|
|||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||
       |
Feature Articles: AI Constellation—Toward a World in Which People and AI Work Together Vol. 23, No. 11, pp. 40–46, Nov. 2025. https://doi.org/10.53829/ntr202511fa4 Advanced Research on AI Algorithms for Supporting AI ConstellationAbstractThe following four examples of NTT’s research on cutting-edge artificial intelligence (AI) algorithms to be used as basic techniques for AI Constellation—a large-scale AI collaboration technology—are introduced in this article: (i) “learning transfer,” which enables the reuse of learning results; (ii) “transfer learning” that can adapt to environmental changes in imbalanced data with low labeling costs; (iii) “test-time-adaptation” for numerical-prediction models; and (iv) “sparse modeling” for analyzing a wide variety of large-scale, high-dimensional data. Keywords: artificial intelligence, advanced AI algorithm, non-media data
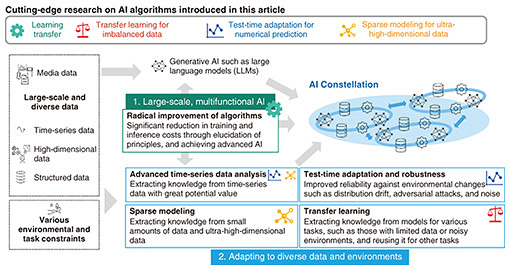
1. Research projects for AI ConstellationAI Constellation, which is a large-scale artificial intelligence (AI) collaboration technology promoted by NTT, finds solutions to a wide variety of complex real-world problems by preparing and linking numerous AI models tailored to various applications. Solving such complex problems must satisfy two requirements: (1) since model size is expected to increase and models become larger and more multifunctional, development and operational costs, including training costs, must be significantly reduced; (2) to address a wide range of real-world problems, versatility is required to adapt to a variety of tasks and environments and handle not only media data (such as language and images) but also high-dimensional, non-media data (such as time-series data). Cutting-edge research on AI algorithms aimed at addressing these research challenges is introduced in this article (Fig. 1).
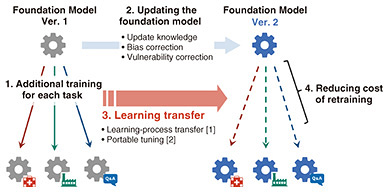
2. NTT’s learning transfer enables the reuse of learning resultsRecent generative AI systems mainly consist of a general-purpose model, called a foundation model, and a fine-tuned model obtained by additional training of the foundation model according to the purpose. The foundation model acquires a wide range of knowledge by pre-training a large number of its parameters on vast amounts of data from the Internet, so it can execute common tasks with high accuracy. Foundation models, however, may not be able to handle tasks that cannot be solved with common knowledge because the training data generally do not include data for handling such rare tasks. Since foundation models generate their outputs that are just statistically plausible, the model does not always produce the output that the user expects. Training foundation models with additional data for each purpose makes it possible to create and use fine-tuned models that have learned task-solving methods and user preferences. It has thus become possible to use the broad knowledge contained in the original foundation model to handle individual tasks and meet user requests in a manner that leads to expanded use of generative AI. The relationship between a foundation model and its fine-tuned models in a generative AI system can be seen as analogous to the relationship between the operating system (OS) of a computer system and the applications running on it. When operating a computer system, it is necessary to update the OS regularly and ensure that applications are updated accordingly. In a similar manner, when operating a generative AI system, it is necessary to update the foundation model, which is equivalent to an OS, regularly to update knowledge and fix vulnerabilities. However, within the scope of conventional techniques, to keep the tuned model up to date with updates to the foundation model, the only option has been to execute additional retraining on the updated foundation model to recreate its fine-tuned model. Such additional retraining requires more computational resources than those used during inference, so it is challenging that an increase in computational costs is unavoidable. To address the issue of such computational costs associated with updating foundation models, NTT proposed a new approach called “learning transfer”*1 in 2024 (Fig. 2) [1]. Learning transfer is based on the idea to make the results of additional training on one foundation model reusable for other foundation models at low cost. This is the world’s first research result that suggests that the process of learning transfer is possible. In other words, it demonstrates that the learning process for certain initial parameters of a deep-learning model can be converted into a learning process for different initial parameters.
There are two issues, however, with the above result for learning transfer. First, the model architecture cannot be changed because the learning-process conversion is executed within the parameter space. Second, additional training is still required because performance is lost when the conversion is executed during the learning process. Considering these issues, we reconsidered the conventional learning method and developed a learning method called “portable tuning,” which is designed to transfer the learning result to various foundation models [2]. With the conventional learning method, learning specialized for a given task or domain is executed by directly optimizing the parameters of the foundation model. In contrast, portable tuning introduces a reward model that corrects the output of the foundation model for each task and trains it as a model that is independent of the foundation model. This independence enables the reward model to be reused during inference with a new foundation model in a manner that achieves accuracy on a par with that of actual specialized training without the need for retraining. It is theoretically guaranteed that as the difference between the probability distributions of the foundation models becomes smaller, learning transfer with the reward model—without additional training—becomes more accurate. By not only reducing the re-training costs associated with updating the foundation model but also enabling prior verification of the expected effects of retraining, NTT’s learning transfer is expected to be used in a wide range of future applications.
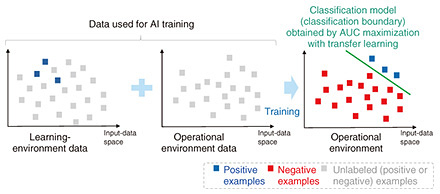
3. Transfer learning that can adapt to environmental changes in imbalanced data with low labeling costsCurrent AI technologies achieve high performance for a variety of tasks, but training AI models requires large amounts of labeled data. Collecting large amounts of labeled data, however, is often difficult. For example, in the fields of cybersecurity, medicine, and manufacturing, it is generally difficult to prepare large amounts of labeled data because labeling data requires a high level of expertise and effort. Even under these circumstances, transfer learning*2 is attracting attention as a technique for training high-performance AI models. Transfer learning enables high-performance AI models to learn by transferring useful knowledge from data on related tasks and adding it to limited data on the task to be solved. As an example of our ongoing efforts at NTT, transfer learning aimed at utilization in mission-critical tasks, such as cybersecurity, medical diagnosis, anomaly detection, and fraud detection, is introduced hereafter. A characteristic of data used in such tasks is that the amount of important data (positive examples), such as attacks, anomalies, diseases, and fraud, is extremely low compared to that of other data (negative examples). This type of data is called “imbalanced data,” and it is known that metrics such as accuracy, which are typically used in AI and machine learning, cannot accurately evaluate performance in the case of imbalanced data. Instead, a metric called “area under the ROC (receiver-operating characteristic) curve” (AUC) is commonly used. By explicitly maximizing AUC with labeled positive and negative training data, it is possible to build high-performance AI models even with imbalanced data. This training method—called “AUC maximization”—is a representative training method for imbalanced data. Regardless of the quality of the AI model constructed during training, it is inevitable that the data distribution (trend) will change during learning and operation, and that change will result in a problem called “distribution shift.” Specifically, the data distribution can be affected by the evolution of cyber-attack methods, emergence of new anomalies or fraudulent patterns, or changes in data-collection locations. It is assumed with methods for maximizing AUC that the data distribution is the same during learning and operation, that is, the performance of AI models trained using AUC maximization can deteriorate in situations where such distribution shift occurs. To solve this performance-deterioration problem, NTT has developed a transfer-learning algorithm for imbalanced data [3]. By targeting specific distribution shifts known as “positive-example shifts” and “covariate shifts,” we derived this algorithm to—theoretically—maximize AUC in the operational environment (the task to be solved) by using only positive examples and unlabeled data obtained in the learning environment (related tasks) and unlabeled data obtained in the operational environment (Fig. 3). The key point about this algorithm is that by assuming the above specific types of distribution shifts, it has been theoretically shown that the AUC, which is originally defined from positive and negative examples of the operational environment, can be calculated using only positive examples and unlabeled data. This algorithm enables highly accurate learning, as if AUC maximization is achieved using complete training data (positive and negative examples) of the operational environment, even in situations in which only incomplete training data (positive examples and unlabeled data) is available. For future work, we will continue to develop this algorithm and create AI algorithms that can be used stably and safely even under various constraints that arise in the real world (distribution shifts and incomplete data, for example).
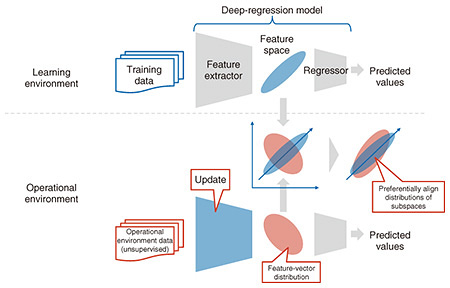
4. Test-time adaptation for numerical-prediction models (regression models)Regression models, which predict numerical values (continuous values) from input data, are important due to their wide range of applications such as predictive tasks for time-series data and image data (such as sensor data obtained in the manufacturing, medical, and financial sectors). With a typical regression model, it is assumed that the learning environment and operational environment are the same (the data distribution does not change). However, this assumption leads to the aforementioned distribution-shift problem, that is, the data distribution in the actual operational environment differs from the data distribution in the learning environment. For image data, the brightness and surrounding objects change according to the weather and time of day. For sensor data, the measurement environment can change and the measurement equipment can falter, so the data might differ unintentionally from the data used in the learning environment over time. If a regression model is applied when a distribution shift has occurred, accuracy of the model will decrease because data with different trends will be input. Ways to maintain the accuracy of the model in the operational environment include obtaining and annotating data from the operational environment during the training phase and using it for training. However, collecting data from the operational environment in advance can be expensive or impossible in principle, and annotation costs are incurred continuously during operation. To address the above issues, we are developing an algorithm called “test-time adaptation”*3, which autonomously adapts an AI model after training using only unlabeled data of the operational environment. Conventional research has focused on classification models, which assign given data to one of several predefined classes. That is, conventional algorithms require a structure specific to classification models that outputs predicted probabilities indicating the class to which the input data belongs (e.g., cat 80%, dog 10%, bird 5%). On the contrary, ordinary regression models used in practice do not use concepts such as classes or predicted probabilities and output real values, so conventional test-time adaptation algorithms cannot be used. At NTT, we therefore first analyzed the characteristics of regression models and found that such models differ from classification models in that the feature vectors in the intermediate layers of deep regression models are concentrated in a very small subspace of high-dimensional space. Considering this finding, NTT proposed an algorithm for aligning the feature distribution of an unknown operational environment with the feature distribution of a learning environment [4] (Fig. 4). Since the feature vectors are concentrated in a certain subspace, most dimensions in the feature space rarely contribute to the model output. Therefore, by prioritizing the alignment of the distribution in the subspace where feature vectors are concentrated, the adaptive performance of the regression model significantly improved.
Because our algorithm is independent of the output format of the model, incorporating it into data-analysis AI used in a variety of business fields, including manufacturing, healthcare, and finance, can prevent a decline in accuracy of the model due to environmental changes, and that outcome is expected to significantly reduce costs of MLOps (machine-learning operations). Our algorithm is thought to be applicable to not only regression models but also a variety of models, such as multimodal foundation models, in response to environmental changes (such as weather changes and sensor degradation) affecting image data and time-series data. It will thus contribute to expanding the scope of AI applications.
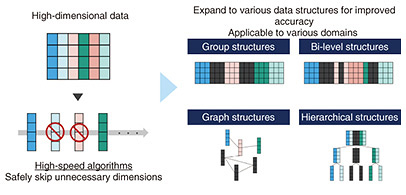
5. Fast sparse-modeling algorithm for analyzing diverse, large-scale, high-dimensional dataAdvances in sensing technology have made it possible to obtain a wide variety of data from people and objects, and analyzing those data has been attracting attention as a means to develop businesses and address social issues. An increasing amount of such data is known as “high-dimensional data,” which has a high number of dimensions (equivalent to “features” in this article) relative to the amount of data. However, modern AI data analysis often relies on massive amounts of data to achieve acceptable performance, thus, it is thought to be difficult to use high-dimensional data, the amount of which is relatively small. A technique that excels at analyzing such high-dimensional data is called “sparse modeling”*4. Sparse modeling is a data analysis technique with which sparsity is assumed, meaning that only a small portion of the obtained information is necessary, and the majority of the rest is unnecessary. Using this sparsity and assuming that only a small portion of the dimensions are necessary makes it possible to analyze high-dimensional data. Even with sparse modeling, as the dimensionality of the data increases, the processing time becomes longer, so it is difficult to analyze and use the data within a realistic time frame. To address this issue, NTT has developed an algorithm that significantly speeds up sparse modeling. By taking advantage of sparsity (only a small number of dimensions are required) and introducing this unique fast sparse-modeling algorithm that safely skips unnecessary computations, we have significantly reduced processing time without degrading accuracy [5] (Fig. 5).
This fast sparse-modeling algorithm has been partly incorporated into NTT products. For example, an algorithm called “FastSGL” accelerates feature-selection analysis by up to 35 times without any loss in accuracy [6]. This algorithm has been incorporated into Node-AI, NTT DOCOMO BUSINESS’s no-code analysis tool for time-series data in a manner that shortens decision-making lead times and speeds up the PDCA (plan-do-check-act) cycle for data analysis [7]. High-dimensional data also include data with various structures. Examples of such structures include group structures in regional traffic volume data, network structures in communication data from a telecommunications network, and hierarchical structures of product classifications in product data from e-commerce sites. For high-dimensional data (the amount of which, as previously mentioned, is relatively small), accuracy is expected to improve by using this structural information simultaneously. At NTT, we are also developing high-accuracy, high-speed, high-dimensional data-analysis technology by making it possible to apply our fast sparse-modeling algorithm to this structured high-dimensional data. We have succeeded in accelerating the analysis of high-dimensional data with a wide variety of structures, such as group structures [8], network structures [9], and hierarchical structures, thus have expanded the scope of application of NTT technology (Fig. 5).
6. Future developmentsExamples of research on cutting-edge AI algorithms—to contribute to future development of AI Constellation—were introduced. We will further develop these cutting-edge AI algorithms to achieve fundamental improvements in training and operation of AI models as well as advanced analysis of non-media data such as sensing data and time-series data. We believe that these developments will contribute to the actualization of AI Constellation to find solutions to complex real-world problems. References
|
||||||||||||||||||||||||||||