|
|||
|
|
|||
       |
Feature Articles: Future Information-processing Infrastructure for Enabling Data-centric Society Vol. 19, No. 2, pp. 47–52, Feb. 2021. https://doi.org/10.53829/ntr202102fa5 Next-generation Data Hub Technology for a Data-centric Society through High-quality High-reliability Data DistributionAbstractNTT Software Innovation Center is researching and developing next-generation data hubs as part of the Innovative Optical and Wireless Network (IOWN) proposed by NTT. These data hubs will safely distribute diverse types of data including confidential data through advanced means of data protection in an environment of high-frequency/large-capacity data traffic. This article outlines the problems involved with data distribution and introduces the technologies for configuring data governance, the main function of a data hub. Keywords: data distribution, data-centric society, data governance
1. NTT’s goal of a data-centric societyThere has recently been an expansion of Internet of Things (IoT) devices thanks to advances in sensing technology and an increase in data sources having broadband connectivity through the launch of 5G (fifth-generation mobile communication) networks. In addition, advances in artificial intelligence (AI) technologies are enabling high-speed processing of data far exceeding the cognitive and processing abilities of humans. As a result, the amount of data generated throughout the world is increasing steadily in a manner that is expected to not only continue but accelerate in the years to come. In addition to using data only within closed organizations such as companies, NTT seeks to achieve a data-centric society in which massive amounts of data will be widely distributed beyond the traditional borders of industries and fields at ultrahigh speeds between autonomously operating AI-based systems. This society will enable the creation of totally new value and development of solutions to social problems through novel combinations of data and expertise. 2. Problems in achieving a data-centric societyHowever, there are two main problems that must be solved to achieve this data-centric society. 2.1 Limits imposed by current data processing architectureData processing is currently executed by individual systems (silos) that differ in terms of purpose and processing method. This silo-oriented architecture results in many copies of the same data in those systems. In a data-centric society in which large volumes of data much greater than current levels are exchanged at ultrahigh speeds between many more entities (humans, systems, devices, etc. that distribute data) than today, this situation will only accelerate, which means that the following problems will arise if the current data-processing architecture continues to be used without modification.
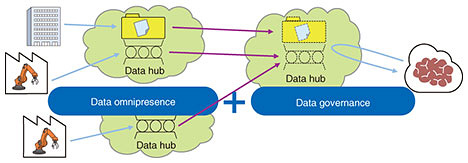
2.2 Resistance to sharing confidential information and expertise with other companiesWhen sharing confidential information and expertise beyond the borders of an organization such as a company, it is common to restrict secondary distribution of shared content or use of that information for purposes other than that agreed upon on the basis of a non-disclosure agreement. However, there are no effective technical mechanisms for preventing secondary distribution or unintended use, so there are limits to enforcing compliance with such an agreement. This has the possibility of hindering a surge in data distribution beyond the traditional borders of industries and fields. 3. Initiatives toward problem solutionsNTT Software Innovation Center aims to solve these problems and achieve a data-centric society by collaborating with various research laboratories including NTT Secure Platform Laboratories to develop next-generation data hubs having the following features (Fig. 1).
3.1 Data omnipresence
3.2 Data governance
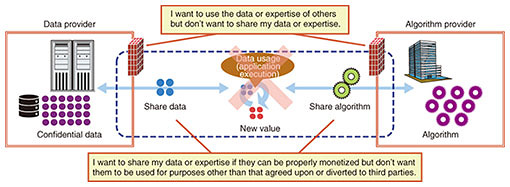
Between these two major functions of data omnipresence and data governance to be provided by next-generation data hubs now under development, the following section mainly describes the technologies for configuring data governance, which are being developed first. 4. Technologies for configuring data governanceAmong the main technologies for configuring data governance, this section mainly describes the data sandbox technology under joint development by NTT Software Innovation Center and NTT Secure Platform Laboratories. This is followed by brief descriptions of mutual-authentication/key-exchange technology and secure-computation AI technology now under development by NTT Secure Platform Laboratories. 4.1 Data sandbox technologyOn achieving a data-centric society in which data and expertise (i.e., for creating an algorithm for giving data value) circulate beyond the borders of an organization such as a company, and new value is obtained by combining those data and expertise, the following can be envisioned in the minds of parties that distribute data and expertise.
The only way for individual companies to address concerns like these was to draw up and conclude a non-disclosure agreement—a time-consuming process—and place trust in each other. This type of countermeasure, however, has the potential of hindering the distribution of data beyond the organization (Fig. 2).
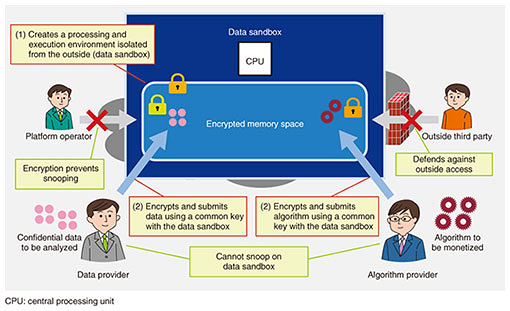
The question, then, is how to provide a systematic and technical means of defense against the above concerns instead of a defense based on agreements and mutual trust. The answer is the data sandbox technology developed by NTT Software Innovation Center. The operation of data sandbox technology can be summarized as follows. (1) An isolated processing and execution environment called a data sandbox is created on a third-party platform such as a cloud operator that is not a party to data distribution. The data sandbox appropriately restricts communication with the outside and encrypts memory/disk space. The platform operator cannot break this encryption (Fig. 3).
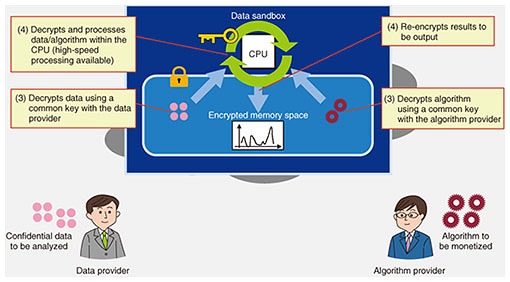
(2) Given a data provider having data to be analyzed using another company’s algorithm and an algorithm provider monetizing algorithms and providing them to another company, each of these parties generates a common key with the data sandbox and places the encrypted data or algorithm in the data sandbox using that common key. The common key used by the data provider differs from that used by the algorithm provider, thereby preventing the viewing of each other’s data or algorithm. The data sandbox also restricts communication with the outside to prevent the data provider and algorithm provider from looking inside the data sandbox while allowing each to only input its data or algorithm (Fig. 3). (3) The data sandbox decrypts the data and algorithm using common keys with the data provider and algorithm provider. Memory/disk space in the data sandbox is encrypted, which prevents the platform operator from viewing the data or algorithm (Fig. 4).
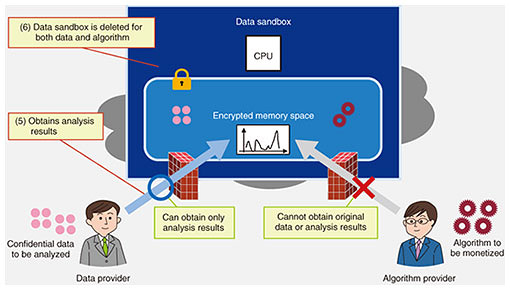
(4) The data sandbox performs processing using the data and algorithm. At this time, the data and algorithm in memory/disk space are decrypted only within the central processing unit (CPU) and processed in plain text to enable high-speed processing. The results of processing are again encrypted in memory/disk space when leaving the CPU (Fig. 4). (5) The data sandbox returns only the processing results to the data provider. Since communications with the outside are appropriately restricted, the algorithm provider cannot get hold of the original data or analysis results even if it willfully or mistakenly submits a malicious algorithm (Fig. 5).
(6) The data sandbox is deleted with the data and algorithm after completing processing (Fig. 5). A party with access to data distribution that uses a data sandbox operating as described above can benefit in the following ways:
4.2 Mutual-authentication/key-exchange technologyNext-generation data hubs will make it possible to instantly share data located anywhere in the world, but they will also require the means of encryption so that only data users approved by the data provider will be able to reference that data. Mutual-authentication/key-exchange technology enables a data provider and data user to verify each other’s identity, attributes, etc. and exchange keys for encrypting and decrypting data without being observed by other parties. This enables safe data sharing only with desired parties. We can expect next-generation data hubs to be connected to IoT devices that will exist in vastly greater numbers than today, which will make it possible to provide massive amounts of real-world data. For this reason, we are developing mutual-authentication/key-exchange technology that requires a minimal amount of computing resources and transmission bandwidth. We can also expect many parties connected to next-generation hubs to provide and use data in a mutually interactive manner. To handle this scenario, we are developing this technology to efficiently execute mutual authentication and key exchange not on a one-to-one basis but among many parties and that can flexibly update keys in accordance with the increase or decrease in the number of parties sharing and using data. 4.3 Secure-computation AI technologyEven if a safe execution environment can be assumed, there will still be not a small amount of data for which decryption is not allowed due to data providers that are uneasy about data decryption or legal restrictions. Secure-computation AI technology enables training and prediction through machine learning with absolutely no decryption of encrypted data. It enables execution of the entire flow from data registration and storage to training and prediction without disclosing the content of that data to anyone. The end result is safe distribution and use of corporate confidential information or information restricted due to privacy concerns. This technology also makes it possible to combine and use data from multiple providers or different types of data in encrypted form. We therefore expect secure-computation AI technology to not only improve the safety of original data but to also enable new value to be uncovered due to an increase in the types and quantities of data targeted for analysis. 5. Toward the futureThis article focused on the data-governance function of next-generation data hubs we are now developing. Going forward, we are looking to accelerate this development initiative toward the practical deployment of next-generation data hubs through the development of data omnipresence, which is the other major function of next-generation data hubs, seamless linking of data omnipresence and data governance, and achievement of large-capacity and low-latency capabilities by linking with the All-Photonics Network, a major component of IOWN (Innovative Optical and Wireless Network). |
||