|
|||||||||||||||||||
|
|
|||||||||||||||||||
       |
Feature Articles: Creating a Flexible and Smart Network as a New Social Infrastructure Vol. 16, No. 6, pp. 11–17, June 2018. https://doi.org/10.53829/ntr201806fa3 Creating New Value by Leveraging Network-AI Technology in Service OperationsAbstractWe present in this article an overview of recent research and development done at the NTT laboratories on artificial intelligence technology for networks (Network-AI) that enables proactive maintenance and operations of network services. We also describe some of the key technologies constituting Network-AI and review verification trials of these technologies conducted at an NTT operating company. Keywords: Network-AI, proactive maintenance and operations, automation
1. IntroductionIn order to forge ahead with the development of services while sustaining the services currently available in the face of social changes such as a declining population and ever more diversified communication services, we must have the ability to accurately assess the operational status of services and be able to upgrade and enhance services once they are up and running. The NTT laboratories strive to make service operations more efficient and to enhance service value and are therefore working to implement an autonomous control loop that cycles through the three phases of (1) gathering various types of information, (2) analyzing the collected information, and finally, (3) issuing accurate instructions and controls based on the analytical results in the planning, design, construction, maintenance, and operation of networks. By leveraging artificial intelligence technology for networks (Network-AI)*, we are now making good progress in developing more sophisticated operations and support systems. Various Network-AI related initiatives are now under consideration. One such initiative is resources-on-demand, which automatically suggests and allocates optimal resources required by service providers. Another is scheduled maintenance, which eliminates the need for urgent maintenance once a network problem has already occurred. This will give us the ability to autonomously control the entire sequence of service events, from provisioning of services to maintenance and operations, and the entire NTT laboratory community is working toward this objective. This article focuses on key initiatives now underway with the goal of implementing scheduled maintenance.
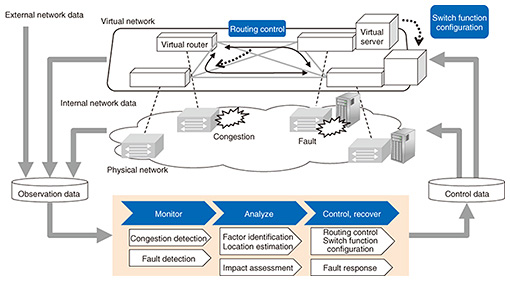
2. Initiatives enabling scheduled maintenanceTwo key capabilities are needed to make scheduled maintenance a practical reality. First, this would require a shift from reactive maintenance and operations that deals with faults and operational problems that have already occurred to proactive maintenance and operations that focuses on preventing problems before they occur. Second, it requires systematic automated maintenance and operations that fully supports virtualization. The NTT laboratories have come up with the proactive controlled network concept as a way of implementing proactive maintenance and operations combined with automation. The idea behind a proactive controlled network is to anticipate potential performance degradation risks (e.g., outages, failures, and congestion) before they occur, to anticipate foreseeable changes in demand early on, and to achieve proactive control and early automatic recovery. The proactive controlled network involves a sequence of typical operational phases for dealing with each type of risk: (1) monitor, (2) analyze, and (3) control and recover, as illustrated in Fig. 1 [1], and we are developing key Network-AI technologies for each phase with the following objectives: (1) Achieve proactive early detection of changes in network conditions due to degraded performance (congestion, equipment failure, etc.). (2) Estimate degraded location and likely cause of the changes in network conditions. (3) Take control to circumvent performance degradation, and implement early recovery.
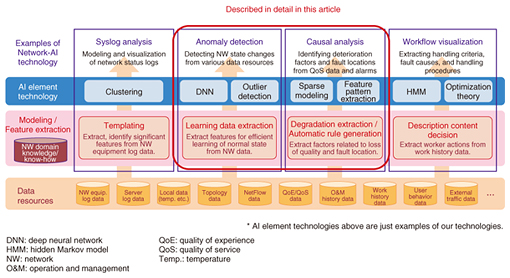
Some of the core technologies being applied to implement these operational phases are indicated in Fig. 2.
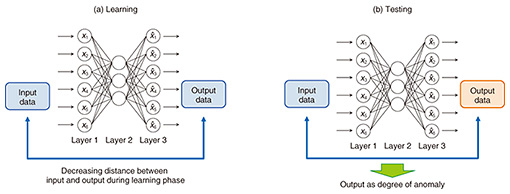
We focus here on two of these technologies—network anomaly detection, a monitoring technology developed for early detection of anomalous events (e.g., silent failures), and automatic failure points estimation, an analysis technology. We also review the status of ongoing verification trials of the network anomaly detection technology that has been deployed and is now being evaluated at an NTT operating company. 3. Network anomaly detection technologyNTT Network Technology Laboratories is making headway in the development of an autoencoder (AE)-based network anomaly detection system designed to achieve early detection of changes in network conditions [2–4]. An AE is a kind of neural network capable of unsupervised learning of the intrinsic complex structure of data and is currently drawing a great deal of interest for anomaly detection applications. We have utilized AE characteristics such that by setting the number of neurons in the hidden layer of the AE at less than those in the input layer, a data dimension reduction occurs in the hidden layer by learning parameters to reconstruct the input layer data at the output layer. AE-based anomaly detection is based on the assumption that a normal data distribution is concentrated near a low-dimensional manifold in the input data space. During the learning phase shown in Fig. 3(a), the normal state is learned by observing various types of data during normal operation of the network, while in the test or anomaly detection phase shown in Fig. 3(b), current data are input to the AE learned as described above, and the distance between input and output layer vectors is output as the degree of anomaly. If the degree of anomaly exceeds a certain threshold, it is considered anomalous.
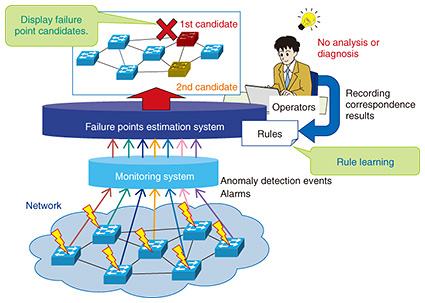
For our purposes, the network data that are input include numerical data such as resource/traffic data based on Simple Network Management Protocol and Management Information Base (SNMP/MIB) and flow data based on NetFlow as well as detailed text logs such as syslog data from routers and servers. To input syslog data to AE, we employ syslog analysis [5] to generate identifiers (IDs) from each syslog line, and text data are converted to numerical data based on message ID frequency analysis. In addition to anomaly detection, efforts are also underway to identify the outlier factor when an anomaly is detected [6]. For example, if an anomaly is detected by AE, we estimate which input dimension is responsible for increasing the degree of anomaly by using a sparse-optimization technique. Calculating the contribution of each input dimension to the anomaly should make it much easier to isolate the problem after an anomaly is detected. 4. Automatic failure points estimation technologyMeanwhile, NTT Access Network Service Systems Laboratories is working on a related analytical scheme for locating network anomalies [7], as illustrated in Fig. 4. This system is designed to autonomously derive causal links between failure causes and alarms, or rules, from network information and alarms emitted by equipment that approximately locate the point of the failure. When a network anomaly is detected as described in the previous section, a detection event and proximate alarms generate a rule, which accurately predicts the points of the failure. This information is then used to send a command to circumvent the trouble and thus avoid a performance slowdown and/or commence rapid recovery of the service. Moreover, because new rules created to deal with new anomalies and failures are saved, the predictive accuracy of the system should improve over time.
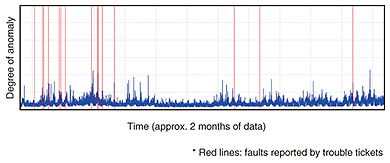
5. Verification trials of network anomaly detectionWe are now in the process of evaluating the network anomaly detection technology using real operational data from a testbed and actual services in collaboration with NTT operating companies. This will help us assess the effectiveness of our proposal and identify challenges that still need to be addressed. The trials now being conducted in collaboration with NTT Communications are described in this section. 5.1 Collaboration with Technology Development DepartmentThe Technology Development Department of NTT Communications operates a testbed that has been made available to NTT Communications for the development of their services. The department is also developing the Data Science Lab (DSL) on the testbed, which is a big-data analysis platform initiative to collect and analyze various types of service and infrastructure data with the idea of exploiting the data to create new service strategies and implement anomaly detection. For this work, we evaluated the network anomaly detection technology developed by NTT Network Technology Laboratories on a range of typical operational data gathered on the DSL—SNMP/MIB, NetFlow, syslogs, trouble tickets, and the like—to assess the technology’s practical performance and problems. The basic architecture of the DSL is that of a reproducible analysis/research platform, which can reproduce analytical results and infrastructure as code. NTT Network Technology Laboratories’ anomaly detection technology is currently containerized, and we are now working to integrate it on the DSL infrastructure. In Fig. 5, we show anomaly data measured over a two-month time frame, with the degree of anomaly (blue line) on the vertical axis versus time on the horizontal axis. The vertical red lines indicate problems identified from trouble tickets issued during the testbed trials. The trouble tickets identify a range of problems—a server breakdown, a bug, a denial-of-service attack, and so on—and they agree remarkably well with the serious anomaly time slots shown on the graph.
However, there were other serious anomaly time slots detected with the anomaly detection technology that were not caught by the trouble tickets, so we are working to verify the effectiveness of the technology while trying to match up the detection results against actual incidents and events that occurred. In addition, there are a number of practical issues that must be resolved if we are to continually operate the anomaly detection technology on a real-time basis, and we are now addressing these issues. 5.2 Collaboration with Network Services DepartmentThe Network Services Department of NTT Communications is currently trying to exploit AI to upgrade the service operations of a whole range of existing network services. For example, the MVNO (mobile virtual network operator) service that has attracted considerable interest and become immensely popular is a case in point, as the department seeks to exploit AI to implement anomaly detection in this service. More specifically, we have been experimenting with applying network anomaly detection to various types of resource data (utilization of central processing unit (CPU), memory, disk input/output, and so on.) on NTT Communications’ virtualized service platform to see if we can detect singular events and shifts in the degree of anomaly during normal operation. As a result, we found that it was possible to detect singular events from the degree of anomaly by AE and from the contribution of the input dimension (various kinds of time series numerical data) to the anomaly. We also observed a tendency for the anomaly degree to persist and to gradually change over longer time spans, and we were able to capture changes in system behavior manifested as changes in the degree of abnormality. In addition, we identified the specific input dimension causing the change in behavior by calculating to what degree the AE input dimension contributes to the anomaly. From these analyses, we recognized the need for a mechanism that tracks system configuration changes (switching between act and standby, ID changes of the CPU used, and so on) and system behavior changes (changes in CPU, memory, traffic, and other patterns). Therefore, we are developing a statistical, quantitative, and relearning technology to implement such a mechanism. We also found that the new technology is capable of visualizing a range of before-and-after system state changes by clearly showing monitoring parameter trend changes when the system is upgraded. We learned a great deal from carrying out this assessment. Work in the months ahead will focus on practically assessing anomaly detection using greater amounts of data, enhancing our interpretive capabilities after an anomaly has been detected, further testing and assessing the technology, and making efforts to build a more user-friendly implementation of the technology suitable for business environments. 6. Future developmentWe presented a broad overview of some of NTT laboratories’ latest initiatives in the area of Network-AI, focusing on two key technologies—network anomaly detection and automatic failure points estimation—and briefly described verification trials of the network anomaly detection technology done in collaboration with an NTT operating company. Network-AI clearly has enormous potential, and we are committed to following through with more research and development in this area. With regard to network anomaly detection in particular, we will continue to refine and upgrade this technology, conduct further verification trials in cooperation with NTT operating companies, lay the groundwork for prototypes, and eventually implement services using the technology. Network anomaly detection still faces a number of hurdles before it is ready for actual deployment. Most notably, we must improve our ability to interpret the factors involved when an anomaly is detected, and we must adapt the technology for use in different environments. Needless to say, we are hard at work in resolving these issues. References
|
||||||||||||||||||