|
|||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||
       |
Special Feature: Cutting-edge Technologies for Seeing and Showing Vol. 8, No. 11, pp. 17–23, Nov. 2010. https://doi.org/10.53829/ntr201011sf3 Media Scene Learning: A Novel Framework for Automatically Extracting Meaningful Parts from Audio and Video SignalsAbstractWe describe a novel framework called Media Scene Learning (MSL) for automatically extracting key components such as the sound of a single instrument from a given audio signal or a target object from a given video signal. In particular, we introduce two key methods: 1) the Composite Auto-Regressive System (CARS) for decomposing audio signals into several sound components on the basis of a generative model of sounds and 2) Saliency-Based Image Learning (SBIL) for extracting object-like regions from a given video signal on the basis of the characteristics of the human visual system. 
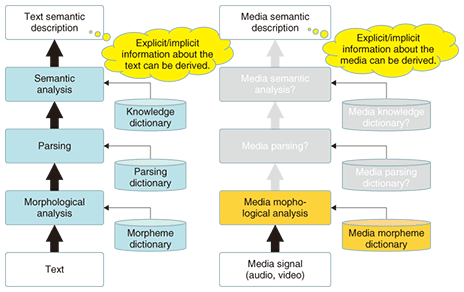
1. Learning for understanding scenes from mediaHumans easily and naturally analyze the surrounding audio and visual scenes acquired by their ears and eyes and understand what is happening. Imitating this mechanism and implementing it on computers has been one of the most important research issues for several decades. With recent progress in hardware and software, several specific technologies such as clean speech recognition and face detection are becoming increasingly used in practice. However, a computer’s ability to recognize and understand audio and visual scenes is generally far worse than a human’s ability, in spite of the long history and importance of this research. Meanwhile, we have to note that this ability is not inherited but learned not only for computers but also humans, except for some basic functions provided by sensory organs such as eyes and ears. In fact, previous psychological studies [1], [2] indicate that most functions for understanding scenes are acquired posteriori through the human development process. This finding implies that learning plays an important role in humans as well as in computers understanding scenes from media such as audio and video signals. 2. Morphemes and their extension to media morphemes2.1 Morpheme: a unit for understanding the meaning of textIn contrast to the case of audio and video signals, a lot of advanced technologies for understanding text information have already been developed. Internet search engines are one of the most successful applications that utilize those technologies. We can instantly find desired web pages just by entering relevant text information. A typical procedure for understanding text information is shown in Fig. 1 on the left. One of the fundamental and significant technologies is morphological analysis, which decomposes a sentence into small parts called morphemes, such as verbs and nouns. Morphological analysis can conveniently provide indices to each web page registered in a database, where a morpheme is used as an index. These indices help us to obtain web pages relevant to a given set of keywords in almost the same way as finding a specific word in a dictionary.
Moreover, morphological analysis plays an important role in bridging the gap between a sequence of characters and its meaning. Each morpheme is associated with some meaning, and its usage is also strictly defined: these are collected in a morpheme dictionary. The information obtained from this dictionary lets us accomplish high-level text processing such as parsing and semantic analysis to accurately capture the meaning of a given sentence. 2.2 Media morpheme: a component for understanding the meaning of audio and video signalsIf we could achieve a procedure similar to morphological analysis for audio and video signals, that is to say media morphological analysis, it would be a significant step toward understanding media scenes. However, the problem is how to construct a media morpheme dictionary describing correspondences between media morphemes and their meanings because the definition of media morphemes has not yet been established. To this end, we are taking another approach to media morphological analysis: we are trying to discover candidates of media morphemes by utilizing its significant characteristics as cues, which might be useful for acquiring and learning media morphemes from media. We call this framework Media Scene Learning (MSL). We focus mainly on two fundamental properties, shown in Fig. 2, to discover media morpheme candidates.
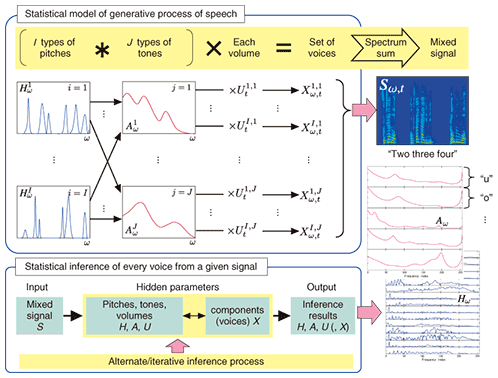
1) Repetition: If several signal elements frequently appear together, the set of elements can be considered to be a media morpheme. 2) Saliency: If a signal element is more salient than neighboring ones, the element can be considered to be a media morpheme. As possible solutions to Media Scene Learning based on the above properties, we introduce two methods below: the Composite Auto-Regressive System (CARS) [3] for audio signals and Saliency-Based Image Learning (SBIL) [4], [5] for video signals. 3. Methods for MSL3.1 CARS for audio MSLOne possible way to achieve MSL for audio signals is CARS [3], which is overviewed in Fig. 3. This method focuses on the first property, repetition: it decomposes a given audio signal into several pairs of a pitch and a tone.
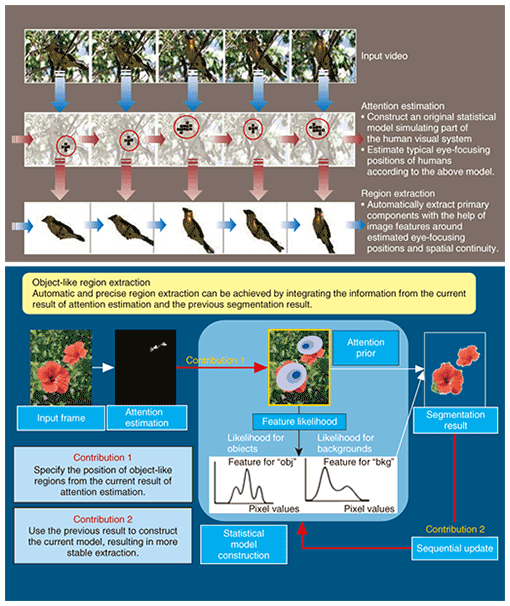
CARS represents an audio signal using a source filter model taking into consideration the process used to generate the audio signals. This model assumes that an audio signal is composed of a mixture of filtered sources, where every source and filter corresponds to a pitch and a tone, respectively, as shown in Fig. 3. The problem is to select as few sources and filters as possible to represent a given audio signal well enough. To do this, CARS tries to discover frequently and simultaneously appearing pitches and tones in a given audio signal by using the Expectation Maximization (EM) algorithm, a standard approach for iterative statistical inference. With the help of the EM algorithm, we mathematically formulated the problem with the following notation: sources H, filters A, volumes U, component signals X, and audio signal S to be analyzed. We derived a solution composed of the following alternating steps: 1) derive sources H, filters A, and volumes U for fixed component signals X and 2) derive component signals X for fixed sources H, filters A, and volumes U. We also confirmed the basic operation of the above mathematical solution via several experiments using speech signals [3]. CARS can be applied to various kinds of situations in audio signal processing. One representative example is speech source separation, where an audio signal that includes a mixture of the voices of several people is decomposed into individual voices and they are restored. Our recent study [6] revealed the effectiveness of CARS for speech source separation. 3.2 SBIL for video MSLOne possible way to achieve MSL for video signals is SBIL [4], [5], which is overviewed in Fig. 4. This method extracts regions of interest as object candidates from a given video signal on the basis of visual saliency. The main features of SBIL can be summarized as follows:
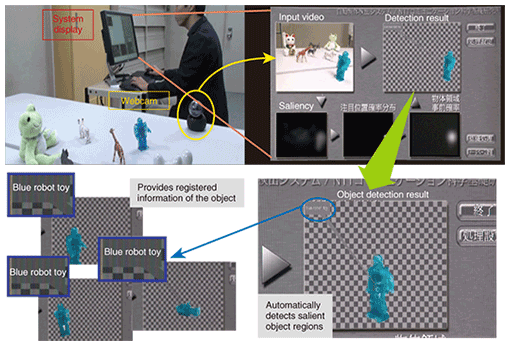
1) Fully automatic extraction: A prior probabilistic density function (PDF) representing the possibility of object existence can be derived automatically via the algorithm for estimating saliency-based visual attention with our Bayesian model [8], [9]. Note that many existing methods, such as interactive graph cuts [7] for still-image segmentation, need some manually provided labels representing an object or a background. SBIL can convert such manual labels into saliency-based attention to achieve fully automatic segmentation. Feature likelihoods of objects representing the tendency of image features of objects can be derived by collecting image features of objects. Likewise, the feature likelihoods of backgrounds (i.e., non-object regions) representing the tendency of image features of backgrounds can also be derived by collecting image features of backgrounds. The prior PDF and feature likelihoods form a statistical model, and the prior PDF can be inferred to derive the segmentation result, in the same way as in interactive graph cuts. 2) Sequential region update: The segmentation result obtained from the previous frame includes significant information for identifying and localizing objects in the current frame since the location and image features do not change much within a short period of time. SBIL fully utilizes the above characteristics. In particular, the location of the previously extracted region is utilized and combined with the current result of visual attention estimation to derive the current prior PDF, and the distribution of image features in the previously extracted region is also combined with the feature likelihood obtained from the first characteristics to derive the current feature likelihoods. As a result, stable segmentation results can be obtained. Many processes in SBIL can be converted to suit parallel processing, so SBIL can be accelerated if multi-core processors are available. We implemented SBIL on a consumer personal computer having a standard graphics processor unit (GPU) and achieved a speed nearly as fast as realtime processing [7], [10]. One promising application of SBIL is generic object localization and recognition. We developed a prototype system for generic object localization and recognition, as shown in Fig. 5. It first captures images from a webcam and extracts object-like regions by means of SBIL. It then retrieves its own database to find and provide registered information about the extracted regions. If there is no relevant information in the database, the system can ask users to provide some related information about the extracted regions. Note that SBIL’s region extraction function plays an important role in identifying the target in question for the system. In the near future, we expect to further enhance this system by integrating the latest research on automatic image annotation and retrieval [11].
4. Prospects for MSLIn this article, we introduced a novel framework called MSL and two key methods, CARS and SBIL, for discovering media morpheme candidates without any human supervision and prior knowledge. Further development of MSL might enable the creation of a media morphological dictionary in which every morpheme is connected to its meaning. Beyond that, we see prospects for media parsing to analyze the structure of media signals and media semantic analysis as the ultimate goal of MSL. Computers have different functions from humans: some functions are possessed only by humans while others are possesses only by computers. This implies that when we eventually create computers that understand media scenes, they might use different techniques from humans. We will continue working on this research so that we get to see the birth of MSL computers in our lifetimes. References
|
||||||||||||||||||||||||||||||