|
|||||||||||||||||||||
|
|
|||||||||||||||||||||
       |
Regular Articles Vol. 20, No. 7, pp. 89–95, July 2022. https://doi.org/10.53829/ntr202207ra1 Unsupervised Depth and Bokeh Learning from Natural Images Using Aperture Rendering Generative Adversarial NetworksAbstractHumans can estimate the depth and bokeh effects from a two-dimensional (2D) image on the basis of their experience and knowledge. However, computers have difficulty in doing this because they logically cannot have such experience and expertise. To overcome this limitation, a novel deep generative model called aperture rendering generative adversarial network (AR-GAN) is discussed. AR-GAN makes it possible to control the bokeh effects on the basis of the predicted depth by incorporating an optical constraint of a camera aperture into a GAN. During training, AR-GAN requires only standard 2D images (such as those on the web) and does not require 3D data such as depth and bokeh information. Therefore, it can alleviate the application boundaries that come from the difficulty in collecting 3D data. This technology is expected to enable the exploration of new possibilities in studies on 3D understanding. Keywords: generative adversarial networks, unsupervised learning, depth and bokeh
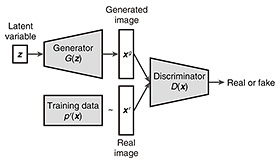
1. IntroductionHumans can estimate the depth and bokeh (shallow depth-of-field (DoF)) effects from a two-dimensional (2D) image on the basis of their experience and knowledge. However, computers have difficulty in doing this because they logically cannot have such experience and expertise. However, considering that, in the future, robots will be able to move around us and the real and virtual worlds will be integrated, it will be necessary to create computers that can act or present information on the basis of 3D data such as depth and bokeh information. Considering that a photo is one of the most frequently used forms of data for recording or saving information, understanding 3D information from 2D images will be valuable for various 3D-based applications to reduce installation cost because it enables using easily available 2D images as input. Three-dimensional understanding from 2D images has been actively studied in computer vision and machine learning. A successful approach is to learn the 3D predictor using direct or photometric-driven supervision after collecting pairs of 2D and 3D data [1] or sets of multi-view images [2]. This approach demonstrates good prediction accuracy due to the ease of training. However, collecting pairs of 2D and 3D data or sets of multi-view images is not always easy or practical because they require special devices such as a depth sensor or stereo camera. To reduce the data-collection costs, our team is investigating a fully unsupervised approach for learning 3D representations only from images without any additional supervision. In the study published in the 34th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2021) [3], I introduced a new deep generative model called aperture rendering generative adversarial network (AR-GAN), which can learn depth and bokeh effects from standard 2D images such as those on the web. Focus cues that are inherent in photos but had not been actively studied in previous deep generative models were considered. On the basis of this consideration, our team developed AR-GAN to incorporate aperture rendering (particularly light field aperture rendering [4]) into a GAN [5] (a variant of deep generative models). This configuration allows synthesizing a bokeh image on the basis of the predicted depth and all-in-focus (deep DoF) image using a camera with an optical constraint on the light field. The rest of this article is organized as follows. In Section 2, I first review two previous studies on which AR-GAN is based: GAN [5] and light field aperture rendering [4]. In Section 3, I explain AR-GAN, which is the main topic of this article. In Section 4, I discuss the experiments on the effectiveness of AR-GAN. In Section 5, I present concluding remarks and areas for future research. 2. Preliminaries2.1 GANGANs [5] can mimic training data without defining their distribution explicitly. This property enables GANs to be applied to various tasks and applications in diverse fields. As shown in Fig. 1, a GAN is composed of two neural networks: a generator where, given a latent variable
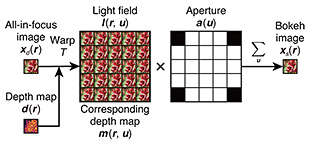
2.2 Light field aperture renderingLight field aperture rendering [4] is a module that simulates an optical phenomenon (particularly bokeh) on a camera aperture in a differentiable manner. Note that such a differentiable property is necessary for deep neural networks (DNNs), such as a More concretely, as shown in Fig. 2, the rendering provides an aperture renderer
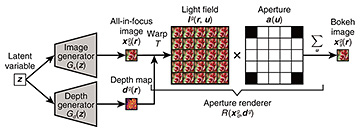
I explain the details in a step-by-step manner. First, a depth map where From this formulation, the left-side images in the light field (5 × 5 images in Fig. 2) represent images when viewing objects from the left side, and the right-side images represent vice versa. Finally, the When an object is on the focal plane, the object’s position is consistent regardless of the 3. AR-GAN3.1 Problem statementThe problem statement is clarified before explaining the details of AR-GAN. As described in Section 1, AR-GAN is used to learn depth and bokeh effects only from images without additional supervision. In this setting, it is not easy to construct a conditional generator that directly predicts the depth or bokeh effects from an image due to the absence of pairs of 2D and 3D data or sets of multi-view images. Therefore, as an alternative, the aim is to learn an unconditional generator that can generate a tuple of an all-in-focus image AR-GAN uses focus cues as a clue for addressing this challenge. When the training images are highly biased in terms of bokeh effects (e.g., all training images are all-in-focus), it is difficult to gain focus cues from the images. Therefore, it is assumed with AR-GAN that the training dataset includes various bokeh images. Note that this assumption does not mean that the training dataset contains sets of different bokeh images for each instance. Under this assumption, AR-GAN learns the generator in a wisdom of crowds approach. 3.2 Model architectureThe processing flow of the AR-GAN generator is presented in Fig. 3. Given a latent variable
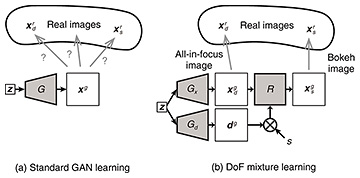
3.3 Training methodAs shown in Fig. 1, a typical GAN applies a To alleviate this problem, AR-GAN is trained using DoF mixture learning. Figure 4 illustrates the comparison between the standard GAN learning and DoF mixture learning. In the standard GAN learning shown in Fig. 4(a), the
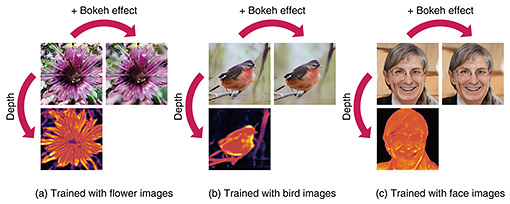
By contrast, as shown in Fig. 4(b), in DoF mixture learning, the AR-GAN generator attempts to represent the real image distribution using generated images, the bokeh degrees of which are adjusted by a scale factor s. More concretely, the GAN objective function presented in Section 2.1 is rewritten as follows: where s ∈ [0, 1]; when s = 0, an all-in-focus image A remaining challenge specific to unsupervised depth and bokeh learning is the difficulty in distinguishing whether blur occurs ahead of or behind the focal plane. For this challenge, on the basis of the observation that the focused image tends to be placed at the center of a photo, AR-GAN uses the center focus prior, which encourages the center to be focused while promoting the surroundings to be behind the focal plane. In practice, this prior is only used at the beginning of training to determine the learning direction. 4. Experiments4.1 Image and depth synthesisThe previous AR-GAN study [3] demonstrated the utility of AR-GAN using various natural image datasets, including flower (Oxford Flowers [6]), bird (CUB-200-2011 [7]), and face (FFHQ [8]) datasets. The implementation details are omitted because of space limitations. See that AR-GAN study [3] if interested in the implementation details. Figure 5 shows examples of generated images and depth maps. AR-GAN succeeds in generating a tuple of an all-in-focus image (upper left), bokeh image (upper right), and depth map (lower left) in every setting. For example, in Fig. 5(a), the background is blurred while the foreground is unchanged in bokeh conversion (the conversion from the upper left to upper right). In depth prediction (the transformation from the upper left to lower left), the depth map (lower left) corresponding to the image (upper left) is successfully predicted. A light color indicates the foreground while a dark color indicates the background. Recall that the training data are only 2D images, and depth and bokeh effects are not provided as supervision. In this manner, learning depth and bokeh effects only from 2D images is the main strength of AR-GAN.
4.2 Application to bokeh rendering and depth predictionAs discussed in Section 3.1, AR-GAN learns an unconditional generator that generates a tuple of an all-in-focus image Figure 6 shows example results obtained with the bokeh renderer and depth predictor mentioned above. A photo I took was used as an input (Fig. 6(a)). The bokeh renderer synthesizes a bokeh image (Fig. 6(b)), and the depth predictor predicts a depth map from the input image (Fig. 6(c)). Similar to the results in Fig. 5, the background is blurred while the foreground remains unchanged in the bokeh conversion (the conversion from (a) to (b)), and the depth map corresponding to the input image is predicted in the depth prediction (the transformation from (a) to (c)).
Note that the data required for training the bokeh renderer and depth predictor are only the data generated by AR-GAN, and no additional data are needed. That is to say, in this setting, we can learn a bokeh renderer and depth predictor in a fully unsupervised manner, similar to AR-GAN. This is a strength of an AR-GAN-based approach. 5. Conclusion and future workThis article explained AR-GAN, which is a new deep generative model enabling the unsupervised learning of depth and bokeh effects only from natural images. Since we live in the 3D world, human-oriented computers are expected to understand the 3D world. For this challenge, AR-GAN is effective because it can eliminate the requirement of 3D data during training. AR-GAN is expected to enable the exploration of new possibilities in studies on 3D understanding. AR-GAN will also be useful for many applications in various fields such as environmental understanding in robotics, content creation in advertisements, and photo editing in entertainment. For example, AR-GAN can learn a data-driven model from collected images. Using this strength, a data-driven bokeh renderer reflecting a famous photographer can be constructed if we can collect his/her photos. Thus, AR-GAN can be used to obtain more natural and impactful bokeh images and enrich the functionality of photo-editing applications (e.g., smartphone applications for social media). Future work includes further improvement of depth and bokeh accuracy since unsupervised learning of depth and bokeh effects is an ill-posed problem, and there is room for improvement. Our team is tackling this challenge, and my latest paper [9] has been accepted to CVPR 2022. Due to space limitations, details of this are omitted. Please check my latest paper [9] if interested in the details. References
|
||||||||||||||||||||