|
|||||||||||
|
|
|||||||||||
       |
Feature Articles: Fixed-mobile Convergence Services with IOWN Vol. 23, No. 1, pp. 43–49, Jan. 2025. https://doi.org/10.53829/ntr202501fa5 Power-saving Enabler That Uses Software Technology to Reduce Network Power ConsumptionAbstractThe amount of traffic flowing through networks is increasing yearly, and the increase in power consumption of network devices is becoming an issue. This article introduces research and development efforts to reduce power consumption by using software technology within the context of software processing of networks. Keywords: communication software, power saving, low latency
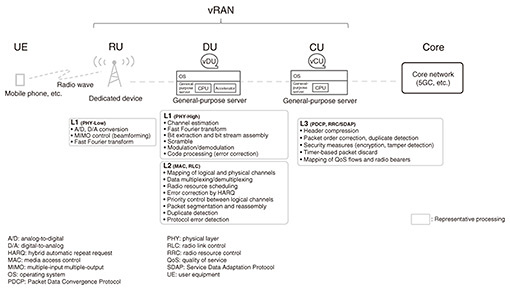
1. Software implementation of network functions and power savingNetwork devices that have been implemented with dedicated hardware are increasingly being replaced by software running on general-purpose servers. This implementation method is often referred to as network function virtualization (NFV). The widespread transition to NFV can be put down to the improved performance of general-purpose central processing units (CPUs) and advances both in software technology for processing communication functions and in virtualization technology. The advantages of NFV are that initial costs for installing hardware devices are low because mass-produced general-purpose servers can be used; the development time for software implementation of functions is shorter than that for hardware circuit design; and flexible operations, such as dynamic configuration changes, are possible. While NFV has many advantages, it also faces challenges. One is how to achieve high performance. With dedicated hardware, the circuit design can be optimized for each application, leading to high processing efficiency and high performance. In contrast, NFV is implemented using software running on a general-purpose server, and the use of such general-purpose hardware often leads to inefficiencies. Therefore, high performance cannot be achieved without innovation. Examples of such innovation includes using a large number of CPUs to continuously monitor packet arrivals and process packets quickly and suppressing CPU hibernation to reduce the overhead of recovery from the hibernation state. However, all these innovations sacrifice power efficiency. There is generally a trade-off between high performance and power saving. This is especially true for systems that require high throughput and low latency. An example of a system that requires high throughput and low latency is a virtual radio access network (vRAN). 2. Introduction to a use case: vRANMobile communication networks use a vast number of wireless base stations to provide communication services across a wide area. The main roles of base stations are to transmit and receive radio waves to and from mobile communication devices for wireless communication and to process radio signals. Base stations are required to provide high throughput and meet very stringent low-latency requirements. For this reason, dedicated hardware optimized for use in base stations has conventionally been used. The advantages of NFV have been studied in vRANs, which operate with software running on a general-purpose server. Figure 1 shows an example of a vRAN system configuration. A RAN consists of three types of functional units: radio units (RUs), distributed units (DUs), and central units (CUs). The functional units being studied for implementation using software running on a general-purpose server are DUs and CUs, which process radio signals. The vRAN transmits and receives radio signals to and from terminals, such as mobile phones. vRAN radio resources are multiplexed in the frequency and time directions, and radio waves are exchanged in time slots of short intervals in microseconds. DUs and CUs must process radio signals without delay within these time slots. Therefore, they need to meet stringent low-latency requirements in microseconds. At the interface between an RU and a DU, called the fronthaul, the DU needs to provide high throughput of more than 20 Gbit/s in the Split 7.2 functional deployment specified by the O-RAN ALLIANCE. It is technically challenging to implement DU or CU functions with software running on a general-purpose server because of the need to achieve throughput exceeding 20 Gbit/s while meeting microsecond-order latency requirements. For example, Linux is widely used as an operating system (OS), and the standard packet transmission and reception mechanism in the Linux kernel can cause delays from several hundred microseconds to milliseconds [1], making it difficult to achieve throughput as high as 20 Gbit/s. Achieving power savings while meeting stringent low-latency and high-throughput requirements is even more technically challenging. For example, many widely used general-purpose CPUs have a function to put themselves into an idle state when there is no task to process, but the overhead required to recover from a deep idle state can exceed 100 microseconds. If a CPU is frequently transitioning into and out of an idle state, the low-latency requirements may not be met. Thus, it is a challenging task to both satisfy the low-latency and high-throughput requirements and achieve power savings at the same time.
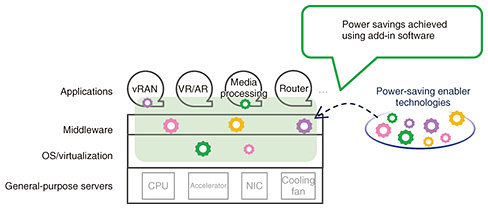
3. Power-saving enabler that uses software technology to reduce power consumptionNTT Network Innovation Center is undertaking research and development of a power-saving enabler, POSENA (POwer Saving ENAbler), with the aim of using software technology to achieve power savings in applications that have stringent low-latency and high-throughput requirements. Figure 2 shows an overview of POSENA. The concept of POSENA is to use software to control processing of the given load in such a way that the minimum necessary computing resources are used. Great power savings can be achieved, particularly when the load is low.
POSENA uses multiple technologies. Power saving is enabled by adding POSENA to applications, middleware, OSes, or virtualization software, as an add-in*. Particularly promising use cases are NFV applications that require stringent low-latency and high-throughput requirements, such as vRANs, virtual reality (VR), augmented reality (AR), media processing, routers, and other functional parts of a network. This article introduces two technologies used by POSENA: Power-saving low-latency data transfer technology [2] and CPU idle-aware optimal tuning and control technology [3], with examples of their use in a vRAN, a promising use case.
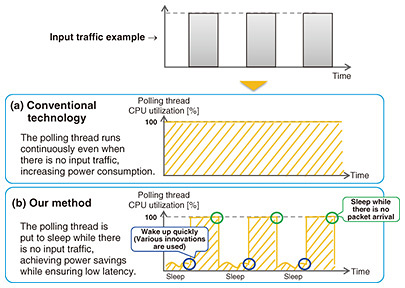
4. Power-saving low-latency data transfer technology4.1 Conventional high-speed, low-latency packet transmission and reception methodsLinux, a widely used OS, has a packet transmission/reception function in its kernel so that application developers can easily develop programs that send and receive packets. The packet transmission/reception function is designed for general-purpose use. For example, it diverts CPU resources to packet reception only when a packet arrives so that it can function even when the computer has only a single CPU core. Specifically, when a packet arrives at the network interface card (NIC), the Linux kernel is notified by a hardware interrupt. Triggered by this interrupt, the Linux kernel stops processing the current task and begins handling the packet reception. This packet reception method is called the interrupt method and is highly efficient because it diverts CPU resources only when a packet arrives. It is also highly versatile because it can operate even when the computer has only a single CPU core. The downside is that, when an interrupt occurs, this method introduces an overhead due to context switching, such as interrupting the current processing task and saving the data being computed. In addition, when packet reception processing is handled in the Linux kernel, a large delay may occur due to the need to copy packet data from memory in the kernel space to memory in the user space, making it difficult to achieve high throughput. To avoid this problem, there is a mechanism for bypassing the kernel in cases where low latency and high throughput are required, such as NFV applications. This mechanism executes packet transmission/reception in the user space rather than using networking functions provided by the Linux kernel. One example is the Data Plane Development Kit (DPDK), which is provided as open source. DPDK instantiates a thread, called a polling thread, resident in the user space that monitors packet arrival at the NIC. Since the CPU is thus constantly monitoring packet arrivals, it can achieve high responsiveness when receiving packets. For this reason, DPDK is often used in vRAN systems, which need to meet microsecond-order latency requirements and provide high throughput in excess of 20 Gbit/s. Although this polling scheme is excellent in terms of low latency and high throughput, it is problematic because the polling thread is constantly using CPU resources to monitor packet arrivals. Even when no packets are arriving, the CPU utilization is always 100%, resulting in high power consumption. Figure 3(a) illustrates this problem. 4.2 Packet transmission/reception method that satisfies both high-speed/low-latency and low-power-consumption requirementsA method of achieving low latency and high throughput and yet saving power involves revising the above-mentioned polling thread in such a way that the thread sleeps during periods when no packet is arriving, as shown in Fig. 3(b). This can avoid the constant 100% CPU-core usage described above, thus reducing power consumption. A potential problem with this is that the arrival of a new packet may go unnoticed during the sleep period. To prevent this from happening, hardware interrupts are used so that packet arrivals can be noticed immediately even when the thread is asleep. However, hardware interrupts cause the interrupted thread to suspend processing and incur the overhead of context switch, making it difficult to achieve low latency and high throughput. We solved this problem by taking note of the fact that, as long as the interrupted thread is not doing any processing at the time of interruption, there is no major problem. We created a polling thread that is dedicated to monitoring packet-arrival and packet-reception processing and does no other processing. This thread sleeps when no packets are arriving. When a packet arrives and a hardware interrupt occurs, the thread does not execute any processing. Hardware interrupts are very high-priority processes. If the hardware interrupt handler is required to execute a large amount of processing, it will consume CPU time, leaving too little allocated for stable system operation, leading in turn to system instability. To avoid this problem, the only processing required of the hardware interrupt handler issued by the NIC when a packet arrives is the action of waking up the polling thread. The packet reception processing is executed in the context of the polling thread rather than by the hardware interrupt handler. Therefore, even if a packet arrives during sleep, the thread can be woken instantly and the packet reception process can be executed.
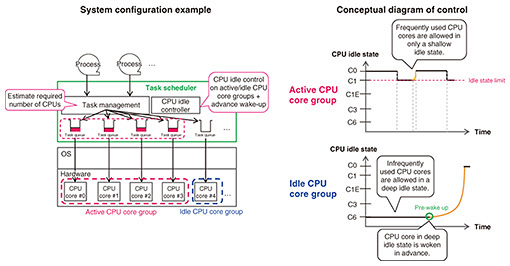
To evaluate the effectiveness of this method, we conducted experiments using a simple software switch that sends and receives packets and confirmed that this method saves about 4.5 W per polling thread. We also confirmed that the increase in latency caused by putting the polling thread into a sleep state was as small as 4 to 7 microseconds. We also evaluated the practicality of this method by conducting a demonstration test using a commercial vRAN vDU product. We were able to confirm that this method reduced power consumption without adversely affecting wireless signal processing. The number of polling threads depends on the throughput required for any particular system. In most cases, a system will have multiple polling threads. As the number of polling threads increases, so does the power-saving effect. This sleep control method can be applied not only to network input/output (I/O) of packet transmission/reception processing but also to accelerator I/O and to inter-process communication. 5. CPU idle-aware optimal tuning and control technology5.1 Power-saving mechanism via hardware control provided by the CPUMost CPUs, which are widely used processors, have a hardware-controlled power-saving mechanism. For example, when there is no task to be processed, power is saved by stopping the CPU’s operating clock, lowering the operating voltage, and disabling the cache function. This mechanism is called CPU idle or low power idle (LPI). In the case of Intel CPUs, it is called a C-state. CPU idle is very useful for power saving but introduces latency when a CPU core in the idle state needs to return to the active state. If the CPU idle function is used without careful consideration, latency and throughput requirements may not be met. Therefore, when stringent latency requirements or high throughput are required, the CPU idle function is disabled. 5.2 CPU idle control that satisfies both low-latency/high-throughput and power-saving requirementsThis technology achieves power savings by color-coding CPU cores into the idle CPU core group that can make the transition to a “deep” CPU idle state and the active CPU core group that can only go into a “shallow” CPU idle state. Power savings are achieved by controlling which CPU core group a given task is assigned to. Figure 4 shows an overview of this technology. It is desirable to assign tasks with stringent latency requirements, tasks that require high throughput, and frequently executed tasks to the active CPU core group. It is preferable to assign tasks with less stringent latency and throughput requirements and sparsely executed tasks to the idle CPU core group. When a task is assigned to a CPU core that is in a deep CPU idle state, a lengthy recovery time is required before the CPU core returns to the active state, as mentioned above. A way of shortening this recovery time is to wake the core that is in a deep CPU idle state in advance of assigning a task to it. This enables us to benefit from the power-saving effect of transitioning a core to a deep CPU idle state without the added latency caused by the recovery time.
To evaluate the effectiveness of this technology, we implemented and evaluated a prototype of this technology using a general-purpose server with a CPU featuring a CPU idle function. The evaluation results varied depending on the number of CPU cores mounted on the server hardware and type of task to be processed, but we confirmed a reduction in power consumption of more than 100 W per server. To confirm the practicality of this technology, we conducted a demonstration experiment by applying it to a commercial vRAN vDU product. We confirmed that it reduces power consumption without adversely affecting radio signal processing. 6. Future outlookThe amount of communication traffic flowing through networks is increasing yearly. The network device load to handle this communication traffic is also increasing. Without technical innovation, the increase in communication traffic will continue to boost power consumption. Therefore, it is urgent that we take specific measures that will reduce power consumption but ensure high performance. We will continue to create many highly effective power-saving technologies and implement them in practical applications. References
|
||||||||||