|
|||||||||||||||||
|
|
|||||||||||||||||
       |
Letters Vol. 6, No. 7, pp. 33–38, July 2008. https://doi.org/10.53829/ntr200807le1 “Know Who” System Using iMage (Information Mixable Graph Explorer)AbstractOur next-generation Web information sharing engine called iMage (information mixable graph explorer) supports the discovery of new knowledge or information by integrating and analyzing resource description framework (RDF) data extracted from various data sources. We applied it to the “Know Who” system in a joint experiment and got excellent results. 
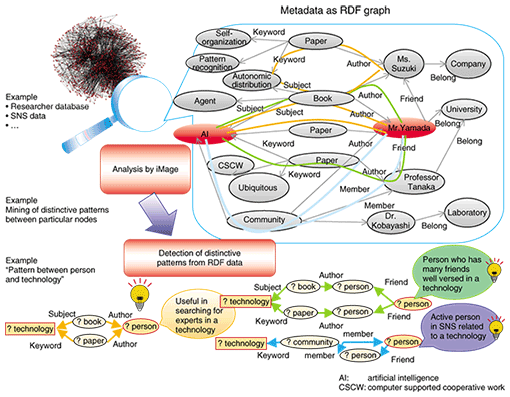
1. Expanding the Semantic WebThe Semantic Web, which is advocated by Tim Berners-Lee, is a project that aims to improve the convenience of the World Wide Web (WWW) by using metadata (e.g., creator, date, and keywords) or meaning given to web pages. At first, people were skeptical about the Semantic Web becoming popular because of its constraint—somebody must add metadata to web pages. However, recently a lot of metadata has been added automatically to contents in social networking services (SNSs) or blog (weblog) services, and users are starting to add tags to their contents. Therefore, the basis for the spread of Semantic Web is ready now. For example, automatic article distribution by RSS (rich site summary) is a kind of Semantic Web service. We are developing iMage (information mixable graph explorer) [1], which extracts and discovers new knowledge or information by using metadata used in the Semantic Web. 2. iMageThe resource description framework (RDF) [2] is the W3C (World Wide Web Consortium) standard for encoding metadata on the Semantic Web. RDF specifies many rules for adding metadata and one of its important feature is that data can be expressed in the form of a graph if it is written in RDF. The fundamental unit of an RDF description is called a triple. For example, a sentence “the author of the paper is X” can be expressed as a graph with two nodes, “X” and “paper”, connected by an arc labeled “author”. Connecting all these descriptions, metadata can be expressed as a large graph. We carefully examine the structure of this graph and make the assumption that distinctive patterns within this large graph are important and informative. Although there have been many trials on retrieving informative knowledge or information by processing and analyzing content (information) itself using natural language processing, we think that we can retrieve informative knowledge just by focusing on distinctive patterns in a graph structure without such highly complex processing. A technological overview of iMage is shown in Fig. 1. In this example, metadata of two resources, a database of researchers and data from an SNS, is expressed as a large graph. From this graph, we can discover a skilled person in a particular technology or an active person in an SNS about a particular technology.
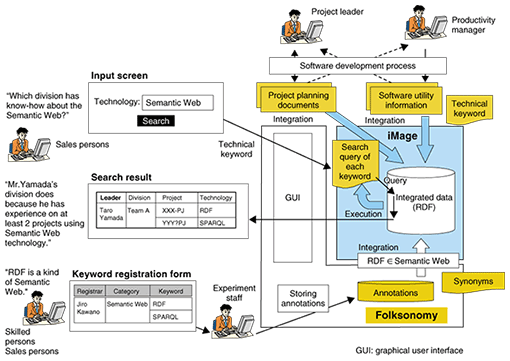
3. Application to the Know Who systemBecause iMage can discover important relationships about people, we think that it is applicable to the Know Who system. By using the data integration functions of iMage, we can utilize a company's existing data for new applications such as the Know Who system. 3.1 Joint experiment on Know Who system for sales personsIn a joint experiment between NTT Information Sharing Platform Laboratories and NTT Software, we developed a Know Who system for sales persons by using data in NTT Software and verified its usefulness by having sales persons use the service in practice. 3.1.1 Need for Know Who system for sales personsIn a company that performs system integration, such as NTT Software, there are many cases where sales persons want to know whether there are any experts on a certain technology in their company. Since many sales persons are not well informed about such matters, we developed a system called the “Technology-case matching service” that can assist in finding appropriate persons or divisions to contact. This service enables sales persons to find the right persons quickly and prevent a mismatch between a project and the people assigned to it. 3.1.2 Data sourcesWe use two main kinds of data for our Know Who system. – Project planning documents – Software utility information NTT software handles all projects in the form of project planning documents. A project planning document gives the type of project, the name of the division in charge, the name of the project leader, the development period, the process of development, the project members and their skills, and so on, so it is suitable for the Know Who system, which can search for persons or divisions by using technical keywords. In this experiment, we used about 8000 items of data over the past four years related to about 1000 persons. In our Know Who system, the selection of search keywords is very important. Technical keywords are extracted by the system administrators and the domain experts, and we also use software utility information to extract technical keywords. Software utility information is expected to include important and proven product names for system integrators. 3.1.3 System architectureThe architecture of our Know Who system is shown in Fig. 2. iMage analyzes the structure of RDF data and extracts distinctive patterns, which are used as queries when a search is executed. To enable the Know Who system to be operated by users, we had to develop the graphical user interface shown in Fig. 2 because iMage provides only the libraries used in searches.
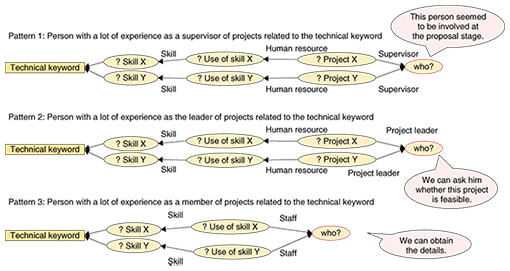
3.1.4 Distinctive patternsFirst, iMage analyzes the structure of RDF data expressed as a graph. Then, it extracts distinctive patterns from it. Finally, it retrieves knowledge or information by using the patterns as queries. Some examples of distinctive patterns automatically extracted by iMage and then selected by system administrators are shown in Fig. 3. Ordinary search engines only list persons that match the given technical keyword. However, iMage also categorizes them persons based on distinctive patterns. For example, the persons in this result are categorized as a supervisor (pattern 1), project leader (pattern 2) or technical staff member (pattern 3) of a project related to the keyword, as shown in Fig. 3.
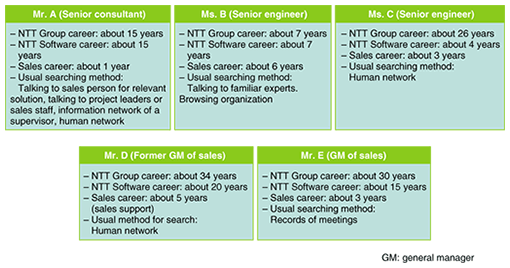
3.1.5 Innovations to improve effectivenessWe can measure the effectiveness of the Know Who system by checking whether all of the experts for the given technical keyword are in the search result. To improve the effectiveness, we introduced two innovations to the system. – Support for synonyms by using folksonomy [3] – Support for different spellings Synonym support using folksonomy means that when the given keyword is too specific to find experts in the given field, the search field is expanded by using synonyms on a higher level of abstraction. In the keyword registration form in Fig. 2, RDF and SPARQL were chosen as synonyms of Semantic Web. Therefore, when no one was retrieved using the keyword SPARQL, the system also tried searching with the keyword RDF. We tried to improve the system's effectiveness by providing a function that lets users add synonyms by themselves, just like the mechanism of folksonomy. The spelling variant support treats alternative spellings of a word as equivalent including alphanumeric words and Japanese hiragana, katakana, and kanji. To handle this, we prepared a dictionary of representative words. We solved the problem by normalizing the words in RDF data and the search keywords to the words in the dictionary. 3.2 System evaluationWe evaluated the system by conducting a survey in the form of a questionnaire. The profiles of the subjects are shown in Fig. 4. We asked the subjects to use the system and then checked the results by asking the system administrators. The results of the questionnaire are shown in Fig. 5. The search with the underlined bold-faced keywords delivered the most effective result because all of the persons in the result were experts including some newly discovered ones who were previously unknown to the subject.
We can conclude that the system is effective at supporting the jobs of system integrators for the following reasons: In 80% of the search results, experts were found. Moreover, many underlined bold-faced keywords were input by users D and E, who are sales persons, i.e., our target system users, who are not familiar with technology. 4. Conclusion and future plansThrough a joint experiment, we confirmed that our iMage technology is applicable to and effective for the field of the Know Who system. We also found that we need to enhance the scalability of the system to handle larger volumes of data than those used in this experiment, for example, data covering a longer term or data for large-scale enterprises. While developing an efficient data collection mechanism and improving the search accuracy, we are moving forward toward commercialization of the system through implementations in various domains. References
|
||||||||||||||||