|
|||||||||||||||
|
|
|||||||||||||||
       |
Feature Articles: Further Exploring Communication Science Vol. 16, No. 11, pp. 19–24, Nov. 2018. https://doi.org/10.53829/ntr201811fa2 SpeakerBeam: A New Deep Learning Technology for Extracting Speech of a Target Speaker Based on the Speaker’s Voice CharacteristicsAbstractIn a noisy environment such as a cocktail party, humans can focus on listening to a desired speaker, an ability known as selective hearing. Current approaches developed to realize computational selective hearing require knowing the position of the target speaker, which limits their practical usage. This article introduces SpeakerBeam, a deep learning based approach for computational selective hearing based on the characteristics of the target speaker’s voice. SpeakerBeam requires only a small amount of speech data from the target speaker to compute his/her voice characteristics. It can then extract the speech of that speaker regardless of his/her position or the number of speakers talking in the background. Keywords: deep learning, target speaker extraction, SpeakerBeam
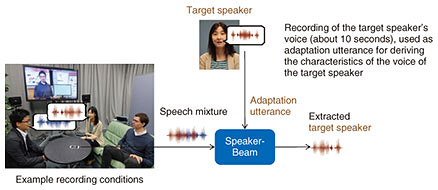
1. IntroductionAutomatic speech recognition technology has progressed greatly in recent years, thus enabling the rapid adoption of speech interfaces in smartphones or smart speakers. However, the performance of current speech interfaces deteriorates severely when several people speak at the same time, which often happens in everyday life, for example, when we take part in discussions or when we are in a room where a television is on in the background. The main reason for this problem arises from the inability of current speech recognition systems to focus solely on the voice of the target speaker when several people are speaking [1]. In contrast to current speech recognition systems, human beings have a selective hearing ability (see Fig. 1), meaning that they can focus on speech spoken by a target speaker even in the presence of noise or other people talking in the background by exploiting information about the characteristics of the voice and the position of the target speaker.
Previous attempts to replicate computationally the human selective hearing ability used information about the target speaker position [1]. With these approaches, it is hard to focus on a target speaker when the speaker’s position is unknown or when he/she moves, which limits their practical usage. We have proposed SpeakerBeam [2], a novel approach to mimic the human selective hearing ability that focuses on the target speaker’s voice characteristics (see Fig. 2). SpeakerBeam uses a deep neural network to extract speech of a target speaker from a mixture of speech signals. In addition to the speech mixture, SpeakerBeam also inputs the characteristics of the target speaker’s voice so that it can extract speech that matches these characteristics. These voice characteristics are computed from an adaptation utterance, that is, another recording (about 10 seconds long) of the target speaker’s voice.
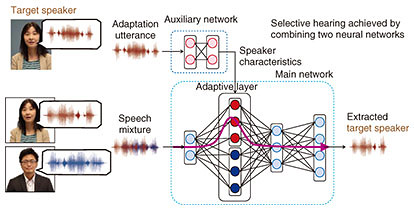
Consequently, SpeakerBeam enables the extraction of the voice of a target speaker based solely on the target speaker’s voice characteristics without knowing his/her position, thus opening new possibilities for the speech recognition of multi-party conversations or speech interfaces for assistant devices. In the remainder of this article we briefly review conventional approaches for selective hearing. We then detail the principles of the proposed SpeakerBeam approach and present experimental results confirming its potential. We conclude this article with an outlook on possible applications of SpeakerBeam and future research directions. 2. Conventional approaches for computational selective hearingMuch research has been done with the aim of finding a way to mimic the selective hearing ability of human beings using computational models. Most of the previous attempts focused on audio speech separation approaches that separate a mixture of speech signals into each of its original components [1, 3]. Such approaches use characteristics of the sound mixture such as the direction of arrival of the sounds to distinguish and separate the different sounds. Speech separation can separate all the sounds in a mixture, but for this purpose it must know or be able to estimate the number of speakers included in the mixture, the position of all the speakers, and the background noise statistics. These conditions often change dynamically, making their estimation difficult and thus limiting the actual usage of the separation methods. Moreover, to achieve selective hearing, we still need to inform the separation system which of the separated signals corresponds to that of the target speaker. 3. Principles of SpeakerBeamSpeakerBeam focuses on extracting only the target speaker instead of separating all components in the mixture. By focusing on the simpler task of solely extracting speech that matches the voice characteristics of the target speaker, SpeakerBeam avoids the need to estimate the number of speakers, the position, or the noise statistics. Moreover, it can perform target speech extraction using a short adaptation utterance of only about 10 seconds. SpeakerBeam is implemented by using a deep neural network that consists of a main network and an auxiliary network as described below and shown in Fig. 3.
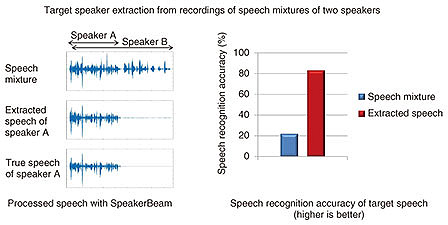
(1) The main network inputs the speech mixture and outputs the speech that corresponds to the target speaker. The main network is a regular multi-layer neural network with one of its hidden layers replaced by an adaptive layer [4, 5]. This adaptive layer can modify its parameters depending on the target speaker to be extracted; namely, it can change its parameters depending on the characteristics of the voice of the target speaker provided by the auxiliary network. (2) The auxiliary network is a multi-layer neural network that inputs a recording of only the voice of the target speaker (adaptation utterance) that is different from that in the speech mixture. The auxiliary network outputs the characteristics of the voice of the target speaker. These two networks are connected to each other and trained jointly to optimize the speech extraction performance. Training the auxiliary network jointly with the main network enables the system to learn automatically from data the features that best characterize the target speaker’s voice, thus avoiding the complex task of manually engineering features characterizing the target speaker’s voice. Moreover, by training the network with a large amount of training data covering various speakers and background noise conditions, SpeakerBeam can learn to achieve selective hearing even for speakers that were not included in the training data. Details of the network architecture and training procedure are explained in our published report [2]. 4. Performance of SpeakerBeamWe conducted experiments to evaluate the speech extraction performance of SpeakerBeam and its impact on speech recognition [2]. We used a corpus consisting of sentences read from English newspaper articles and created artificially mixtures of two speakers. Although SpeakerBeam can work with a single microphone, it achieves better performance when using more microphones. In this experiment, we used eight microphones and combined SpeakerBeam with microphone array processing (i.e., beamforming). An example of processed speech using SpeakerBeam and the speech recognition accuracy obtained when recognizing mixtures of two speakers with SpeakerBeam (red bar) and without it (blue bar) are shown in Fig. 4. We observed a 60% relative improvement in speech recognition performance with SpeakerBeam.
SpeakerBeam can also be employed to improve the audible quality. Interested readers can refer to a video [6] to appreciate the target speaker extraction performance in realistic conditions (real recordings in reverberant conditions with music in the background). 5. OutlookSpeakerBeam is a novel approach to perform computational selective hearing that offers several advantages compared to previous approaches. For example, it can track a target speaker regardless of the number of speakers or noise sources in the mixture and regardless of the speaker’s position. This opens new possibilities for speech recognition of multi-party conversations, speech interfaces for assistant devices such as smart speakers, or for voice recorders and hearing aids that could focus on the speech of a target speaker. However, there are some issues that need to be addressed before SpeakerBeam can be widely used. For example, speech extraction performance degrades when two speakers with similar voices speak at the same time. To tackle this issue, we plan to investigate improved target speaker characteristics that could better distinguish speakers and to combine target speaker characteristics with location information such as direction-of-arrival features. AcknowledgmentPart of this development was achieved through a research collaboration with Brno University of Technology in Brno, Czech Republic. References
|
||||||||||||||