|
|||||||||||||
|
|
|||||||||||||
       |
Feature Articles: Recent Developments in the IOWN Global Forum Vol. 22, No. 2, pp. 34–40, Feb. 2024. https://doi.org/10.53829/ntr202402fa4 IOWN Data Hub to Become a RealityAbstractThe IOWN Global Forum is working on the social implementation of the Innovative Optical and Wireless Network (IOWN) technology. This article introduces the progress of the storage service study in the IOWN Global Forum, focusing on the newly published IOWN Data Hub Functional Architecture version 2.0 and the Proof of Concept Reference and NTT laboratories’ activities related to the IOWN Data Hub. Keywords: storage, database, virtual data lake
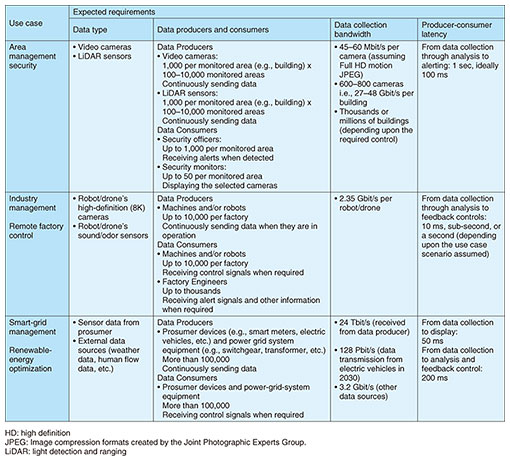
1. Background of the need for IOWN Data HubIntegrating the real and virtual worlds and feeding the results of simulations in the virtual world back to the real world in real time can provide many benefits, such as the ability to detect and quickly respond to hazards and maintain a comfortable environment with minimal changes. However, to achieve this integration, it is necessary to synchronize in real time the data and behavior of a vast number of objects sensed in the real world with those in cyberspace. Due to their high latency, current networks cannot synchronize vast amounts of data over a wide area in real time, making it difficult to construct a high-definition digital twin that covers a vast space. To solve this problem, we need the IOWN Data Hub (IDH), a new data-sharing platform built on the Open All-Photonic Network (APN) and data-centric infrastructure (DCI), which are both infrastructures of the Innovative Optical and Wireless Network (IOWN). This article focuses on the update of the IDH architecture document and proof of concept (PoC) activities undertaken to enable the IDH. 2. IDH activities at the IOWN Global ForumIn January 2022, IOWN Global Forum members, including NTT, Oracle, and NEC, collaborated to develop and release IOWN Data Hub Functional Architecture version 1.0. For the basic mechanism and concept of the IDH, refer to “Study of Storage Services at IOWN Global Forum” [1] that can be found in the NTT Technical Review. After the release of the above architecture document, the IOWN Global Forum held a series of discussions toward social implementation, and in July 2023, updated the document to release the IOWN Data Hub Functional Architecture version 2.0 [2]. The main updates are as follows: (1) Specific description of use-case requirements: Identification of data types, bandwidth requirements, etc. for each use case presented in the Cyber-Physical System (CPS) and AI (artificial intelligence) Integrated Communications (AIC) use-case documents [3, 4]. (2) Identification of inherent gaps: Gap analysis based on more specific implementation models. Some of the requirements for the use cases described in update (1) are listed in Table 1. These future use cases will need to meet diverse and demanding data processing and sharing requirements. For example, to meet real-time requirements, it is necessary to process data as-is without any conversion, close to the original data. To handle a large number of data flows, it is necessary to significantly improve distributed data management engines so that they can operate over ultra-high-speed, high-quality networks. Robust data security and data-usage control mechanisms will be required to enable fast and reliable data exchange between multiple parties.
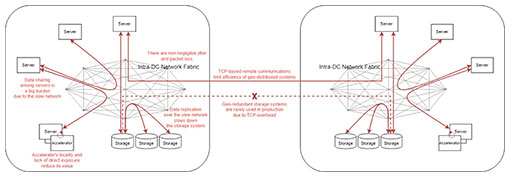
Update (2) identified gaps in the computing environment as well as problems in datacenters (DCs) and models for data sharing and processing models that make up the computing environment. 2.1 Fundamental problems in DCsThe current networks and DC technology have several fundamental problems in the following areas. These must be solved if we are to build IDH services that meet the use-case requirements (Fig. 1).
(1) Inter-DC network quality The network quality between DCs used in today’s cloud is focused on current use cases. Since packet reordering and loss occur in networks, the Transmission Control Protocol (TCP) is used more frequently than other protocols, such as the User Datagram Protocol (UDP), to ensure reliability. These networks do not provide sufficient performance for the workloads of geographically distributed databases and storage systems that are required by the use cases in the IOWN era. (2) Intra-DC network quality The quality of the networks used by hyperscale DCs that make up a cloud are not high enough. For example, one-way latency can exceed 1 ms, a latency sufficiently high to cause packet loss to exceed 1% during severe network congestion. The bandwidth is similarly unstable. This is essentially due to oversubscription, a scheme that allows reservation of bandwidth beyond the capacity of the network devices. Therefore, the network that connects computing resources in a DC cannot guarantee all the bandwidth allocated to individual resources. (3) Storage performance To ensure data persistence, data are typically synchronized across multiple servers. However, synchronization requires a large workload, rendering performance very unstable. Thus, storage systems that are connected via today’s cloud-based storage area networks tend to be slower than directly connected storage devices. For example, the response time of storage systems can exceed dozens of milliseconds, making such systems unsuitable for typical database workloads or redundant storage systems. (4) Data-sharing performance In cases where data are processed cooperatively across multiple servers, a certain amount of data exchange is required between servers, for example, to redistribute data. This exchange significantly reduces overall performance. To speed up such data servers, some implementations connect servers using remote direct memory access (RDMA) fabric connections. However, since the use of RDMA in production environments imposes strict requirements, such as no packet loss and no packet reordering, RDMA is used only for very limited purposes in today’s cloud environments. (5) Accelerator usage Accelerators, such as graphics processing units (GPUs) and field programmable gate arrays (FPGAs), have the potential to achieve high performance, cost-effectiveness, and energy efficiency at least 10 times greater than software-based processing on general-purpose central processing units (CPUs). However, such an accelerator must be deployed within each server and cannot directly access external clients for the purpose of streamlining data loading. Therefore, with current network and DC technologies, it is not possible for multiple general-purpose computing resources to share accelerator resources at high speed and with low overhead. 2.2 Today’s implementation model and inherent gapsConsidering the aforementioned issues, we must accept the following constraints if we are to use today’s technology to provide data services such as the IDH. (1) Completion of data processing within one place If processing efficiency could drop sharply due to poor quality of the network that connects DCs, it would be difficult to implement geographically distributed data services. Therefore, current data-processing services are designed to be implemented within a single DC or within nearby availability zones. In fact, today’s clouds are an aggregation of such services. The size of cloud DCs has become so enormous that the number of available cloud regions is very limited, 30 or so at most worldwide. This means that, regardless of where data were generated, all data must be transferred to one of the cloud DCs and all data processing must be completed there, making the system’s energy use highly inefficient. (2) Asynchronous data replication as a foundation to build a scalable transactional distributed relational database In building a scalable transactional relational database (RDB) system, it is a common practice to place replicated read-only data near each RDB server. Such data replication tends to be asynchronous because the network is slow. To reduce the load imposed on slow networks by data replication, often only the transaction or change logs, rather than the data, are propagated. This improves performance but requires reconstruction of table data from the log data on each server, which inevitably increases the system cost and power consumption. (3) Sharded data processing to build a scalable key-value store, message broker, and/or analytical distributed RDB Sharding is a technology for reducing response time and improving scalability by grouping related data together and distributing it across multiple databases. It is used to build scalable systems, such as a key-value store (KVS). However, it does not eliminate data transfer needed for data relocation and server-to-server communication. Rather, the volume of such data transfer and communication may increase in advanced digital transformation (DX) services that need to handle data from many different angles. Since sharded systems require a certain amount of data transfer between scale-out and scale-in operations, data services in the cloud today experience constraints on dynamically changing scalability. (4) Usage of a cache layer The constraints imposed by low-speed networks and storage systems often make it necessary to manage data on a process-by-process basis and rely heavily on asynchronous distributed processing. To streamline such implementations, various cached data management services are provided in today’s cloud. However, such services increase end-to-end latency and cause the same data to be copied unnecessarily multiple times in the cloud, which is undesirable in terms of cost and energy consumption. (5) Accelerator in use only in a laboratory One possible approach to solving the aforementioned problems is to use accelerators, such as GPUs and FPGAs, to speed up queries and other data processing in distributed RDBs. Software has been developed and validated for such purposes, but in actual practice, the use of such software rarely improves and often diminishes performance and cost-effectiveness. This is mainly due to the need to preload data at the startup of the accelerator. The IDH must be designed to address the fundamental and inherent challenges of today’s cloud system and must be further developed to adapt to use cases of the wide-area and real-time CPSs that will be increasingly demanded in the future. To this end, it is necessary to verify the IDH iteratively in actual use cases and reflect the results to refine the required functions and design methodology of the IDH. 3. PoC activities on the IDHIn October 2022, the IOWN Global Forum formulated the IOWN Data Hub PoC Reference [5] to help implement the IDH. The use of the Open APN will result in a quantum leap in the speed of hybrid and multi-cloud connections, which in turn will cause a shift from concentration in hyperscalers to the use of enterprise DCs and edge clouds. Thus, it will be necessary to innovate data sharing architecture so that it can accommodate this shift. The IDH disaggregates the functions and processing that have previously been executed by hyperscalers in the central cloud and relocates them to edge clouds. To validate and deploy the IDH architecture, in which connections are set up by the Open APN and DCI, in many use cases, the IOWN Global Forum has released this PoC Reference and is seeking participation from a wide range of organizations, not limited to IOWN Global Forum members. 3.1 The IDH PoC ReferenceThis PoC Reference has been formulated to validate the IDH architecture that meets the stringent requirements of various DX services. Smart factory, smart grid, and metaverse have been selected as use-case examples and five PoC scenarios have been defined. To build a metaverse service, for example, it is typically necessary to collect information about the participants, represent them as avatars in the virtual space, and allow the avatars to interact with each other. Thus, provision of a high-quality metaverse service requires the following.
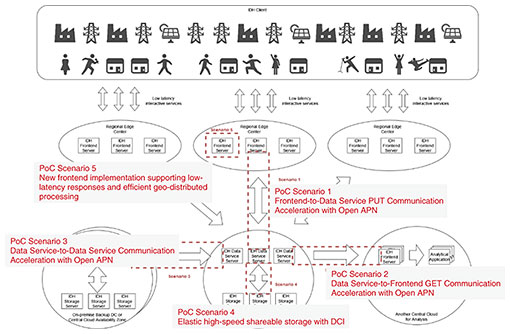
To demonstrate the IDH architecture for supporting such use cases, the PoC Reference defines a test environment that reflects the geographically distributed deployment of assumed IDH services and identifies the items that PoC projects should validate (Fig. 2).
In this model, a subgroup of front-end servers of the IDH architecture is deployed at a regional edge center to provide low-latency services to connected Internet of Things (IoT) devices. The data service servers and storage servers, which are part of the IDH architecture, are deployed at remote DCs or the central cloud to support data persistence and usage. On the basis of this model, the PoC Reference defines the following five PoC scenarios:
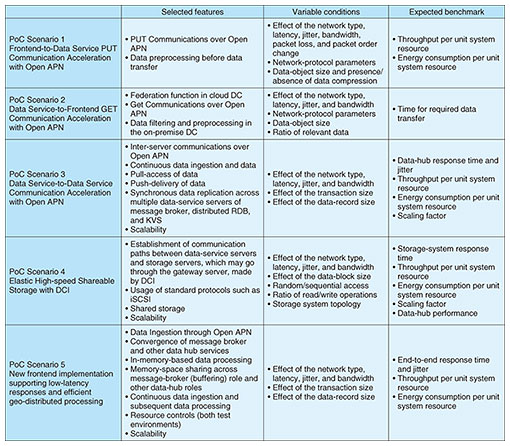
For each scenario, the PoC Reference describes an overview, required functions, variable conditions, and expected benchmarks to enable the readers to proceed with their PoC projects (Table 2).
IOWN Global Forum member companies are currently conducting PoC projects for their respective scenarios on the basis of this PoC Reference. Thus, the IDH is making steady progress toward its social implementation. 4. Activities in the NTT GroupTo contribute to the implementation of the IDH, the NTT Software Innovation Center is developing virtual data lake, which is defined as a set of functions in the IDH reference architecture. There are various stakeholders in both the real world and virtual world, which is built by Digital Twin Computing. To enable the feedback between the two worlds to loop in real time, data must not only be transmitted at high speed but also be securely exchanged between stakeholders who have different standpoints. Therefore, it is essential to enable stakeholders to handle the latest data as if they were at hand, while ensuring permanent governance of the shared data. The virtual data lake being developed by NTT Software Innovation Center virtually aggregates and centralizes omnipresent data that are managed by different organizations and geographically dispersed across multiple locations, enabling data users to acquire and use only the needed data efficiently and on-demand. For this purpose, the virtual data lake provides functions that enable data users to search for and discover the data they need from among a vast amount of data based on metadata (semantic and format information of data) and functions that maintain governance by enabling data users to display and use only those items of data they are permitted to use based on the policies set by data providers. These functions enable organizations to mutually use a large volume of widely varied data quickly, easily, securely, and reliably across organizational boundaries. To make the IDH platform fit for practical use, we will continue to conduct demonstration tests of the platform by referring to the IDH PoC Reference and other reference materials. 5. Future developmentAs a “database is a network” platform that supports Digital Twin Computing that runs on the Open APN and DCI, the IDH is expected to be used for mission-critical use cases such as wide-area automated driving. Together with many partners, NTT will verify various IDH implementation models that satisfy the requirements imposed by use cases in the IOWN era and promote its social implementation. References
|
||||||||||||