|
|||||||||||||
|
|
|||||||||||||
       |
Feature Articles: Exploring Humans and Information through the Harmony of Knowledge and Envisioning the Future Vol. 23, No. 10, pp. 73–77, Oct. 2025. https://doi.org/10.53829/ntr202510fa10 Discovery of Hidden Knowledge in Data Relationships—Prospects for Reliable Healthcare through Infinite-hypothesis AI Models That Interpret Biological PhenomenaAbstractVarious analyses of biological information data have led to the discovery of numerous insights that contribute to the advancement of medical healthcare. However, the use of artificial intelligence in fields closely related to human life and health has drawn attention to the important issue of evaluating risks and uncertainties, particularly in analysis, prediction, and decision-making. This article explains a machine learning method that explicitly captures the risks and uncertainties in data analysis by considering the infinite number of hypotheses that may exist when a model explains biological phenomena. Keywords: medical healthcare, Bayesian machine learning, artificial intelligence
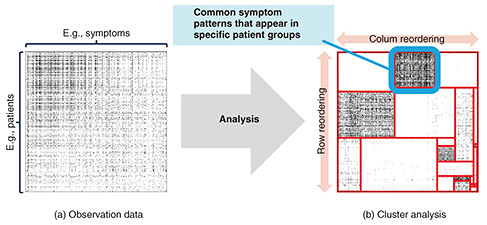
1. IntroductionArtificial intelligence (AI) has become an indispensable part of our lives and is being used in various fields, such as the production of various media including voice, music, images, videos, text, and games, as well as the backend of video streaming services and product recommendation systems. The advancements in large language models and generative AI have been remarkable. The world once depicted in science fiction during the early days of AI—such as a world where humans and AI coexist—is already becoming a reality. In fact, AI is not only demonstrating capabilities on par with humans in addressing many challenges in nature and society but is also, in some cases, surpassing human capabilities. The further development of AI will likely lead to a richer and more convenient life for humanity. What specific directions might the further development of AI take? and what kind of changes will this development bring to our lives in the future? Our research team is focusing on the ability to infer unknown knowledge as one of the important directions for the further development of AI. The term “unknown knowledge” may seem paradoxical at first glance, but it is no exaggeration to say that we, humans, have developed, cultivated, and demonstrated this ability, which has enabled us to evolve into the modern society we live in today. We derive hypotheses from phenomena that occur in the real world and imagine various “unknown” phenomena, treating them as if they were part of our existing knowledge. On the basis of the knowledge and experience accumulated over a long period, we can infer the certainty or uncertainty of unknown knowledge. For example, in the past, infectious diseases and unknown pathogens would cause severe damage to specific regions for long periods once they spread. However, in modern times, even for new infectious diseases and unknown illnesses, useful countermeasures and treatments can be discovered in an overwhelmingly short period (albeit with some degree of risk). Through the accumulation of various experiences over a long history, humanity has developed the ability to make such statistical inferences. However, as history shows, the accumulation of such experience requires an enormous amount of time. Therefore, our research team aims to implement this ability to infer unknown knowledge into AI, thus achieving human-surpassing imagination and high-precision statistical inference, which may bring about significant transformations in our lives. For example, it may be possible to prevent global epidemics and pandemics by predicting the risk of unknown new infectious diseases, or AI may be able to predict and prepare countermeasures against unknown pathogens that may be brought to Earth by extraterrestrial life forms, averting the threat of human extinction. This article focuses on structural hypotheses among the representation forms of unknown knowledge. Structural hypotheses refer to discrete structures that enable the effective and efficient representation of knowledge, such as permutations, partitions, binary trees, Cambrian trees, binary sequences, factor graphs, and rectangle partitions. These are particularly useful as methods for representing unknown knowledge that frequently arises in various bioinformatics challenges with applications in biomedical healthcare. For example, permutations play an important role in ranking and matching tasks and used in the ranking functions of search systems for large-scale data. Partitions are useful in classification and clustering tasks, helping to discover hidden cluster structures within large-scale data. In hierarchical clustering problems, binary trees are used to discover hierarchical cluster structures hidden within data. In phylogenetic-tree-analysis problems, Cambrian trees are used to capture the evolutionary trajectories of biological events such as gene mutations, fusions, and recombinations. Therefore, structural hypotheses are gaining attention as useful tools for revealing unknown knowledge hidden within data. The following sections present AI that uses structural hypotheses as a method for representing unknown knowledge, along with several application examples, methods for generalizing them, and prospects for applications in biomedical healthcare. 2. Relational data analysisMedically unexplained symptoms refer to cases in which patients are aware of some form of physical discomfort but the underlying medical cause cannot be identified, making it impossible to provide appropriate treatment. In Japan, such cases have become particularly prominent since the 1960s. One promising method for interpreting medically unexplained symptoms in a data-driven manner is relational data analysis. For simplicity, we will represent the observational data related to medically unexplained symptoms as a binary matrix, as shown in Fig. 1. This matrix corresponds to patient groups in the rows (vertical direction) and symptom groups in the columns (horizontal direction), with each element indicating whether a patient in the row has the symptom in the column, represented as a binary value (white or black in the figure). As shown in Fig. 1(a), the observational data representing medically unexplained symptoms may appear disordered at first glance. However, as shown in Fig. 1(b), by appropriately rearranging the order of patient groups and symptom groups and adding red rectangular auxiliary lines, a certain cluster structure can be revealed. The red rectangular auxiliary lines guide elements to cluster together within each block, where they are as similar as possible. Therefore, each block can be interpreted as indicating common similarities between specific patient groups and specific symptom groups. This may also be interpreted as suggesting the presence of new diseases emerging within the medically unexplained symptoms in a broader sense. In practical applications, as a highly simplified example, treatments or interventions found to be effective for a patient in a particular block may provide clues for effective treatments for other patients belonging to the same block.
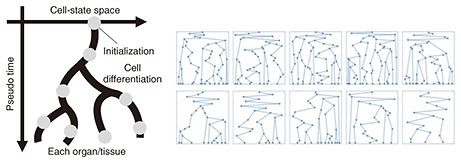
In the context of relational data analysis, unknown knowledge can be interpreted as rectangular partitioning for interpreting observational data. Therefore, research has been conducted on the construction of AI models for inferring rectangular partitioning hypotheses from relational data. By leveraging AI to infer the certainty or uncertainty of various rectangular partitioning hypotheses, we expect to gain clues for resolving medically unexplained symptoms. What are the most important requirements for constructing such an AI model? One important requirement is that the AI must be able to imagine all possible rectangular partitioning hypotheses without omission. In medical and healthcare applications such as interpreting medically unexplained symptoms, if there are hypotheses that the AI cannot even imagine and the truth lies within those hypotheses, the AI’s reasoning may overlook the truth, which could ultimately have a serious impact on our lives and health. Driven by this motivation, research has been conducted to develop AI capable of imagining all possible rectangular partitioning hypotheses without omission and inferring their certainty or uncertainty. In 2007, an AI model capable of imagining all rectangular partitions belonging to the regular-partitioning class was developed, and in 2009, an AI model capable of imagining all rectangular partitions belonging to the hierarchical-partitioning class was developed. However, these regular and hierarchical partitions are limited to only a small subset of all rectangular partitions, and an AI model capable of imagining all rectangular partitions has not yet been achieved. Our research team’s contribution lies in successfully constructing an AI model capable of imagining all rectangular partitions using two methods between 2020 and 2021 [1, 2]. This was achieved by introducing a mechanism that indirectly imagines rectangular partitions, which appear to be difficult for AI to imagine directly, using permutations (i.e., sequences of numbers), which are easy for AI to handle, on the basis of the fact that the set of all rectangular partitions can be one-to-one mapped to a specific class of permutations, using knowledge from combinatorics. Through several real-world benchmark datasets, we have confirmed that the ability to imagine any rectangular partition, not limited to restricted classes as in the past, contributes to the high functionality and reliability of AI models. With this achievement, we can now guarantee that AI has the ability to imagine any rectangular partition without omission. Going forward, we aim to further enhance this inference capability to achieve higher precision, thus derive important insights from relational data analysis that could lead to solutions for various medically unexplained symptoms in the real world. 3. Phylogenetic analysisLike cell differentiation and genetic mutations, the technique of inferring a phylogenetic tree from objects that exhibit systematic evolution and developmental structures over time is called phylogenetic analysis, and it has played an important role in various applications. For example, phylogenetic analysis of the differentiation structure of induced pluripotent stem cells (iPSCs) has attracted significant attention as one of the most promising applications. Such cells possess a certain degree of differentiation potential and expected to have the potential to be induced to differentiate into various tissues and organs. Therefore, if we can understand the principles of their differentiation and induce them appropriately, it may be possible to create transplantable organs and tissues by converting somatic cells obtained from patients into iPSCs and culturing them. By creating cells from diseased tissues that were previously difficult to obtain, it may be possible to contribute to understanding the mechanisms of disease onset and identifying effective treatments and drugs. From another perspective, phylogenetic analysis has also been used as a useful tool for inferring the origin of infectious diseases and identifying clues to prevent their spread during recent global pandemics. Genes associated with infectious diseases generally undergo systematic changes through events such as mutation, fusion, and recombination during their expansion. Therefore, tracing the phylogenetic tree of their development may provide clues to their origin and transmission routes. In the context of phylogenetic analysis, unknown knowledge can be represented as a Cambrian tree, as shown in Fig. 2. This represents the systematic variation of genes as a phylogenetic tree using events in which a parent gene branches into two child genes and events in which recombination occurs from two parent genes to one child gene. Such phylogenetic trees can generally involve a vast number of hypotheses, so there has been interest in developing technologies that can infer phylogenetic trees using AI. What are the most important requirements for such AI? Similar to the rectangular partitioning hypothesis for medically unexplained symptoms, we believe that the ability to imagine all possible Cambrian-tree structures hidden in the data is important. How can we develop an AI that can imagine all Cambrian-tree hypotheses without omission and infer their certainty and uncertainty? Interestingly, similar to the relationship between rectangular partitioning and permutations in the aforementioned relational data analysis, it is known in combinatorics that the set of all Cambrian trees is in one-to-one correspondence with a special set of permutations. By leveraging this fact, we have successfully constructed an AI model capable of indirectly imagining all Cambrian trees through permutations [3, 4]. We aim to use this AI model to infer the differentiation structure of iPSCs and elucidate its mechanisms, thus uncovering important insights that could contribute to the future development of regenerative medicine.
4. Future directionsWe have introduced methods for enabling AI to imagine rectangular partitioning and Cambrian trees as unknown knowledge in two application examples of relational data analysis and phylogenetic analysis. What if we want AI to imagine other structural hypotheses for different problems? Do we need to rebuild such mechanisms from scratch? We are pursuing an approach that is the opposite of this ad hoc implementation of AI models. Instead, we aim to develop a mechanism that enables AI to autonomously discover and imagine appropriate structural hypotheses for the target problem. We call this concept the “super Bayesian method,” which we have been promoting since 2022 [5] (Fig. 3). This method can be understood as importing insights from algebraic combinatorics and extremal combinatorics into Bayesian statistics. In algebraic combinatorics, various structural hypotheses, such as permutations, partitions, binary trees, Cambrian trees, binary sequences, factor graphs, and rectangle partitions, can be uniformly represented by surjections or injections from permutations. In extremal combinatorics, it is known that redundant sequences called “superpermutations” contain all permutations as their subsequences. Figure 3 illustrates an example of a superpermutation containing permutations of length 5. Supermutations that contain all permutations is the concept behind the super Bayesian method, and we aim to extend it to a framework in which AI models can infer the representation form itself from the target data in a data-driven manner without users having to specify the structural hypothesis in advance. In 2025, we have established the theoretical foundation for this and are now beginning to work on its full-scale implementation. We will continue to advance our research without sparing any effort, striving to contribute to the development of high-reliability medical healthcare through AI capable of inferring unknown knowledge.
References
|
||||||||||||