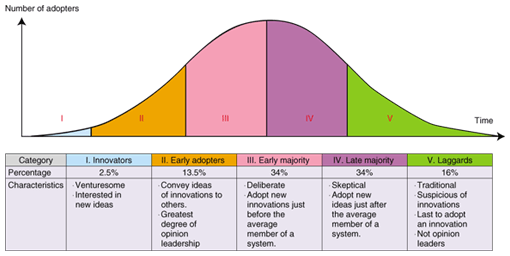
As a method that satisfies these requirements, we are studying a recommendation technology that takes into consideration the innovation characteristic. It extracts user preferences by focusing on the time frame in which a user adopts new products. 3.1 Profiling based on innovation characteristicInnovation characteristic is a user characteristic first described by E. M. Rogers in 1962. According to Rogers, a product diffuses in five steps, as shown in Fig. 4, and he classified users into five corresponding categories: innovators, early adopters, early majority, late majority, and laggards [6]. The elapsed time from product launch to when a user adopts the new product differs depending on this characteristic. For example, there are differences in timing, depending on the person, for purchases of new mobile phones: some people always buy a new handset as soon as it is released, while others wait to see whether it gets good reviews, and so on. A system that provides recommendations that take into account users' innovation characteristics can present information to users at the optimum time. This should have a positive effect on the rate of positive reaction to the recommendation. Moreover, recommending new products to the early adopters, who are opinion leaders, could stimulate word-of-mouth promotion. We have devised a method that automatically estimates a user's innovation characteristic.
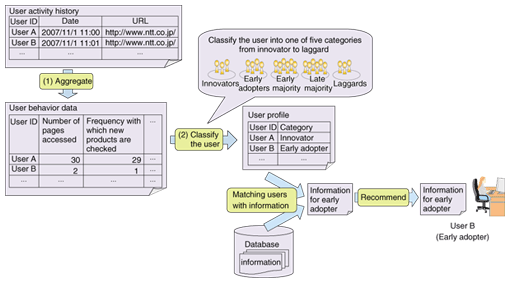
3.2 Method for estimating innovation characteristicTraditionally, users' innovation characteristics were estimated by asking users to answer several questions about their values and classifying the users into five categories on the basis of their answers. However, it is difficult to force a user to answer several questions in order to receive recommendation service. So, we focused on the differences among users in each category in terms of: (1) socio-economic position, (2) personality, and (3) communication behavior [6]. We have devised a method that automatically estimates the category of a user by simply accumulating user behavior data about these three characteristics for a given period of time. As described below, users are classified without entering additional user information. First, behavior data to be used in the estimation is aggregated from the user activity history (Fig. 5). As behavior data, we use data such as the number of pages accessed and the frequency with which new products are checked. These are related to (3) above. Next, we classify the user into one of the five categories from innovator to laggard by substituting this data into a classification formula that we have developed). On the basis of this classification, we then make recommendations that match information and users. We have confirmed that our method is effective by verifying it with users of several different services.
In future, we will study methods for making recommendations based on even less behavior data to make them easier to apply to real services and also verify their effectiveness for a wider variety of services so that recommendations can be made across a real cross-section of services. 4. ConclusionWe described a profiling technology that uses the innovation characteristic and is one of the technical elements required to build personalized-service-based technology. To implement personalized services, in addition to this profiling technology, we need a complementary profiling element for users who cannot be classified on the basis of their innovation characteristic. We also plan to evaluate the computing resources required to profile in this way to determine its applicability to large-scale environments. We are also making quantitative and qualitative evaluations of this profiling algorithm by implementing an evaluation service and performing evaluation experiments. References
|
||||||||||||||||||||||||||||