|
|||||||||||||||||
|
|
|||||||||||||||||
       |
Regular Articles Vol. 13, No. 8, pp. 53–59, Aug. 2015. https://doi.org/10.53829/ntr201508ra2 Improving User Capacity and Disaster Recovery Time in IP Telephone Service SystemsAbstractThe NTT Group is working on improving Internet protocol (IP) telephone networks and solving certain problems associated with them. Specifically, efforts are underway to improve the accommodation rate, reduce network operating costs when the number of network users increases, and reduce service recovery time when a network is damaged because of a natural disaster. To resolve these problems, we developed a system architecture that simplifies the operation of IP telephone networks and uses network equipment much more efficiently. This is possible with a subscriber data management server. We describe here our new network architecture, the mechanism to solve these problems, and the effect it has on IP telephone networks. Keywords: IP telephone, disaster recovery, call session control function server, home subscriber server
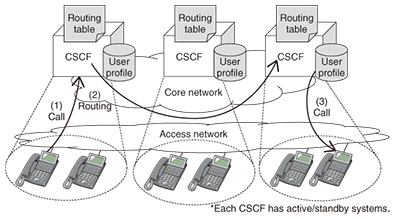
1. IntroductionEssential social infrastructures such as electric power systems, water systems, and communication systems were destroyed over a huge area after the Great East Japan Earthquake struck on March 11, 2011, and these systems could not be used for a long time after that. Specifically, 29,000 mobile communications base stations and 1.9 million fixed telephone lines could not be used. It took about three days to recover telephone services provided by the NTT Group [1]. As a social infrastructure provider, the NTT Group learned from this experience that network operators must ensure consistent availability of services and early recovery of services even after wide-area disasters. The devices used for Internet protocol (IP) telephone service range from smartphones to conventional fixed telephones. Therefore, IP telephone services must accommodate frequent terminal location registrations and high-frequency use of each terminal. We describe here the new IP telephone network architecture that will improve the flexibility of subscriber accommodation, and we explain the results of a study on how the new network architecture reduces the time to recover from a disaster. 2. Characteristics of and problems with IP telephone network architectureCurrently, the NTT Group offers a variety of IP telephone services such as Hikari Denwa and the 050 number voice over IP (VoIP) service. The IP Multimedia Subsystem (IMS) architecture [2–4] is partially adopted in these IP telephone services. The IP telephone service was initially available for fixed telephones via VoIP routers for private use. Office use, such as the pilot telephone number service, also began in conventional fixed telephone networks. Therefore, we adopted a network architecture that efficiently performs a call control process; the correspondence between the call control server (the call session control function (CSCF)) and the user (telephone number) is fixed, and the CSCF is designed to accommodate each number range, the same as for the traditional public switched telephone network (PSTN). The CSCF holds the subscriber data (service contract information and authentication information) related to the telephone number to be accommodated [5]. Routing information to identify the CSCF that accommodates the number range is managed by each CSCF. Therefore, the CSCF that receives a call request from a terminal (indicated as (1) in Fig. 1) determines the destination CSCF that accommodates the terminal by using its own routing information (2), and transfers the call request from the terminal to the destination CSCF (3). In addition, to maintain reliability and non-interrupted service during system changes, each CSCF adopts an active and standby (ACT/SBY) dual system as a redundant system.
In extending the system to cope with an increase in the number of users and the amount of traffic, it is conventionally assumed that there is a proportional relationship between users and traffic; therefore, resources are designed after calculating the load from the traffic rate and average holding time to install additional equipment in accordance with the increase in traffic. However, because softphone users, for example, include many non-active users* who install applications on their terminal but do not use them frequently, there are cases in which the number of users is large, but the load in the IP telephone network is low. Therefore, the CPU (central processing unit) working rate is low at the maximum amount of subscriber data to be accommodated, and vice versa, so equipment resources cannot be fully used. As a result, equipment utilization efficiency is low compared to the older IP telephone network (Problem 1). For load-balancing, however, we need to change the routing information of each CSCF to identify the destination CSCF of incoming users, which is a significant operational burden (Problem 2). In addition, with the current redundant configuration, both ACT/SBY systems could be damaged in the event of a large-scale disaster, so there is a problem concerning the availability of the social infrastructure (recovery time for both system failures) (Problem 3). We explain the details of this problem in the next section. Our solution to these problems is to separate the subscriber data and routing information from the CSCF. The home subscriber server (HSS) manages subscriber data and routing information, so the relationship between telephone numbers and the CSCF is flexible. Therefore, the CSCF-HSS separation architecture can be adopted. It should be noted that upon separation, we take into account the impact on services specific to the conventional fixed telephone networks such as pilot telephone number and call-pick-up services (Problem 4).
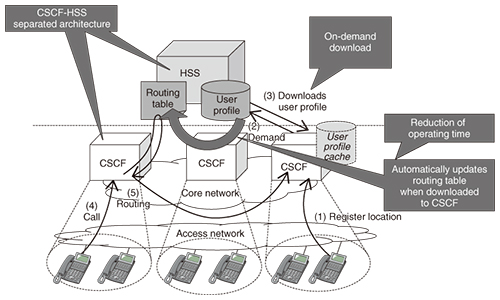
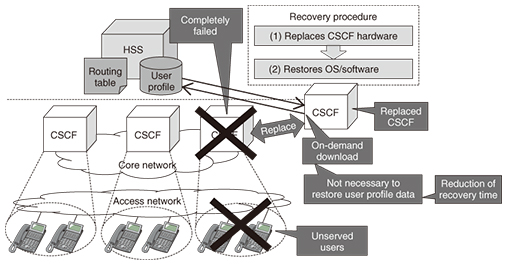
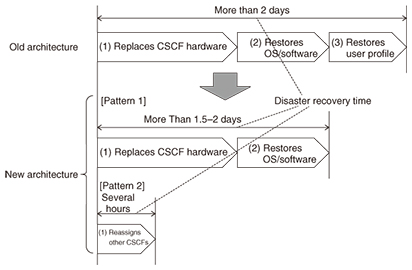
3. Issues regarding service recovery time after natural disasterWe now explain the details of Problem 3. NTT Network Service Systems Laboratories has been working to improve reliability during serious disasters by building on knowledge and experience gained in the aftermath of the 2011 Japan earthquake. With the conventional network configuration, a simultaneous failure of redundant configuration systems must be assumed after a serious disaster because the subscriber data contained in the CSCF are fixed. Therefore, we need to rebuild equivalent devices. Specifically, the following procedure is required. • Replace afflicted CSCF hardware. • Restore operating system (OS) and applications. • Restore subscriber data. It takes several days to complete this procedure, which is itself an issue. (Note that the recovery time depends on the manpower and equipment available for the recovery work.) 4. CSCF-HSS separated architectureWe introduce here the CSCF-HSS separated architecture to solve the above-mentioned problems. 4.1 Effective use of server resources for managing usersIn the CSCF-HSS separated architecture (Fig. 2), HSSs manage the master data of user profiles, and the CSCF downloads user profile data on demand from the HSSs when the user equipment registers its location information via an IP telephone. After that, the CSCF retains the user profile data as a cache during the validity period of the location information. With this mechanism, the CSCF does not retain the user profiles for non-active users who have not used an IP telephone for a certain period of time. Therefore, the CSCF can manage more user profiles of active users because it does not consume as much memory as the old architecture. Thus, we can use the CSCF’s resources effectively to solve Problem 1.
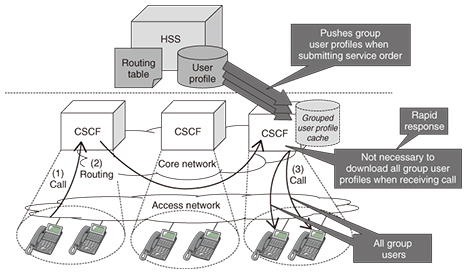
4.2 Automatic updating of routing informationTo update the routing information in order to detect the CSCF that manages a certain user when user profile data are moved from one CSCF to another, we introduce a mechanism in which an HSS automatically updates the routing table when a CSCF downloads user profile data from the HSS (Fig. 2). Therefore, it is not necessary for each CSCF to have a routing table because the CSCFs can detect the destination CSCF that manages the user profile data. Therefore, service operators do not need to update the routing information, and we can solve Problem 2. 4.3 Maintaining communication quality for fixed telephone serviceWe provide fixed IP telephone services for businesses and user-grouping services such as pilot telephone number or call pick-up services. In these services, we need to update the cache of user profile data in CSCFs when the master data are updated in the HSS by submitting or changing the service order. In the IMS standard models, a CSCF downloads user profile data from an HSS on demand when receiving a call; however, this incurs delays due to the downloading of all group member profile data. Thus, communication quality decreases. Therefore, we extended an HSS’s function to push user profile data to CSCFs defined in the IMS standard [6]. Our HSS simultaneously pushes all user profile data in a group. In our new architecture, CSCFs do not need to download all group member profile data on demand and can reduce the number of times the HSSs need to be accessed because the CSCFs already have all profile data in the group due to the extended push function and can respond rapidly. Thus, the communication quality of user-grouping services is maintained (Fig. 3) and we can solve Problem 4.
5. New recovery procedure and effectivenessWe solve Problem 3 by creating recovery procedures for the new architecture in which HSSs are separated from CSCFs. We introduce two new recovery procedures. First, we describe the recovery procedure (pattern 1), in which the time to restore user profile data is reduced compared to the old procedure. Second, we describe the procedure (pattern 2) in which we use server resources of other surviving CSCFs to recover the failed CSCFs. We describe these procedures and their effectiveness below. Pattern 1: Other surviving CSCFs do NOT have enough unused server resources. (1) Recovery procedure Step 1: Replace completely failed CSCF hardware with new hardware. Step 2: Restore the OS and application software. After step 2 is completed, the rebuilt CSCFs can serve users that were prevented from using IP telephone services due to failed CSCFs by downloading user profile data on demand from the HSSs (Fig. 4).
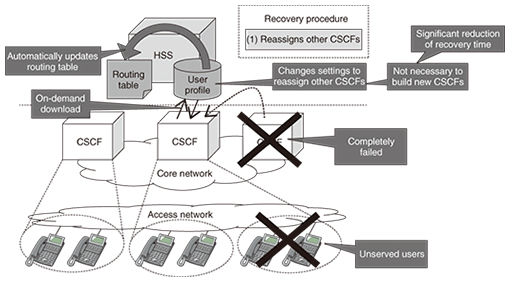
(2) Effectiveness We can reduce the recovery time by skipping unnecessary steps such as restoring user profile data in the rebuilt CSCFs. Pattern 2: Other surviving CSCFs HAVE enough unused server resources and can serve users supported by failed CSCFs. (1) Recovery procedure Step 1: Reassign the affected users to other surviving CSCFs instead of the failed CSCFs. Specifically, we change the settings in the HSSs so that the surviving CSCFs serve the affected users instead of the failed CSCFs. After that, the routing tables in the HSS are updated automatically, so we do NOT need to change the routing tables of all surviving CSCFs (Fig. 5).
(2) Effectiveness We can recover IP telephone services for affected users without building new CSCFs to replace the failed CSCFs, so the disaster recovery time drastically decreases. The difference between the old and new IP telephone network architectures with respect to recovery time when redundant CSCFs fail completely is shown in Fig. 6. Specifically, recovery is very fast in pattern 2 because we can recover the services within several hours. It takes several days to recover services with the old architecture. Thus, we can solve Problem 3.
6. Future workWe plan to work on developing a much faster recovery method and will therefore investigate a recovery procedure that involves not only servers such as HSSs and CSCFs but also user equipment, transport network elements, and business support systems. References
|
||||||||||||||||