|
|||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||
       |
Feature Articles: Technology Development for Achieving the Digital Twin Computing Initiative Vol. 20, No. 3, pp. 21–25, Mar. 2022. https://doi.org/10.53829/ntr202203fa3 Technologies for Achieving Another MeAbstract“Another Me,” a grand challenge of Digital Twin Computing announced by NTT in 2020, aims to achieve the existence as a person’s alter ego that appears to have the same intelligence and personality as an actual human and is recognized and active in society as that person. As the first step in achieving this, we constructed a digital twin that acts like the represented person and is capable of asking questions in line with the viewpoints held by that person. This article describes in detail the main technologies behind Another Me, namely, question-generation technology, body-motion-generation technology, and dialogue-video-summarization technology. Keywords: Digital Twin Computing, grand challenges, Another Me
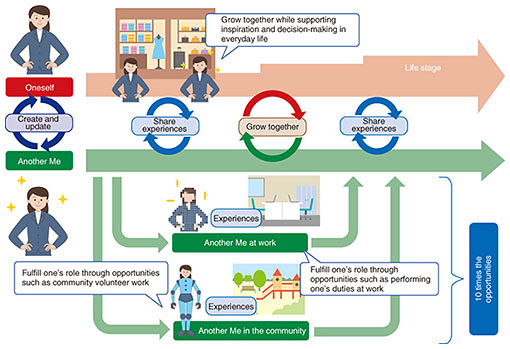
1. IntroductionThe loss of various opportunities in one’s life is becoming a social problem, such as the inability to participate in society despite an interest or desire to do so, possibly due to the difficulty of balancing childcare or caregiving of elderly family members with work. To dramatically increase the opportunities for a person to become more active and grow while expanding and merging the range of activities from the real world to the virtual world, we are taking up the challenge of achieving Another Me as a digital version of oneself [1, 2] (Fig. 1). Another Me will be able to participate actively as oneself in a way that transcends the limitations of the real world and share the results of such activities as experiences of oneself. There are three key technical issues surrounding this challenge: the ability to think and act autonomously as a human, the ability to have a personality like the represented person, and the ability to give feedback on the experiences obtained by Another Me. In this article, we describe in detail the main technologies for addressing these issues: question-generation technology, body-motion-generation technology, and dialogue-video-summarization technology.
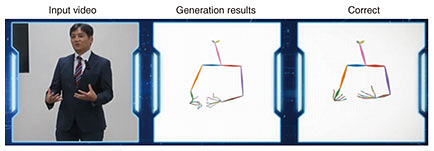
2. Question-generation technologyTo get Another Me to act autonomously, the digital twin must be able to make decisions about its next action. A means of collecting information as decision-making material is essential for this to be possible. We developed question-generation technology focusing on questions as a means of collecting information. Given input in the form of documents or text of conversations, this technology can automatically generate questions evoked by that input text. Generating questions and obtaining the answers to them in this manner enables a digital twin to autonomously collect information that it lacks. Question-generation technology differs from current question-generation technology in two ways. First, the content of questions to be generated can be controlled by viewpoint. A person’s values and position in life are greatly reflected by the questions that the person asks. Taking as an example an internal memo circulated within a company for decision-making purposes, we can expect the sales department to ask many questions about prices and costs, while a review by the legal department would likely include many questions related to legal compliance. By inputting a viewpoint label simultaneously with text, the question-generation technology can generate questions corresponding to the input viewpoint. For example, inputting “money” as a viewpoint label will generate questions related to an amount of money as in costs, while inputting “law” as a viewpoint label will generate questions related to regulations and compliance. The viewpoint label to be input can be changed depending on the values, affiliated organization, etc. of a digital twin incorporating question-generation technology. This means that the digital twin can ask optimal questions according to its current thoughts and situation enabling it to collect the information needed to make decisions. The question-generation technology can also recognize the input viewpoint and text content to automatically determine whether to generate questions. If content related to the input viewpoint has already been entered, or if an answer can be understood by simply reading the input text, there is a function for blocking the generation of questions. For example, when inputting the viewpoint label “money,” questions related to money will be generated if there are no entries for price, cost, etc., but if there is a sufficient number of entries related to money such as price and cost, no questions will be generated. Therefore, when a digital twin is making decisions, it will ask questions only when having an insufficient amount of information and will quit asking questions and move on to processing for the next decision once it has collected a sufficient amount of information. 3. Body-motion-generation technologyTo obtain the feeling that Another Me has the same personality as an actual person, its appearance is, of course, important, but making voice, way of speaking, and body motion like that person is also important. To date, we have clarified that differences in body motion, such as facial expressions, face and eye movements, body language, and hand gestures, can be felt as differences in personality traits [3] and that those differences can be a significant clue to distinguishing individuals [4]. Giving such body motions to an autonomous system in the manner of Another Me (for example, an interactive agent) and manipulating them accordingly is a difficult technical problem from an engineering standpoint. This problem has so far been addressed in technologies for generating human-like body motion and body motion corresponding to personality traits from utterance text [5, 6]. However, the generation of the same movements as those of a specific, actual person has not yet been achieved. Against this background, we developed technology for automatically generating body motion like that of a real person on the basis of uttered-speech information in the Japanese language. We construct a model for automatically generating body motion like that of an actual person by preparing only video data (time-series data consisting of speech and images) of that person. We then use this model to automatically generate movements like those that person would make when speaking by simply inputting uttered-speech information. The first step for constructing the generation model involves using automatic speech-recognition (ASR) technology to extract utterance text from the voice data included in the video data of the target person when speaking. The positions of joint points on the person’s body are also extracted automatically from the video data. The next step involves training the generation model by using a deep learning method called a generative adversarial network that can generate the positions of body joint points from voice and utterance text. To construct a model during this learning process that can capture even a person’s subtle habits and generate a wide range of movements, we devised a mechanism for achieving high-level resampling of the data during training. As a result, we have achieved the highest level of performance in subjective evaluations with regard to a person’s likeness and naturalness (as of October 2021) [7]. With this technology, we constructed a model for generating body motion using speech in the Japanese language as input. Figure 2 shows an example input video of the target person, results of generating body motion, and actual (correct) body motion from the input video.
This body-motion-generation technology can automatically generate body motion of a particular person in Another Me, computer-graphics characters, humanoid robots, etc. It can also easily generate avatar body motions of a particular person in a web meeting from only uttered-speech information. We plan to construct a model that can train a body-motion-generation model from a small amount of data and develop generation technology that can achieve a better likeness of an existing person. 4. Dialogue-video-summarization technologyDialogue-video-summarization technology summarizes recorded dialogue over a length of time shorter than the actual meeting and generates video not only of the content of that dialogue but also of the atmosphere of the place where the dialogue occurred. Our aim is to achieve a society in which humans and Another Me can grow together. It will not be sufficient to simply use Another Me as a surrogate for oneself—it will also be necessary to efficiently feed the experiences obtained by Another Me back to oneself. It will also be necessary to convey not only the content of what Another Me does but also the emotions likely to be felt at that time and at that place so that the represented person can treat what Another Me does as one’s actions. We are researching dialogue-video-summarization technology targeting dialogue as one technology for feeding back the experiences of Another Me to the represented person. As the first step in this research, we are taking up dialogue-condition-estimation technology and video-summarizing technology to enable efficient reviews of meetings. These combined technologies analyze and reconfigure the video of a meeting taken with a small camera or obtained from a web meeting and generate a video summary. (1) Dialogue-condition-estimation technology This technology uses a collection of information in various forms (multimodal information) such as the speech and behavior of the speaker including video of the dialogue as a clue to estimating diverse dialogue conditions. These include the importance and persuasiveness of each utterance, the intention and motivation of utterances, the personality traits and skills of individual participants, and the role of participants within the conversation [8–13]. The technology constructs a highly accurate estimation model by using a variety of machine-learning techniques. These include a multimodal deep-learning technique, which collects a variety of information such as the temporal change in the behavior of each participant, synchronization of movements among participants, change in the speaker’s voice, and content of utterances for learning purposes, and a multitask-learning technique that simultaneously estimates multiple dialogue conditions. (2) Video-summarizing technology This technology uses the results of estimating various dialogue conditions obtained with the technology described above to extract important comments, questions asked of other participants, and comments made in reaction to other participants’ opinions and reconfigure the meeting video to a shorter video of about one fourth the actual time. Subtle nuances of a participant’s comments can be conveyed by the facial expressions or the tone of voice of that participant included in the summarizing video. This dialogue-video-summarization technology enables a user to efficiently grasp in a short period the flow of a discussion, state of participants (e.g., an approving or opposing attitude to an opinion), and atmosphere (energy level) of the meeting that one was unable to attend. Our future goal is to summarize and convey not only dialogue among humans but also between a human and digital twin and even among digital twins. In the area of digital-twin behavior beyond dialogue, we aim to research techniques for feeding back information to humans in a more efficient manner with a higher sense of presence. References
|
||||||||||||||||||||||||||||