|
|||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||
       |
Feature Articles: Communication Science that Connects Information and Humans Vol. 10, No. 11, pp. 24–28, Nov. 2012. https://doi.org/10.53829/ntr201211fa5 MM-Space: Recreating Multiparty Conversation Space by Using Dynamic DisplaysAbstractThis article introduces our system, called MM-Space, which can recreate a multiparty conversation space at a remote place. This system features a novel visualization scheme that represents human head motions by controlling the poses of the screens displaying human facial images. This physical augmentation helps viewers understand more clearly the behaviors of remote conversation participants such as their gaze directions and head gestures. The viewer is expected to experience a more realistic feeling of the presence of the remote people.
1. IntroductionFace-to-face conversation is one of the most basic forms of communication in daily life, and group meetings are used for conveying and sharing information, understanding others’ intentions and emotions, and making decisions. To support communication among remote places, videoconferencing systems have been developed and are widely used. However, they still feel unnatural and uncomfortable. To resolve the problems that have arisen in communications between remote places, which may be not only spatially but also temporally separated, NTT Communication Science Laboratories believes that it is important to deeply understand the mechanism of human-to-human communication and answer questions such as “How do we communicate with each other and what kinds of messages are exchanged by what types of behaviors?” On the basis of this concept, my colleagues and I have been conducting conversation scene analysis for multiparty face-to-face communications [1]. We are trying to extend it toward designing better future communication systems, and we have begun representation/visualization research on multimodal telecommunication and telepresence environments. As the first step, we targeted the problem of reconstructing/recreating the conversation space of a conversation that was originally held at a different location and different time and enabling viewers to visualize the conversation scene as if the people were talking in front them. This article overviews our novel representation scheme and a prototype system after reviewing some of the background. 2. Research progress in conversation scene analysisIn face-to-face conversations, people exchange not only verbal information, but also nonverbal information expressed by eye gaze, facial expressions, head motion, hand gestures, body posture, prosody, etc. Psychologists have suggested that such nonverbal information and behaviors play important roles in human communications [2]. Conversation scene analysis aims to understand human communication though these types of nonverbal information, which is captured by multimodal sensing devices such as cameras and microphones. The goal is to provide an automatic description of conversation scenes in terms of 6W1H, namely who, when, where, whom, what, why, and how. By combining some 6W1H information, we can define a number of problems from low-level (close to physical behavior) ones to high-level (contextual and social level) ones. Let us consider some examples that NTT Communication Science Laboratories (CS Labs) has targeted. “Who is speaking when?” is the most essential question: it is called speaker diarization [3]. The estimation of “Who looks at whom and when?” is also called the problem of the visual focus of attention [4], [5]. “Who is talking to whom and when?” is a question about the conversation structure [4]. “Who responds to whom and how?” is related to the problem of interaction structure estimation [6]. As a higher-level problem, “Who feels empathy/antipathy with whom?” is a question about inter-personal emotion [7]. “Who speaks what?” is known as the speech recognition problem [8]. For each of these problems, NTT CS Labs has devised automatic detection, recognition, or estimation methods. In addition, NTT CS Labs developed the first realtime system for multimodal conversation analysis, which can automatically analyze multiparty face-to-face conversations in real time [9]. This system targets small-scale round-table meetings with up to eight people and uses a compact omnidirectional camera-microphone device, which captures audio-visual data around the table. From the audio-visual data, this system can estimate “who is talking” and “who is looking at whom” and display them on screen. The latest system has added speech recognition and displays “who speaks what” in semi-realtime [8]. 3. MM-Space: Reconstructing conversation space by using physical representation of head motionsBeyond the analysis research toward future communication systems, we have recently devised a novel representation scheme and made a prototype system, called MM-Space [10], [11]. It aims to reconstruct multiparty face-to-face conversation scenes in the real world. The goal is to display and playback recorded conversations as if the remote people were talking in front of the viewers. The key idea is a novel representation scheme that physically represents human head motions by movements of the screens showing facial images of the conversation participants. This system consists of multiple projectors and transparent screens attached to actuators. Each screen displays the life-sized face of a different meeting participant, and the screens are spatially arranged to recreate the actual scene. The main feature of this system is dynamic projection: the screen pose is dynamically controlled in synchronization with the actual head motions of the participants to emulate their head motions, including head turning, which typically accompanies shifts in visual attention, and head nodding. We expect physical screen movement with image motion to increase viewers’ understanding of people’s behaviors. In addition, we expect background-free human images, which are projected onto the transparent screens, to be able to enhance the presence of the remote people. Experiments suggest that viewers can more clearly discern the visual focus of attention of meeting participants and more accurately identify who is being addressed. The idea of this system comes from the importance of nonverbal behavior and nonverbal information in human conversations. This nonverbal information, which is exchanged in a face-to-face setting, cannot be fully delivered in a remote communication setting, e.g., videoconferencing. This insufficiency causes the unnaturalness of telecommunication environments. On the basis of this perspective, we introduced the key idea that physical representation of such nonverbal behaviors, especially head motions, can enhance the viewers’ understanding of remote conversations. The nonverbal information expressed with the head motions includes the visual focus of attention, i.e., “who is looking at whom”. Its function includes monitoring others, expressing one’s attitude or intention, and regulating the conversation flow by taking and yielding turns [12]. A human tends to seize upon a target of interest at the center of his or her visual field: you orient your head toward the target, and various head poses appear according to the relative spatial position to the target. Our previous work indicated that interpersonal gaze directions can be correctly estimated with an accuracy of about 60–70% from head pose information and the presence or absence of utterances without actual eye-gaze directions. In addition, head gestures such as nodding, shaking, and tilting are important nonverbal behaviors. The speaker’s head gesture is considered to be a sign of addressing or questioning, and the hearer’s head gestures indicate listening, acknowledgement, agreement or disagreement, and level of understanding. Our system can replicate head gestures as physical motions of a screen, which gives viewers a stronger sensation of the presence of the meeting participants. The physical representation of head motions is also related to human visual perception called biological motion [13]. Humans tend to anthropomorphize lifeless objects by assigning social context to movements, even if the objects are simple geometric shapes such as points and triangles. On the basis of the above findings, we hypothesize that realistic kinematics offers strong cues for better understanding human communications, regardless of how it is implemented. Therefore, rather than pursuing realistic three-dimensional shape reproduction, our approach uses simple square screens and reproduces physical head motions to produce an augmented expression modality. We expect that combining this physical motion with image motion will boost the viewer’s understanding. Moreover, it is known that human vision is highly sensitive to motion in the peripheral field. Therefore, viewers can perceive the entire conversation space including not only a person in front of them, but also the behaviors and presence of people located on their left or right. 3.1 System configurationAn overview of the MM-Space system is shown in Fig. 1. The reconstructed conversation space is shown in Fig. 1(a) and the actual conversation scene is shown in Fig. 1(b). In an actual conversation, multiple cameras and microphones capture the participants’ faces and voices, respectively. In the reconstructed scene, multiple screens, projectors, actuators, and loudspeakers are placed to recreate the actual seating arrangement. Each participant’s face is displayed on a flat transparent screen whose pose is dynamically changed in sync with his or her head motion. Each person’s voice is play backed from the loudspeaker located in front of the screen displaying that person, so viewers can identify the speaker’s position not only visually, but also aurally. The system described here was created to verify the effectiveness of head motion representation, so here we focus only on offline playback, but we plan to extend it to realtime telecommunication. In addition, our system provides a novel research platform for conversation analysis.
The screen, projector, and actuators are shown in Fig. 2. Each screen is highly transparent but includes a diffusive material that catches the projector’s output and makes it visible to the viewer. Each screen has its own liquid crystal display (LCD) projector behind it. Each screen is supported by an actuator, called the pan-tilt unit, that provides rotational motion in both the horizontal and vertical directions. We call this display device a dynamic display.
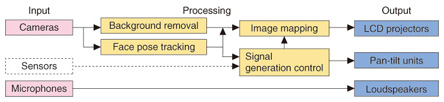
A block diagram of MM-Space is shown in Fig. 3. The processing parts provide visual face tracking, background removal, image mapping, and control signal generation. Visual face tracking measures the head position and pose of the meeting participants. Background removal creates images that emphasis the participants. The control signals drive the actuators holding the screens to reflect the participants’ face poses, which are measured with visual face tracking and/or motion capture devices. Image mapping generates projected images that are skew-free.
3.2 EffectivenessAs the effect of the motion representation by dynamic screens, we hypothesized that a viewer can more clearly understand the gaze directions of meeting participants as well as who they are addressing. To verify this hypothesis, we compared two different conditions—with and without the motion representation—in terms of identification accuracy. Experimental results indicate that viewers could indeed more clearly recognize the gaze direction of meeting participants when the screens moved. In addition, the results statistically support the hypothesis that viewer can more accurately identify who is being addressed when the screens moved. 4. Conclusions and future perspectiveThis article introduced our system MM-Space for recreating a conversation space at different times and places. Its key feature is the physical representation of head motion as an additional expression modality. The synergy of physical screen motion and image motion on the screen is expected to boost our perception of social interactions involving the visual focus of attention. MM-Space is expected to be extended to realtime communication systems that can connect people located at different places. For that purpose, it will be necessary to explore in more detail the characteristics of the motion representation and evaluate how it can contribute to better expression and perception of addressing others and being addressed by others. In addition, other problems include the optimum camera configuration and the latency of telecommunications and physical systems. Finally, we believe that MM-Space will be a useful research platform for designing better communication systems and analyzing and understanding the mechanism of human communications. References
|
||||||||||||||||||||||||||||