|
|||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||
       |
Feature Articles: Interdisciplinary R&D of Big Data Technology at Machine Learning and Data Science Center Vol. 14, No. 2, pp. 21–26, Feb. 2016. https://doi.org/10.53829/ntr201602fa3 The Latest Developments in Jubatus, an Online Machine-learning Distributed Processing FrameworkAbstractMobile terminals and other devices are now adopting multiple sensors, which generates voluminous data sets (big data). This necessitates rapid analysis of big data to understand the latest trends and current events. In this article, we introduce the latest developments in the open source community and commercial support activities for the distributed processing framework called Jubatus. Case studies are introduced to show that it offers deep analysis of big data in real time. Keywords: real-time analysis, parallel and distributed architecture, online machine learning
1. IntroductionThe popularity of the Internet and the rapid adoption of information and communication technology mean that large volumes of a wide variety of data sets are being generated. Examples include user data from various social networking services (SNSs) such as Twitter*1 and Facebook*2, log files from network equipment and servers, and data sent from vehicle-mounted sensors and home appliances. We introduce here the online machine-learning distributed processing framework Jubatus and some examples of its application. It moves beyond simple statistical aggregation and keyword searches of big data and offers real-time and deep analysis of big data.
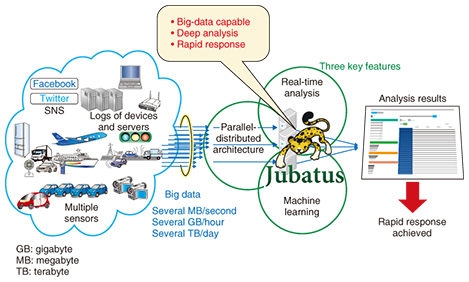
2. JubatusNTT’s laboratories and Preferred Infrastructure, Inc. (PFI) commenced work on the Jubatus project in 2011 and released it as open source software (OSS) in October of that year [1–3]. Jubatus was developed with two goals in mind, and three features were added in order to achieve these goals, as shown in the green circles in Fig. 1.
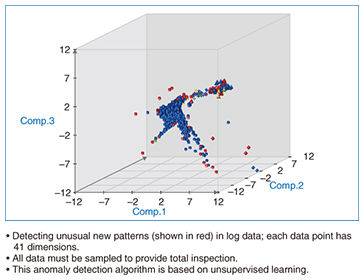
The first goal is highly scalable processing performance for real-time analysis, which is achieved through the parallel and distributed architecture of Jubatus. The second goal, deep analysis, is realized by the adoption of machine learning techniques. Real-time analysis enables quick response through sequential processing of continuously generated streams of data without temporary storage. The parallel and distributed architecture enables scale-out by adding servers in the same way as Hadoop and other large-scale data processing platforms. Given that it is often difficult to set rules to govern system processing in advance (since the rules are unknown, it is difficult to express constraints as rules, or the rules change over time), Jubatus adopts the machine learning approach to learn rules from data examples. Jubatus has offered for the first time in the world the combination of real-time analysis, parallel and distributed processing, and machine learning [4]. 3. Jubatus application examplesThe three features of Jubatus are useful in detecting the onset of abnormalities or failures. For example, in the case of a factory, rapid response (real-time analysis) can be achieved by sequentially processing the data and logs output by a variety of sensors. The parallel and distributed architecture of Jubatus makes it easy to add extra servers whenever needed, so real-time response is possible even when the service area is extremely large and the number of sensors is enormous. Rather than adding dedicated systems to catch faults, the anomaly detection algorithm of Jubatus and its machine learning approach enable anomalies to be identified from the data of many sensors even if the detection pattern is unknown to the operator. An example of the machine learning approach being applied to server log data is shown in Fig. 2. Principal components are extracted and plotted in three dimensions; data points that are unusual are shown in red. This representation yields regular and irregular patterns and enables unknown anomalies to be predicted.
To expand the application area of Jubatus, researchers at NTT’s Machine Learning and Data Science Center are working in tandem with researchers involved in the himico initiative [5] on a proof of concept (PoC)*3 project targeting areas such as network fault detection.
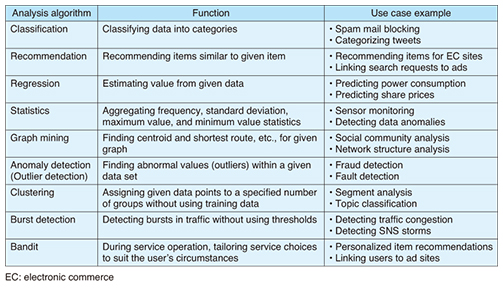
4. Latest development trendsSince its release as OSS in 2011, Jubatus has been repeatedly upgraded (nine times in 2014 alone), with emphasis placed on improving productivity. Consequently, it now offers an extremely efficient programming environment. In addition, data scientists and professionals in different fields are continually enhancing its various analysis algorithms. The algorithms currently available in Jubatus are listed in Table 1. As one example, the Bandit algorithm allows multiple solutions to a problem to be assessed in parallel, even while the service is in operation, and it determines which solution best suits the user’s current situation. This algorithm is extremely useful for product recommendations and advertisement placements.
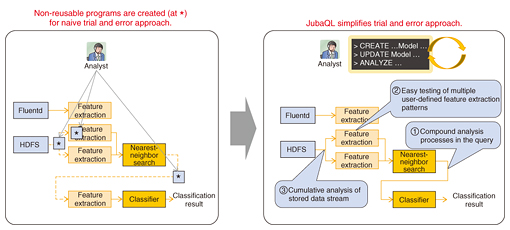
The analysis algorithms listed in the table take the form of plug-in modules, and user-written analysis modules can be loaded as plug-ins that can be freely selected and applied as needed. JubaQL is the latest of our research results to be published. JubaQL offers an interactive interface with SQL (Structured Query Language)-like syntax to access the rich online machine learning functions available. Some of the benefits provided by JubaQL are shown in Fig. 3. Prior to its release, client programs that were needed for repeatedly evaluating different combinations of analysis processes had to be written in Ruby, Python, or another programming language. JubaQL offers highly efficient analysis processing and enhanced productivity.
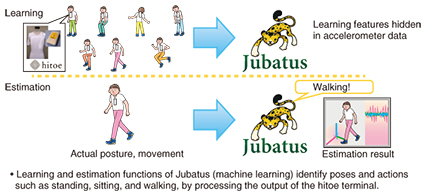
5. OSS community activities and commercial support systemAs mentioned above, Jubatus has been released as an OSS project. Many of the distributed processing tools needed to undertake big data analysis such as Hadoop have been published as OSS projects and are attracting the interest of many developers and researchers. This has created an extensive ecosystem that has yielded new use cases and examples of data utilization. Our aim in releasing Jubatus as an OSS project is to connect with more users and thus discover new use cases and ideas for data utilization. Our OSS project is extremely lively with over 2000 code commits, and we place emphasis on continually improving its usability. Lively community activities are also taking place, with some 590 participants attending two hackathons, four hands-on meetings, three casual talks, and one casual meetup event. The casual talks have been very interesting, as they introduced usage reports from organizations other than the original developers, NTT laboratories and PFI, which confirms that the use of the system is expanding. Another significant indicator is the drive to introduce Jubatus to commercial products and thus expand its use by businesses. This will require careful utilization of commercial knowledge through selection of the most suitable analysis algorithm and performance tuning. To better support businesses, NTT Software Corporation established a commercial Jubatus support service in January 2014; it offers a wide variety of support functions to enhance the commercial application of Jubatus. 6. Case studies6.1 Case 1: WatchBeeJubatus is used in the summary display function of WatchBee [6], a reputation analysis service provided by NTT IT Corporation (NTT-IT). This function analyzes large-scale data such as SNS data, extracts the features of each kind of data, and groups similar data based on the correlation between features. Rapid data analysis is essential for this function because large quantities of new data are created every minute, and WatchBee must analyze that data every 30 minutes. The online processing of Jubatus has substantial advantages for this kind of deep and large-scale real-time analysis. 6.2 Case 2: hitoeJubatus is well-suited for analyzing sensor data. With conventional techniques, threshold values are necessary to classify human poses and motions when analyzing their three-axis accelerometer data*4 acquired from wearable devices such as hitoe [7]. However, it is difficult to determine the proper threshold values. Furthermore, optimum values may differ from person to person because of their different physiques and manners of poses and gestures. Jubatus can automatically find the criteria for establishing thresholds by learning from the sensor data of each pose and motion (Fig. 4). Personalized criteria for every individual are generated by Jubatus since it is able to distinguish the differences in personal physiques and in the manner of poses and gestures. Furthermore, Jubatus can improve the accuracy of criteria by using its incremental learning function on misclassified data.
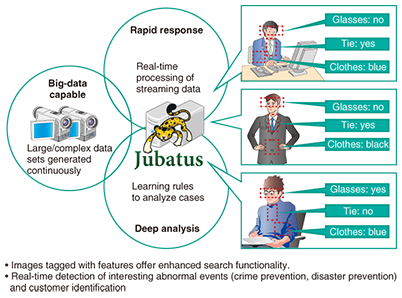
6.3 Case 3: Surveillance video analysisJubatus can also be used to analyze footage captured in surveillance videos (Fig. 5). Current security systems are inefficient, as the stored videos must be manually rewound to around the time of the incident and then manually reviewed. This can allow crime precursors to be overlooked. The classification power of Jubatus can be used to analyze the videos as they are captured and to extract notable features such as the color of clothing, the presence of a backpack, or actions such as using a smartphone or reading a book. The image data are tagged with the features, which greatly facilitates subsequent processing and search operations.
We intend to utilize the latest video recognition technology such as deep learning [8] to further enhance the accuracy of attribute classification.
7. Future developmentsCurrent activities are mainly directed towards strengthening the analysis algorithms of Jubatus and enhancing the usability of JubaQL. A long-term goal remains raising user awareness of Jubatus. Future activities will focus on introducing Jubatus to business applications, improving service quality (higher operability and reliability), and adding peripheral functions. Finally, we intend to greatly expand the application area of Jubatus by introducing it in new fields such as AI (artificial intelligence) and IoT (Internet of Things). References
|
||||||||||||||||||||||||||