|
|||||||||||||||||||||
|
|
|||||||||||||||||||||
       |
Feature Articles: Efforts to Implement Digital Twin Computing for Creation of New Value Vol. 21, No. 4, pp. 26–31, Apr. 2023. https://doi.org/10.53829/ntr202304fa3 Creating “Shido Twin” by Using Another Me TechnologyAbstract“Cho Kabuki 2022 Powered by NTT,” a kabuki play sponsored by Shochiku Co., Ltd., is the first social implementation of Another Me, a technology for creating a human digital twin that reproduces the appearance and internal aspects of a real person while acting autonomously. We created a digital twin of the star of Cho Kabuki, Shido Nakamura, and call it “Shido Twin,” which performed in the play alongside virtual diva Hatsune Miku. This article overviews this initiative and describes the main technologies behind Cho Kabuki 2022, i.e., automatic body-motion generation and deep neural network-based text-to-speech synthesis. Keywords: digital human, AI, kabuki
1. IntroductionAnother Me, one of the grand challenges concerning Digital Twin Computing (DTC), aims to extend opportunities for self-realization and personal growth beyond constraints such as time, space, and handicaps by having a digital twin of a real person act in place of that person in society. We have set identity, autonomy, and oneness (Fig. 1) as requirements for creating one’s Another Me and are researching and developing technologies to satisfy those requirements.
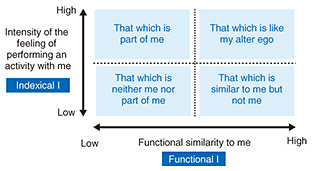
For a person’s Another Me to act as that person in society, it must first have identity, which means that it is recognized as that person by reproducing their external characteristics, such as appearance and movements, as well as their internal aspects, such as personality and values. To overcome time, physical, and cognitive handicaps, one’s Another Me must then have autonomy so that it can understand situations, make judgments, and act in the same way as the person it represents without that person having to operate or give instructions at every step. To acquire a sense of accomplishment through self-realization and personal growth from the results of the activities of one’s Another Me that fulfill the first-two requirements, it is necessary to maintain oneness between the person and their Another Me by feeding back the results to the person with a real feeling as if that person had experienced them. 2. Initiative to create Shido TwinAn entity that completely satisfies all three requirements can be called Another Me; however, in reality, it is necessary to determine which requirements should be satisfied to what extent in accordance with the application area of that entity. Taking the first step in the social implementation of Another Me, we focused on creating identity and took on the challenge of recreating an actor on a theater stage as a venue for this creation. In cooperation with Shochiku Co., Ltd., which has been working on “Cho Kabuki”—combining kabuki (Japan’s traditional theater) and NTT’s latest technologies, i.e., automatic body-motion-generation and deep neural network (DNN) text-to-speech (TTS) synthesis, we created a digital twin (called Shido Twin) of the star of Cho Kabuki, Shido Nakamura, and had Shido Twin greet the audience in place of him. Since many in the audience of Cho Kabuki are fans of Shido Nakamura and Cho Kabuki, satisfying the demand of a high level of personal identity, especially in terms of external appearance, is challenging. That demand leads to the question of what does it mean to recognize the identity of an entity such as Another Me that is not the actual person? We have explored this question through co-creation with experts in philosophy and have come to understand identity along two axes: “Functional I” and “Indexical I” (Fig. 2).
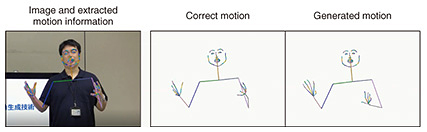
Functional I refers to the fact that a person’s external characteristics, such as appearance and movement, as well as skills and abilities, are the same as those of the person in question. In consideration of this fact, this project involved about half a day of studio recording to create an elaborate three-dimensional computer graphics model of Shido Nakamura and construct a machine-learning model that can generate the gestures and voice similar to the actor. In contrast, Indexical I is the idea that Another Me can share indexicality (consciousness that points to the person such as “he,” “she,” and “I”) by making the past experiences that characterize the person felt by Another Me. For the project, targeting fans of Cho Kabuki, we asked Shido Nakamura to perform the gestures and vocalizations that fans have come to know from past Cho Kabuki performances to reproduce the rousing of the audience. Costumes and dialogues that would not be out of place in a traditional cultural setting as well as the interactions with the live performers on stage were finalized after close consultation with Shochiku. The technologies for creating Shido Twin are described in the following sections. 3. Automatic body-motion-generation technology that can reproduce even the most subtle individual habits from a small amount of dataIt is considered important for Another Me to be felt as having the same personality, voice, speech, and body motion of the real person, not to mention appearance. We have previously shown that differences in body motions, such as facial expressions, facial and eye movements, and body gestures, are major cues for perceiving differences in personality traits [1] and identifying others [2]. It is therefore important to control the motion of Another Me so that it automatically generates the body motion of the person in question, which is a difficult technical challenge from an engineering standpoint. We have been investigating technologies for generating human-like body motions and body motions based on personality traits from spoken text [3, 4]; however, we have not been able to generate motions that can mimic the subtle habits of a specific person in real life. We developed a technology for automatically generating body motions, in a manner that mimics the subtle habits of a real person during speech, on the basis of Japanese speech and its textual information. Simply by preparing video data (time-series data of audio and body images) of a real person, it is possible to construct a generative model that automatically generates body motions that are typical of that person. By using this generative model, a user can automatically generate a person-specific behavior during speech by simply inputting speech sounds and their text information. First, speech-recognition technology is used to extract speech text from the speech data contained in the video of the target person, and the positions of joints of the body are automatically extracted from the image data. Next, a deep-learning generative model called a GAN (generative adversarial network), which can generate the positions of joints of the body from speech and speech text, is trained. To construct a model that can generate a wide range of motions by capturing even the most detailed habits of a person during training, we devised a mechanism for appropriately resampling the training data during training and have maintained the world’s highest performance in subjective evaluation of human-like qualities and naturalness (as of November 2022) [5]. With this technology, we constructed a model for generating body motions by using Japanese speech as input. Examples of the input video of the person, result of body-motion generation, and actual correct body motion in the input video are shown in Fig. 3. We are also currently developing a learning method using the mechanism few-shot learning that can train models with only a small amount of data and without using a large amount of video data (training data) from a specific individual. With this method, we constructed a motion-generation model that can reproduce even the most subtle habits of Shido Nakamura from a small amount of video data (approximately 10 minutes) of him speaking and used the motion-generation results to control the motion of Shido Twin.
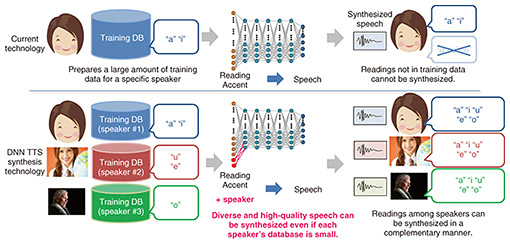
4. Saxe, a low-cost DNN TTS synthesis engine that reproduces a variety of speakers and tonesVoice is one of the most-important elements in reproducing a person’s personality. TTS synthesis technology should be able to reproduce the desired speaker’s voice with high accuracy. However, generating high-quality speech of a desired speaker requires a large amount of speech data uttered by that speaker, for example, up to 20 hours to produce high-quality synthesized speech with the concatenative TTS method Cralinet [6]. Consequently, the cost of recording voices and constructing databases has been a major issue in regard to achieving TTS of desired speakers. To address this issue, we developed a TTS engine called Saxe, which is based on a DNN [7]. Saxe uses a speech database (built from the utterances of a large number of speakers) and deep learning to synthesize high-quality speech of the desired speaker from a small amount of speech data. The characteristic feature of Saxe is that a large amount of speakers’ speech data is modeled with a single DNN (Fig. 4). Information necessary for speech production, such as pronunciation and accent, is learned from a large amount of pre-prepared speech data, and the speaker characteristics of a desired speaker are learned from a small amount of speech data of the desired speaker. It is thus possible to generate high-quality speech even with a small amount of speech data of the desired speaker.
It is also important to reproduce the performance as well as the voice of the person by reproducing speech features, such as inflection and speech rhythm, as well as the tone of the voice. However, very specific articulations, such as those used in acting, make it very difficult to reproduce speech rhythms from a small amount of speech data. In response to this difficulty, we are developing a technology for extracting inflection and speech rhythm from a small amount of speech data of a desired speaker. When a small amount of speech is input to the DNN, the DNN outputs a low-dimensional vector of the inflection and speech rhythm of that speech [8]. During speech synthesis, the resulting low-dimensional vectors are combined with the aforementioned speech-synthesis DNN to generate synthesized speech with the desired tone, inflection, and speech rhythm of the speaker’s voice. 5. Concluding remarksShido Twin created with these technologies performed in “How to Appreciate Cho Kabuki,” an explanation of the appeal of Cho Kabuki, as one of the performances in “Cho Kabuki 2022 Powered by NTT,” and it was well received [9]. This initiative showed that the Another Me technology can reproduce identity at a quality that can satisfy the demands of commercial performances. We will continue to develop the identity and autonomy of Shido Twin and strive to demonstrate the social value of Another Me in a variety of settings. References
|
||||||||||||||||||||