|
|||
|
|
|||
       |
Rising Researchers Vol. 23, No. 1, pp. 7–14, Jan. 2025. https://doi.org/10.53829/ntr202501ri1  MediaGnosis Is a Multimodal Foundation Model That Can Think and Accumulate Knowledge Like a HumanAbstractArtificial intelligence (AI) technology continues to advance, and the spread of generative AI using large language models is making it more accessible. However, the AI services currently offered are mostly specialized in specific functions, such as facial recognition, voice recognition, translation/summarization, and text generation. We have not yet reached the point where we can create an AI service that integrates all of these functions. NTT Distinguished Researcher Ryo Masumura is working on MediaGnosis, a project that connects multiple AIs with expert knowledge to make integrated decision-making like the human brain. We spoke with him about the various challenges involved in creating integrated AI services resembling a human and the mindset required for this research. Keywords: artificial intelligence, MediaGnosis, multimodal foundation model
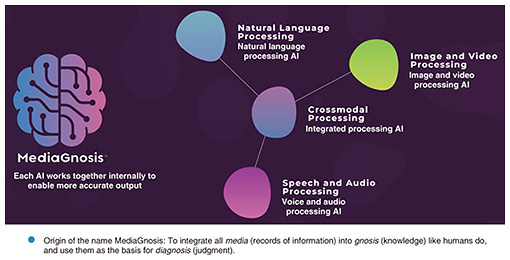
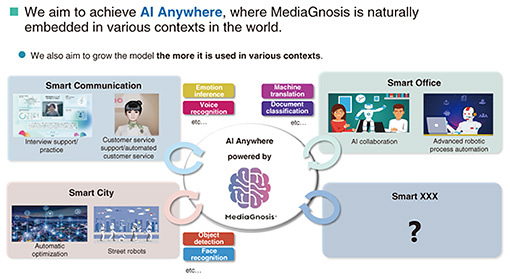
What the multimodal foundation model MediaGnosis aims to achieve—First of all, please tell us about your research topic, MediaGnosis. In recent years, the world has been experiencing an incredible boom in artificial intelligence (AI). A well-known example is an AI called ChatGPT, a large language model (LLM). Other features in the public spotlight include facial recognition, which is being introduced at airports, voice recognition that can understand what people are saying, and the ability to read people’s emotions. This AI is being designed to artificially reproduce various human perceptions and intelligence, but as things stand, we have not yet reached that stage, and development is focused on specific functions. For example, if we compare current AI with the human brain, humans can listen to audio and watch video, take it in as knowledge, understand it, and translate it into a different language. MediaGnosis is not a research project that aims to evolve individual, specialized AI functions, but rather to link together multiple AIs with expert knowledge to create AI that can make integrated judgments like the human brain (Fig. 1).
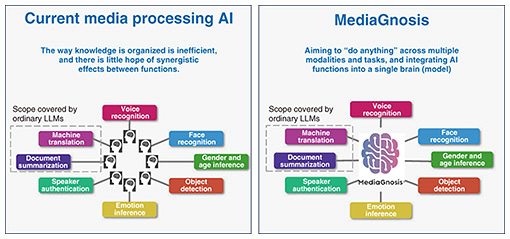
In AI, the brain that stores knowledge is called a “model,” but MediaGnosis does not develop a model, but rather is a “multimodal foundation model” that aims to “do anything.” The key to creating a multimodal foundation model is two “multis.” One is understanding multimodal data, which refers to storing various forms of knowledge in a single brain (model), like a human being, and understanding things in a more human-like, integrated way, rather than loosely combining brains that have been optimized for individual, separate functions. The other is multitasking. By utilizing this wealth of knowledge, we aim to simultaneously run multiple AI functions, such as voice recognition and reading emotions, to enable innovative, human-like judgments and tackle difficult tasks. MediaGnosis is the research and development of AI that is similar to the human brain, utilizing diverse knowledge across multiple modalities and tasks to simultaneously run multiple functions (Fig. 2).
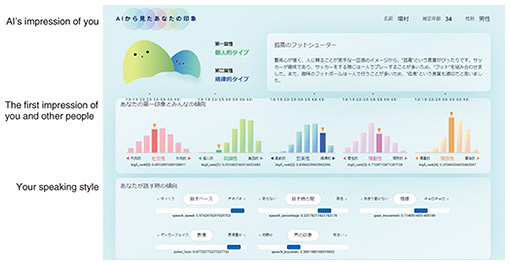
To put this research in simple terms, imagine the famous “cat robot that can do anything” or “100,000 horsepower humanoid robot” from the world of manga. Those robots are very smart and can communicate with people smoothly and help them. Our goal as AI researchers is to develop the technology to think and interact like the robots depicted in that world. Nowadays, voice recognition, facial recognition, and ChatGPT functions have improved dramatically. But can you just put these functions together and create the famous cat robot? To create the robots of people’s dreams, they need to be more than just the sum of their functions; they need to understand people and empathize with them. Because the accuracy of each function has increased, we are working every day on research and development into a system that tightly connects pieces of information like the human brain, which we have named MediaGnosis. —Please tell us about the unique strengths and features of MediaGnosis. AI is a hot research topic and there are many people specializing in it, but the majority of them continue to specialize in research into media AI, which is just “one of the five human senses.” For example, research into LLM AIs used to focus on machine translation and summarization, but now they have evolved into highly accurate AIs such as ChatGPT. Our MediaGnosis is an extension of independently evolving AI functions like LLMs, but what makes it unique is that it does not specialize in one of the five senses, but makes integrated judgments with all five senses. Rather than a deep understanding of language that encompasses every nook and cranny of Wikipedia, our strength lies in our service’s balanced, integrated understanding of words, images, etc., which sets us apart from other companies. MediaGnosis aims to develop an advanced “human understanding” function that can understand human emotions and the impression it makes on others, which will have an impact on the satisfaction of those receiving the service. Communication can only take place when there are a giver and a receiver. When you have to apologize to someone, the impression and satisfaction of the receiver will change greatly depending on how you apologize. The MediaGnosis app we developed can perform an integrated analysis of the impression you give to others based on the video and audio of your apology. The factors that lead to a bad impression vary from person to person, but can include making excuses, or inappropriate speaking speed, tone, or facial expressions. The “brain” analyzes these based on the information stored in each AI and can provide feedback for each item (Fig. 3).
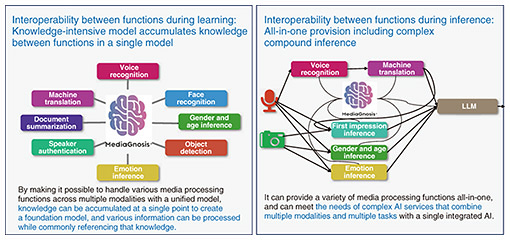
In this way, MediaGnosis can simultaneously run multiple functions and understand people on a deep level, making it possible to communicate without causing discomfort to others. This allows us to respond in a more sophisticated way, not just providing what is generally preferred, but also providing advanced services such as matching the offering to the personality type, greatly expanding the range of services. Furthermore, even if we were to create the “super smart brain” we are aiming for, monthly maintenance costs of 100 million yen would make it unrealistic to implement the service. To avoid this, we are also focusing on making the software lighter so that it can run on the central processing units used in laptops, and are conducting our own research. One of the strengths of MediaGnosis is that it can be used in the simplest and most cost-effective way possible. As its name suggests, Nippon Telegraph and Telephone Corporation (NTT) has been exploring the “infinite possibilities of communication” since its founding with telegrams and telephones. Currently, there are few researchers in the integration field like MediaGnosis, but as an NTT research team, we want to take the lead in developing services that deepen communication between people using cutting-edge AI technology. —Please tell us about your research in the development of MediaGnosis. MediaGnosis’ research and development is a project theme that I initiated, and I am conducting research together with project members within NTT laboratories and affiliated companies. When we started this team, we thought that the key was to create a team that would appropriately link each group’s expertise. For that reason, we put together groups that specialize in different domains, such as voice recognition and language understanding, and we emphasize the importance of integrating them across the board. If each group evolves independently and we simply link them, we cannot expect the project as a whole to evolve. We are consistently aiming to develop a unified model of the brain, and we share a common understanding of the ultimate goal. Therefore, rather than focusing on the development of individual functions that use voice recognition to understand 100% of what the other person is saying, we are creating a model that shares data with other functions in an integrated environment and integrates and updates the system as a whole. In fact, running multiple functions simultaneously will result in higher accuracy than running only one highly accurate function. It is desirable to run them simultaneously with limited resources (capacity) and make efficient and accurate decisions, and it is also important to consider the balance of how much to distribute (Fig. 4).
In the world of AI development, the product of combining two data models is called a merged model, while an AI model that serves as the foundation for an application trained on large amounts of diverse data is called a foundation model. MediaGnosis is a multimodal foundation model, where the modal part of multimodal refers to understanding the five human senses, such as reading books and texts, learning from language, and handling video. In order to create a brain similar to that of a human, it is necessary to have the ability to multitask, which means being able to understand the components of language and the attributes of sounds, and to process multiple modalities simultaneously. We are developing a multimodal foundation model that, even when, for example, responding to two sentences with the same basic meaning, can understand their different connotations, such as an angry man saying, “Hurry up and give me the text!”, and a woman saying, in a gentle way, “I would like you to give me the text,” and then determine the appropriate response. —Please tell us about MediaGnosis’ outlook and vision for its goals. Research and development of MediaGnosis was launched when I became a distinguished researcher, and began in 2019. Since then, we’ve gradually integrated more and more functions and developed it into the current version, which is now capable of understanding people (for things like gender and age, where the answers are clear). However, further research is needed for the capability of understanding the external environment and community we are aiming for. To give the example of the need to understand the external environment in a call center, I have heard that operators are required to listen not only to what the other person is saying but also to the background sounds in order to understand the customer’s situation. By understanding the environment and responding appropriately, such as hearing a station announcement in the background, hearing multiple voices, or hearing the sound from a television, smooth communication is possible. MediaGnosis also aims to be able to judge the environment and determine the facial expressions, gestures, choice of words, and speaking style that will make a positive impression on the recipient. In order to improve the model’s ability to handle a wider variety of information and understand it in greater depth, we hope that it will be able to take in multiple pieces of information simultaneously and make judgments like a human would, enabling it to be used in a vast range of fields (Fig. 5).
However, in order for public to understand this system, the public needs to become a little more mature in terms of AI. We often hear in the news that “AI will take our jobs,” but that is not what we, as AI technology developers, are aiming for. The goal is to develop AI that will support people without doing things that people dislike. We are striving for MediaGnosis to be able to understand the emotions and impressions of others and communicate appropriately like a human, but we believe that while it may come close to being a human, it will not be able to completely replace a human. Does AI have to be like humans anyway? If you think of AI as one of the partner functions that accumulate human data, rather than as a human being, you will feel less resistance to it, and you should be able to adapt it to and use it in various contexts. On top of that, in terms of services, what people want is communication, and I feel that AI that can understand those emotions is what the public wants more. Currently, as a business, we are extracting video and text functions as services and setting prices, but unless the public learns about them, the scope of their use will not expand. To achieve this, our immediate goal is to get many of NTT’s operating companies to use MediaGnosis and increase its accuracy and raise its profile. The model has already been introduced and pilot projects are underway at NTT Communications, NTT DOCOMO, NTT EAST, and NTT WEST. We hope to eventually make it an ecosystem for the entire NTT community, with MediaGnosis always at the center. It is used in many contexts, and the data obtained from these is received from various companies, analyzed, and fed back into MediaGnosis’ research and development to further grow the model and provide better services. A closely related concept is Digital Twin Computing, one of the three pillars of NTT’s Innovative Optical and Wireless Network (IOWN) initiative. It is a virtual substitute for real-world objects and people, created by building twins of them in the digital world. The core of my research is development that contributes to replacing humans in Digital Twin Computing. In order to maximize MediaGnosis’ strength as an AI platform, it is necessary to implement the IOWN initiative, which is based on a high-speed, low-power network. With the IOWN initiative’s innovative network infrastructure established, MediaGnosis aims to create human-like AI that can understand human emotions and communication, and will advance its understanding of environmental information around humans, as well as its understanding of roles and tasks within organizations and groups. We hope that this AI will be used not only in collaborative work in the office, but also in a wide range of human activities such as nursing care and daily life assistance, and that it will be able to empathize with a variety of people. Efforts to innovate—What are your research challenges and problems that need to be solved in the future? My main role is to link together the expertise from different groups; more specifically, I am researching ways to combine multiple functions into a single model (brain), and a way for the improved level of one function to translate to improved level of other functions. In order to connect multiple functions, the brain needs to refer to and utilize other separate functions, but integrating these functions in the brain is a very difficult challenge. For example, if you modify the logic for inferring emotions from voice and then use the data to learn from it, it may happen that the accuracy of the translation decreases without us really understanding it. We don’t want to disrupt the overall balance by upgrading just one function like this. Additionally, you need to consider the frequency of updates. Currently, multiple pieces of data that are pooled for individual functions are pooled in a central location and learned all at once, so updates to the learning functions and information are carried out every six months or so. When it comes to understanding people, updating the most recent data is not that important, so there is no issue with pooling the data centrally; however, it’s a different story when you want it to empathize with specific people. For example, when it comes to AI being incorporated into robots that become part of our daily lives, such as nursing robots, ideally the AI will be able to remember yesterday’s communication and then respond accordingly. Currently, it is very difficult for AI to quickly absorb yesterday’s news, store it as knowledge, and output it. However, if we could create a brain mechanism that could store data in small amounts and build knowledge, it would be possible to shorten the six-month learning span and learn every day. We are moving forward toward our lofty goals, but the current situation is that whenever something is learned, performance degradation occurs somewhere. We believe that once we overcome this, the future will come into view. Cross-linking connects the three “engines” in the image in Fig. 6. What is important is to understand different events and information from multiple perspectives and link them when they have the same object of recognition, and we are also working on how to link them in finer detail.
We also frequently receive questions about the user interface. If we were to limit it to a browser, we would only be able to provide services in front of a personal computer. At present, MediaGnosis is often used on a browser due to the usage environment and ease of implementation, but we are also developing an application programming interface so that it can be used with a wide range of devices, including robots, touch displays, and surveillance (closed-circuit television) cameras. Of course, we need to keep an eye on which interface will become mainstream, but we are mindful to ensure that accuracy does not change depending on the interface. In addition, apparently what counts as inappropriate movements and behavior change depending on the person’s race. AI should not be something that makes people feel uncomfortable, so this kind of individualized response is also a challenge that must be overcome. AI is not something that is released as a complete version. People make it grow. When people try it out, we receive feedback about any problems that arise, and then we make improvements to increase accuracy. No matter what kind of service you offer, it will not be accepted at first. Online shopping has become commonplace today, but initially many people were resistant to it. As the number of users gradually increased, this resistance diminished and the service became more widespread. As the public gradually comes to understand the characteristics of AI and begins to use it, we will continue to conduct research and development so that MediaGnosis can provide more accurate services.
—Finally, do you have a message for researchers, students, and business partners? There is a term called an innovation mindset. Research and development requires deep consideration of fundamental issues and topics before creating something. Some researchers may be so focused on the goal of getting their research accepted at the next international conference that they fail to address the fundamental issues. As a researcher, I want to produce innovation, which I believe means solving fundamental problems through creative inventions and making the future world a happier place. In order to meet these expectations, I hope that students and young researchers will adopt an innovation mindset. Also, when setting a big vision for the future, they must work backwards to come up with an approach to reach that future. Among researchers, there are genius types and hard-working types. I think genius types should just do what they like. However, it is important for hard-working people to think backwards and set specific goals to reach this future and work toward them. As a researcher, I think it’s a good idea to set goals with an innovation mindset and then consciously think backwards to reach those goals. In order for MediaGnosis to become a better service for our business partners, the first priority is for them to use it. Our technology can be used in a wide range of domains, and we are conducting research to make this an advantage. In order for MediaGnosis to become a useful and versatile service, it is important that we maintain a cycle of receiving feedback from users and making improvements. We plan to continue repeating the verification cycle with many business partners to improve accuracy and meet the expectations of our users. For this reason, we would like our business partners to continue using it in a wide range of domains, and we would like to build a relationship that creates a synergistic effect, where we can grow together with MediaGnosis in terms of expectations and future vision. ■Interviewee profileRyo Masumura completed master’s program at Tohoku University Graduate School of Engineering in 2011. In the same year, he joined NTT. He received a Ph.D. in engineering from Tohoku University Graduate School of Engineering in 2016. He is engaged in the research and development of technology theories that allow for the efficient accumulation and utilization of knowledge like humans, by aggregating knowledge across various media processing such as voice recognition, natural language processing, and video processing. He has received numerous awards, including the Kiyoshi Awaya Academic Encouragement Award from the Acoustical Society of Japan, the Yamashita SIG Research Award from the Information Processing Society of Japan, the Information and Systems Society Best Paper Award from the Institute of Electronics, Information and Communication Engineers, and the Association for Natural Language Processing Annual Conference Excellence Award. |
||