|
|||
|
|
|||
       |
Feature Articles: Fixed-mobile Convergence Services with IOWN Vol. 23, No. 1, pp. 29–34, Jan. 2025. https://doi.org/10.53829/ntr202501fa3 Evolution of Fixed-mobile Convergence Networks Made Possible with the Reliable Control Pluggable Network Coordination InfrastructureAbstractFixed-mobile convergence networks are enabled through tight collaboration across multiple domains such as access networks for mobile and fixed networks and datacenter networks. This article introduces the potential network evolution made possible by the Reliable Control Pluggable Network Coordination Infrastructure, which flexibly enables collaboration across network domains and enhances the reliability and quality of the entire network. Keywords: fixed-mobile convergence, network reliability, end-to-end network communication quality
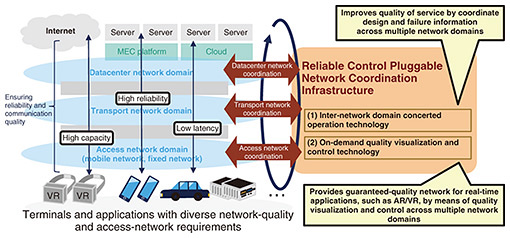
1. Aims with the Reliable Control Pluggable Network Coordination InfrastructureAs the role played by communications carriers in providing social infrastructure expands, it is becoming more critical for networks to guarantee reliability and communication quality. We are seeing an accelerated expansion of new use cases that use multi-access edge computing (MEC) and datacenters of communications carriers to provide services such as automated driving and augmented reality/virtual reality (AR/VR). These trends make it essential that access networks, such as those of mobile and fixed networks owned by communications carriers, and datacenter networks, which are the ultimate destination for connections, can be used in appropriate combinations in accordance with terminal- and application-usage scenarios. A mechanism to ensure reliability and quality over multiple network domains, such as access networks and datacenter networks, is necessary to implement such use cases. To maintain end-to-end reliability and communication quality from terminals connected to access networks to servers and other communication destinations in a network service ecosystem that combines access networks and datacenter networks, rapid recovery in the event of failures that affect multiple network domains or generate alerts must be ensured. It is also important to manage resources and visualize quality across multiple network domains to guarantee end-to-end quality of service. NTT Network Innovation Center has been working on the practical application of network systems for various network domains and operation systems for running them. Building on the network system operation technologies we have cultivated, we are developing the Reliable Control Pluggable Network Coordination Infrastructure, which ensures communication reliability and quality through failure analysis and quality visualization and control across multiple network domains rather than a single network domain (Fig. 1).
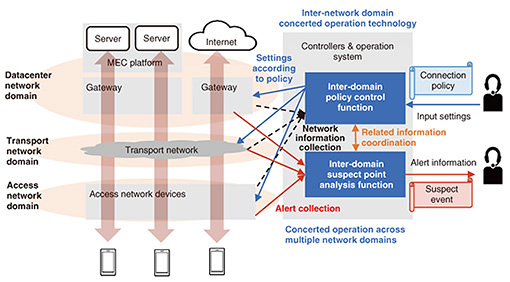
The Reliable Control Pluggable Network Coordination Infrastructure broadly consists of two technologies. One is an inter-network domain concerted operation technology that understands networks across multiple domains and quickly identifies configurations and failures that span multiple domains. The other is an on-demand quality visualization and control technology, which presents estimated factors and time-series information to operators, automatically selects optimal response strategies, and controls network resources. The combined use of these technologies makes it possible to maintain high network quality by efficiently responding to complex failures and quality degradation, which had required time-consuming analysis and response by expert operators. Each of these technologies is described in detail in the following sections. 2. Inter-network domain concerted operation technologyThe inter-network domain concerted operation technology is used when services that span different domains such as datacenter networks to which the MEC platform and cloud computing are connected and access networks of mobile and fixed networks. It provides concerted operation across domains, including the provision of one-stop services through centralized connection policy management across domains and fast recovery from failures through suspect point analysis. It reduces the maintenance personnel workload and improves service quality and reliability. Conventional technology faces two issues in operating services that span multiple domains. The first issue is that conventional network management independently handles each domain. This has the advantages of providing specialized functions on the basis of each domain’s technical requirements and operational policies and simplified management due to the relative ease with which failure localization and management can be achieved. When it is necessary to provide services across multiple domains in an integrated manner, however, the required collaboration between different domains becomes more complicated, increasing the maintenance personnel workload. For example, redundancy arises in configuration work because, when a new service is to be provided, maintenance personnel need to set the same configuration information multiple times, once for each domain. Handling of service orders also becomes more complicated because, when the configuration is changed in one domain, the configurations in other domains need to be changed accordingly. When a terminal is moved to a different network, the access network to which the terminal is connected changes, requiring a change of Internet Protocol address and update of the user application settings. Therefore, the work needed to maintain end-to-end network communication reaches a higher level of complexity. The second issue is that conventional network management handles alerts in each domain separately. Therefore, to identify the cause of a failure, maintenance personnel in different network domains need to collaborate. This increases the overall maintenance personnel workload. Since alerts generated in each domain are managed separately, it is very difficult to analyze how they are related to each other. For example, when a “not-connected” alert occurs in the MEC platform and its root cause is a failure in the cloud to which the MEC platform is connected, it would be impossible to identify the root cause of the failure by analyzing only the alerts on the MEC platform. Hence, the maintenance personnel for each domain need to first analyze alerts independently in each domain then investigate how alerts in different domains are related to each other. The inter-network domain concerted operation technology addresses these two issues. It consists of an inter-domain policy control function and inter-domain suspect point analysis function. Figure 2 shows an overview of this technology. How these functions address each issue is described in the next subsections.
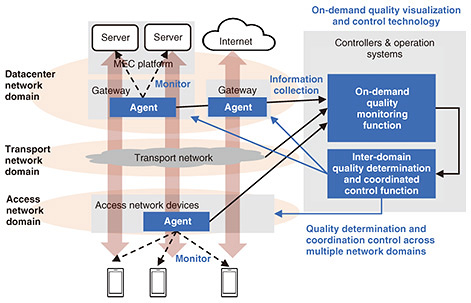
2.1 Inter-domain policy control functionThe inter-domain policy control function addresses the first issue. When services are to be provided across different domains, this function makes it possible to provide one-stop services through centralized connection policy management across domains. When the terminal configuration is changed, this function also makes it possible to change configurations in networks on the basis of collected network information. Maintenance personnel only need to set connection policy information, such as “Connect Terminal A to User Application A.” With only this instruction, the function seamlessly links information across domains and automatically changes settings, resulting in shortened service provisioning time and dramatically improved user convenience. 2.2 Inter-domain suspect point analysis functionThe inter-domain suspect point analysis function addresses the second issue. This function collects alerts from different domains and executes suspect point analysis across these domains. When a failure occurs in a network, this function quickly estimates the cause of the failure and enables fast recovery. When a failure occurs in a cloud service, for example, this function executes integrated analysis that takes into account the relationship with the relevant access and datacenter networks, enabling more appropriate and faster responses than can be achieved using conventional methods. 3. On-demand quality visualization and control technologyThe on-demand quality visualization and control technology is required when end-to-end network services that guarantee the level of network quality required by individual users—in relation to aspects such as bandwidth, delay, and jitter—are to be provided across multiple domains. This technology enables on-demand collection of quality information across a range of quality monitoring item types from a large number of quality monitoring targets, such as terminals. It also enables detection of quality degradation and control for quality maintenance on the basis of the collected information. Conventional technology faces two issues in ensuring end-to-end quality across domains. The first issue is that, in conventional networks, quality types that can be monitored (e.g., communication bandwidth) as well as monitored devices (e.g., terminals that serve as communication endpoints) are fixed. To provide a network that satisfies different specific quality requirements as requested by each network user in relation to aspects such as communication bandwidth, latency, and jitter, it is necessary to monitor the network quality to see whether it satisfies the requested quality requirements. The terminals, servers, and applications to be monitored may also change dynamically depending on the user’s network usage. Therefore, it is necessary to update the monitoring settings for each quality monitoring target accordingly. To respond to these diverse quality requirements and quality monitoring targets, network operators have conventionally had to design and deploy individual monitoring agents that monitor network quality according to the quality requirements of each user and change the settings of individual quality monitoring targets in the agents on the basis of how terminals are connected. These tasks have increased the operations workload. The second issue is that the collection, analysis, and handling of quality-related information is confined to each network domain. When quality degradation is detected through end-to-end quality monitoring, it is necessary to analyze which network domain is experiencing quality degradation and what is causing the degradation and automatically and quickly control the identified domain to maintain quality. In conventional network operation, quality-related information—such as quality monitoring results and facility resource usage in each network domain—is managed separately in the network controller/operation system of each domain to avoid an increase in quality-related specifications, such as quality type, data quantity, and data collection frequency. Therefore, it is difficult to automate quality degradation factor analysis that correlates quality data from different domains. For example, quality degradation detected in one network domain may be due to resource congestion in another network domain. It is also difficult to automatically determine how to respond to the problem. The on-demand quality visualization and control technology addresses these two issues. This technology consists of an on-demand quality monitoring function and inter-domain quality determination and coordinated control function. Figure 3 shows an overview of this technology. How these functions address each issue is described in the next subsections.
3.1 On-demand quality monitoring functionThe on-demand quality monitoring function addresses the first issue. This function automatically designs and deploys a monitoring agent that monitors the quality of each user’s network to see whether it meets the user’s quality requirements and dynamically changes the quality monitoring target settings of the monitoring agent by referring to the terminal authentication information received when the terminal was connected to the network. This eliminates the need for manual design of the quality monitoring function and for configuration of monitoring targets and enables end-to-end quality monitoring according to the quality requirements and network usage conditions of individual users without increasing the operational load. 3.2 Inter-domain quality determination and coordinated control functionThe inter-domain quality determination and coordinated control function addresses the second issue. This function collects from network domains the quality monitoring results and resource information needed for analyzing quality degradation factors and estimates those factors accordingly. In response to the estimation, the function executes configuration control to ensure quality, such as resource allocation to systems and devices in each network domain (i.e., the access network domain or datacenter network domain). This configuration control enables automatic execution of data collection, analysis, and control across multiple domains, actions previously confined to each network domain. It also makes it possible to quickly apply end-to-end quality assurance control. 4. Future prospects for the Reliable Control Pluggable Network Coordination InfrastructureWe will further develop the above two technologies of the Reliable Control Pluggable Network Coordination Infrastructure and proceed with research and development aimed at enhancing the functionality and quality of network services provided in fixed-mobile convergence networks. |
||