|
|||||||||||||||||||
|
|
|||||||||||||||||||
       |
Feature Articles: Communication Science Reaches Its 20th Anniversary Vol. 9, No. 11, pp. 8–13, Nov. 2011. https://doi.org/10.53829/ntr201111fa2 Statistical Dialogue Processing for Ambient IntelligenceAbstractIn this article, we introduce statistical dialogue control methods that are essential for the implementation of ambient intelligence and present the results of experiments performed to assess the validity of statistical dialogue control. 
1. IntroductionAs social values have shifted away from attaching too much importance to convenience and efficiency, NTT Communication Science Laboratories has been working on projects related to ambient intelligence, which aims to enrich information and communications technology and improve the quality of life [1]. Towards this aim, we propose a new style of living that is achieved through technological developments in communication science, and we have made it our mission to perform interdisciplinary research around the theme of integrated intelligence. As shown in the concept depicted in Fig. 1, the ecology of ambient intelligence can be expressed using phrases such as: there are a lot of intelligent entities, they can be discreet, they answer you, and they are hidden [2]. We are currently trying to realize a form of ambient intelligence by utilizing engineering. One of these trials is introduced below.
In the project, we first demonstrated diverse future life styles with ambient intelligence by presenting them in the form of various scenarios. A simplified version of one of these scenarios is presented below. Scenario: Some people are meeting in a room. A number of ambient intelligences are also scattered around the room.
2. Interactive processing techniquesHow far has this scenario actually been realized so far? To answer this question, we will talk about research on dialogues, which is currently a very active subject. A multi-party prototype dialogue system that we are working on is shown in Fig. 2. We aim to develop a system that can understand the environment of a meeting. In addition, by using the system, we are conducting research into ambient intelligence that acts as an attentive presence that works without making a nuisance of itself [3], [4]. To implement natural dialogue control, we are also researching dialogue processing technology that satisfies the desire for someone to talk with, or for someone who is willing to listen [3], [4]. Below, we focus mainly on our dialogue processing research.
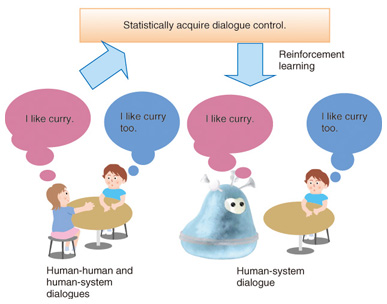
3. Statistical dialogue control methodsIn a wide variety of environments, a huge effort is needed for the manual programming of systems that can dialogue flexibly with humans. Furthermore, complex programs of this sort are impossible to write without inconsistencies. We have therefore developed a statistical method that automatically learns dialogue control from dialogues among humans and between humans and systems, as shown in Fig. 3. This method is based on reinforcement learning: when the system performs an action in a particular situation, a reward value is set to determine the action’s degree of appropriateness. Reinforcement learning is a technique in which dialogue control for action selection to maximize the average reward obtained in the future is determined through a process of repeated trial and error. This technique is used in many different fields such as mechanisms that enable systems to learn actions, but when it is used in dialogue systems, a problem arises: how should the reward values be set to determine the system behavior? We prescribed two types of reward in order to implement better dialogue interactions [5].
(1) Rewards related to satisfaction An annotator is asked to look at dialogues between a human and another human and between a human and a system and evaluate them in terms of their degree of satisfaction. For example, the dialogues are graded according to a 7-point scale by asking questions such as “Did the system listen properly to what the user was saying?” (2) Rewards related to naturalness Initially, we expected that with satisfaction rewards, the system would generate actions that satisfy users. However, in actual experiments, we found that the dialogue system ignored user actions that are naturally included in dialogues between humans, such as greetings, and instead suddenly launched into dialogues that gained higher satisfaction scores. To improve upon this, we considered that dialogues that are performed frequently but are not highly rated are also essential, and we also gave high rewards for such dialogues. By simultaneously setting these two rewards, we implemented dialogue control in a listener interactive system that achieves both high satisfaction and natural interaction. 4. Evaluation experimentNext, we experimentally evaluated the statistical dialogue control method [6]. With current technology, it is extremely difficult for a computer to automatically generate complex sentences such as those used in dialogues between humans. Therefore, in our proposed method, we implemented dialogue control in action units such as asking questions and indicating acknowledgment. Here, we refer to these action units as dialogue actions. To check the performance of the statistical dialogue control method, we performed an evaluation experiment with systems based on rules and a hidden Markov model. The evaluation consisted of three steps.
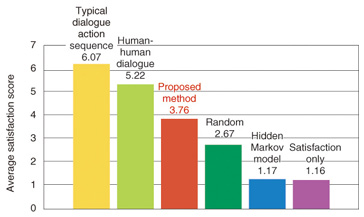
4.1 Comparative systemStatistical dialogue control was learned from the dialogue data. In this evaluation, we introduced a user simulator trained from dialogue data that mimics the user’s action. The system’s dialogue actions were produced using the learned dialogue control. That is, the actual users did not interact, but instead a simulator performed dialogues automatically instead of a computer and user. The user and computer generated 33 dialogue actions. The five systems provided for comparison are described below. (1) Satisfaction only This system uses exactly the same method as the statistical dialogue control method except that it does not use rewards for naturalness: it uses rewards only for satisfaction. This system was provided to evaluate whether naturalness rewards are necessary. (2) Hidden Markov model A hidden Markov model is a type of statistical model that can capture the flow of statistical time sequences. The dialogue actions of the system and user were generated from this model. (3) Typical dialogue action sequence Using rules generated from knowledge obtained in previous studies, interaction sequences were produced for the interaction of both systems and users. (4) Human-human dialogue action sequence This sequence was made by extracting actual dialogue action sequences from data for dialogues between humans. (5) Random Dialogue action sequences were generated randomly. 4.2 Evaluation resultsThe evaluation results are shown in Fig. 4. Our statistical dialogue control method ranked third best, meaning that it came immediately after the human-human dialogue action sequence. Consequently, we found that we were able to build a system that made people feel as if they were being listened to. The figure also shows that rewards for naturalness are important because the system that used only satisfaction was poorly rated.
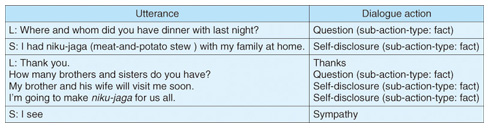
An example dialogue from the system based on the statistical dialogue control method is shown in Fig. 5. It shows that the listener asked questions and performed self-disclosure. The typical actions of a listener were reproduced to some extent, and this helped to draw out the speaker’s conversation. However, the third section was found to contain an inappropriate (unnatural) dialogue action and thanks was generated.
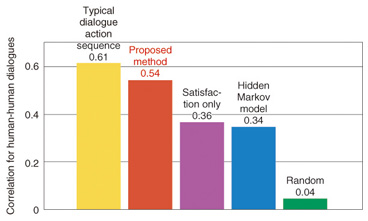
If the frequency of dialogue actions generated in a human-human dialogue is similar to the frequency of dialogue actions generated by the system, then the system dialogue actions should be close to the human dialogue actions. To study this similarity, we calculated the correlation coefficient between the frequency of dialogue actions in human-human interaction and the frequency of dialogue actions in each method (1 represents the highest correlation and 0 represents the lowest). The results are shown in Fig. 6. The highest correlation (closest frequencies) was obtained for the typical dialogue action sequence, and we think that the use of a rule that suitably reproduces human-human dialogue led to the high evaluation value in Fig. 4. The statistical dialogue control method had the next highest correlation, and compared with the other statistical methods, it was able to reproduce the frequency of dialogue actions between humans. These results show that the statistical dialogue control method can acquire a suitable dialogue control method from the dialogue data.
5. Future prospectsSo far, we have implemented a dialogue control that generates only dialogue actions. In the future, we intend to work at deepening our understanding of dialogues and the generation of dialogue content in order to implement a smarter dialogue system. References
|
||||||||||||||||||