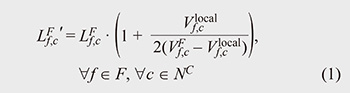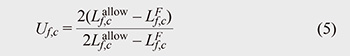|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
       |
Regular Articles Vol. 24, No. 4, pp. 53–63, Apr. 2026. https://doi.org/10.53829/ntr202604ra1 Resource Allocation with Heterogeneous Resources and Parallelism in Disaggregated ComputingAbstractDisaggregated computing improves resource utilization by pooling central processing units, memory, and accelerators and flexibly assigning heterogeneous resources to each service component. To maximize these benefits, resource allocation and routing must be decided efficiently before execution. This article introduces a practical-time resource allocation method that models heterogeneous resource characteristics and parallel processing effects. Simulations in heterogeneous disaggregated systems show that this method meets service-performance requirements while reducing required resources by 28–51% on average compared with conventional methods. Keywords: disaggregated computing, resource allocation, hardware acceleration
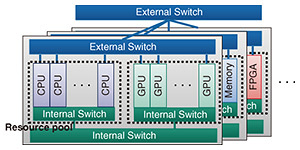
1. IntroductionThe pace of performance improvement in general-purpose central processing units (CPUs) has slowed in the post-Moore’s-law era, while the demand for computation has been increasing rapidly due to the spread of artificial intelligence (AI). To sustain performance growth with this gap, modern systems increasingly rely on specialized accelerators—most notably graphics processing units (GPUs) and field-programmable gate arrays (FPGAs)—that can execute particular workloads more efficiently than CPUs. At the same time, AI models continue to scale in size and complexity [1], and many practical deployments require multiple accelerators to satisfy throughput and latency targets. This creates a strong need for system architectures that can combine heterogeneous computational resources and use them efficiently. To support heterogeneous and accelerator-centric workloads, datacenter operators have been increasingly interested in disaggregated computing*1, where CPUs, memory, and accelerators are pooled and flexibly composed through high-performance interconnects [2–5]. NTT’s Innovative Optical Wireless Network (IOWN)*2 initiative introduces Data-Centric Infrastructure (DCI)*3 as a future direction for such architectures [2, 3]. In this article, we specifically focus on resource allocation in disaggregated computing systems, which serves as a key technical foundation that can contribute to the actualization of DCI. Figure 1 shows the disaggregated-computing system model considered in this article; heterogeneous resources are grouped into resource pools and interconnected via internal and external transmission paths [2–4]. Resource pools contain resources of the same type (e.g., CPUs, GPUs, FPGAs), and the resources in each pool are connected through these transmission paths. Resource pools that are physically close to each other are connected via internal transmission paths, whereas those that are physically far from each other are connected via external transmission paths. We call a cluster of resource pools connected via internal transmission paths a block. This hierarchical organization reflects realistic datacenter deployments and is important because link characteristics (bandwidth, latency, and contention) differ between internal and external paths, directly affecting end-to-end service performance.
In the real world, services are provided across multiple domains (e.g., database queries, compression, encryption, video coding, signal processing, and conventional machine learning) [6]. In this context, the service is composed of an ordered chain of processing requests, each of which we call a virtual function request (VFR)*4. In disaggregated computing, the flexible utilization of multiple types of computational resources, such as CPUs, GPUs, and FPGAs, enables the assignment of each VFR to the most appropriate computational resource. This approach ideally allows for effective service execution across heterogeneous computational resources. Note that we define a virtual function (VF)*5 as a virtualized dedicated functional unit within a computational resource, which can execute the VFR. A key architectural issue in executing such chains is data movement. Conventional designs often rely on the CPU to manage data transfer between resources, which can create a communication bottleneck because traffic concentrates on the CPU and its associated interconnect. In contrast, recent approaches enable computational resources to transfer data autonomously and directly by bypassing the CPU in the data-transfer path [6–9]. Therefore, in disaggregated computing, it is desirable to efficiently execute services that conduct a processing chain by enabling direct communication between computational resources [10, 11]. In the context of executing processing chains in disaggregated computing, enabling users to freely deploy services introduces significant challenges in resource allocation. For example, users may unintentionally select computational resources far exceeding service requirements or may select resources that are poorly located from a topology perspective. This can lead to inefficiencies and spatial imbalances, where some resources become over-utilized while others remain under-utilized. Such imbalances degrade service performance and increase cost, especially when expensive accelerators are involved. To address these issues, it is essential to carefully allocate resources and determine routing to minimize the number of computational resources while meeting service-performance requirements. Some methods [12, 13], many originating from cloud networking and virtual-network-function placement, account for inter-resource communication and optimize objectives, such as utilization [12] and power [13], under delay constraints. However, these methods are primarily designed for homogeneous resources (e.g., CPUs or servers). When applied to heterogeneous resources, such as GPUs, FPGAs, and other accelerators, they may allocate unsuitable resources because they do not explicitly model the performance characteristics of different resource types. This limitation can lead to suboptimal performance, for example, running AI inference on a general-purpose CPU instead of a specialized GPU. Thus, effective resource allocation in disaggregated computing must explicitly account for heterogeneous resource characteristics. Current resource allocation methods [12, 13] handle serial processing and do not support parallel processing across multiple resources. Given the increasing prevalence of high-load services, such as AI in disaggregated computing [9], it is crucial to consider parallel processing because these services cannot achieve sufficient performance with a single computational resource [14, 15]. To support parallel processing, it is imperative that services be pre-defined as parallelizable data flows; however, the appropriate degree of parallelism depends on the service requirements and on current resource and path usage. If the parallelism is chosen poorly, this approach may waste resources or degrade performance per resource. Therefore, a resource allocation method accounting for the impact of parallel processing is essential to effectively use resources in disaggregated computing. We thus previously proposed a resource allocation method for disaggregated computing that efficiently executes chained services among heterogeneous computational resources [16]. This method first integrates the characteristics of heterogeneous resources and parallel processing to maximize efficiency while deriving solutions within a practical time frame. Through simulations, we demonstrated that this method can allocate resources efficiently while satisfying service-performance requirements within a practical amount of time. In Section 2, we introduce the details of our resource allocation method. In Section 3, we describe the evaluation process and report the results in Section 4. We conclude in Section 5 with a summary.
2. Resource allocation methodOur resource allocation method is a polynomial-time heuristic approach that integrates the impact of the characteristics of heterogeneous computational resources and that of parallel processing. The first impact is modeled by scoring VF parameters that adapt depending on the computational resources used, while the second impact is modeled by determining the appropriate parallelism through a comparison of the throughput requirement of the service and allocatable processing velocity of VFs with the calculated delay requirement. 2.1 ModelThe disaggregated computing system is represented with an undirected graph G(N,E), where N ∋ n and E ∋ (n, n') denote sets of nodes and links, respectively. There are two types of nodes: computational resources and switches. The notation NC ∋ c denotes the set of computational resources and NP ∋ p denotes the set of switches (N = NC ∪ NP). A computational resource refers to an XPU (CPU, GPU, FPGA, and other accelerators) on which VFs are implemented, and a switch refers to two types of a device that connects resources within a network: internal (Peripheral Component Interconnect Express (PCIe)) and external (Ethernet) switches. The notation F ∋ ƒ denotes a set of VFs that execute VFRs with computational resources. Several parameters of a VF will vary depending on the computational resources on which it is implemented. The notation S ∋ s denotes a set of services composed of an ordered chain of VFRs. The performance requirements of the services are defined by throughput requirements 2.2 Heuristic approachResource allocation problems are generally NP (nondeterministic polynomial time)-hard, which indicates that finding an optimal solution within a reasonable timeframe is computationally challenging since it is transformed into the capacitated facility location problem, which is known to be NP-hard [17]. To address this issue, we developed a polynomial-time heuristic approach. Our heuristic approach is greedy in that it simultaneously determines the allocation and routing for each VFR. This heuristic approach explores potential solutions by executing provisional allocation and routing in advance and then determines the allocation and routing of the near-optimal solution by scoring to account for the impact of the characteristics of heterogeneous computational resources. By proactively exploring solutions that satisfy constraints, this approach significantly reduces the solution space, enabling the time-efficient allocation of VFRs. It also facilitates the appropriate determination of parallelism by comparing the throughput requirement of the service and the allocatable processing velocity of VFs with the delay requirement calculated during the provisional placement and connection phases. Algorithm 1 shows the processing of this heuristic approach. First, it sorts the VFRs of the service. A VFR having a large processing-velocity difference is placed at the top, and VFRs with smaller indices than this initial VFR are then sorted in descending order. Next, VFRs with larger indices than the initial VFR are sorted in ascending order, and a target VFR is selected from the top of the resulting list. Procedure 1 calculates the Score, Velocity, and Path for the target VFR while the remaining throughput requirement
When the above conditions are met and the target VFR is not the first VFR of the service, the shortest path (c, c') is determined using the Dijkstra method. When the previous VFR is divided, since there are several start/end points, the shortest path is calculated by all start/end points. If there is no shortest path in the allowable bandwidth, the target VFR cannot be allocated to the computational resource. If there is a shortest path, we determine the maximum allocatable processing velocity (Vmax) of the target VFR that guarantees the delay requirement of the service. The execution time of a service can be described as the sum of the maximum transmission delay of a path and the maximum processing delay of a VF. We use the M/D/1 queueing model*6 to capture the change in the processing delay with the utilization of the VF. Equation 1 shows the processing delay
Here, We derive Vmax from Equations 2 and 3, which facilitates the appropriate determination of parallelism.
Here,
Scores are calculated for the performance, future utilization, and capacity of the computational resource. Note that the performance and future utilization scores are the first to account for the characteristics of heterogeneous computational resources. The performance score is the maximum processing velocity of the VFs that can be implemented on the computational resource. The future utilization score is the utilization rate
This score enables the allocation to maximize the future utilization rate of the computational resource. Since the future utilization rate also reflects the transmission delay included in the allowable processing delay, this score also has the effect of suppressing this transmission delay. The capacity score is 1 when the computational resource is in use and 0 when it is not. This score also adds 1 when the VFs needed to execute the target VFR are in use and 0 when they are not. Note that the administrator can add other scores. When the target VFR is the first VFR of the service, Vmax and the scores are calculated in the same manner as above with When Vmax is Algorithm 1 selects the computational resource of the best score in Score. When the score is available, which means there is a computational resource where a VFR can be placed, the target VFR is allocated to the computational resource. If there is no VF available to execute the target VFR in the computational resource, the VF is also allocated to the computational resource. The path of the computational resource in Path is also connected, and the processing velocity of the computational resource and
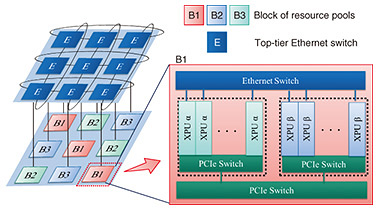
3. Experimental setupWe compared our method with the conventional method based on Holu [13] across various disaggregated computing systems. We first evaluated a heterogeneous system with random parameters to analyze the impact of heterogeneous computational resource characteristics and parallel processing. We then assessed the practicality of our method in a realistic heterogeneous system resembling real-world scenarios. Finally, we measured the resource allocation time to confirm whether the method produces solutions within a practical timeframe. 3.1 Simulation setupWe coded both our method and the conventional one in Python 3.10 and conducted simulations on an Intel-based personal computer with Intel Core i9-14900K 3.20 GHz (128-GB random access memory). 3.1.1 SystemWe assume the disaggregated computing system shown in Fig. 2: a 3 × 3 mesh topology with 144 computational resources, which is both commonly used and scalable [18]. The system consists of resource pools (8 resources each) connected via internal PCIe links and system-wide Ethernet, with top-tier switches for external network access. Six types of computational resources with distinct characteristics are symmetrically arranged. In the random system, we randomly set parameters of computational resources and VFs within the range shown in Table 1 (left). In the realistic system, based on experimental information [19] and typical real-world device information [20–25], we set the parameters shown in Table 1 (right). In the realistic system, we assume B1 consists of two GPU types [20, 21] B2 and B3, each consisting of two FPGA types [22–25], as shown in Fig. 2.
3.1.2 ServiceIn the random system, we assume that various services are randomly requested by combining two to six VFRs out of the ten types. Note that this simulation does not address resource reallocation after the initial allocation; we leave the exploration of dynamic reallocation that handles penalties or constraints during reallocation to future work. In the realistic system, based on video AI inference (AI inf.) [19], we assume that three types of services are randomly requested: 1. Decode α→Resize α→ AI inf. α, 2. Resize α→ AI inf. α, and 3. Decode α→Resize β→ AI inf. β. We set the requirements of each service at random within the range in Table 1. All services start and end at the top-tier Ethernet switch, simulating real-time data processing arriving at the datacenter via Ethernet. 3.2 Conventional methodWe compared our method against the conventional method adapted from Holu [13], which was chosen for its relevance in considering inter-resource communication and maximizing resource utilization under delay constraints. This method, originally designed for homogeneous resources, decomposes the problem into placement and routing. It iteratively ranks VFs on the basis of resource centrality and utilization, allocates them to preferred resources, routes connections, and refines the allocation if delay requirements are unmet. To support parallel processing, we add a minimal extension that splits a VFR into independent parallel sub-tasks only when a single VF cannot satisfy the throughput requirement. This extension does not alter the original decision logic of the conventional method. 4. ResultsFor each system, we evaluated five distinct cases by independently sampling the parameters in Table 1 once per case. Since these cases correspond to different configurations rather than repeated trials under identical conditions, we do not average the raw results across cases. Instead, we report representative cases: the best case, which yields the largest improvement over the conventional method, and the worst case, which yields the smallest improvement. The results of our simulation with the random and realistic systems are shown in Figs. 3 and 4, respectively. Note that the results are reported only up to the maximum number of services that satisfy all service-performance requirements. We gradually increased the number of requested services and stopped until at least one service-performance requirement was violated.
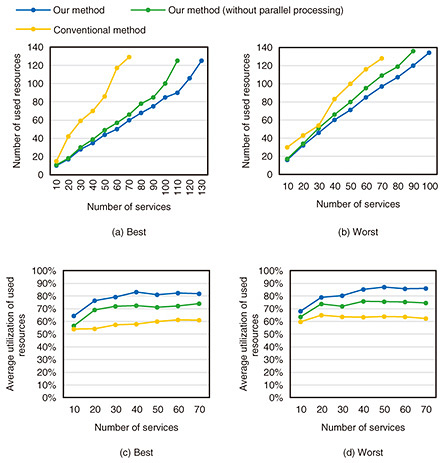
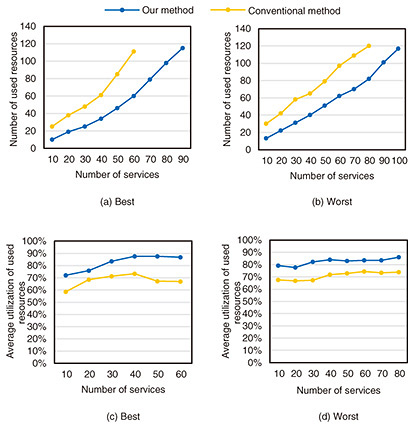
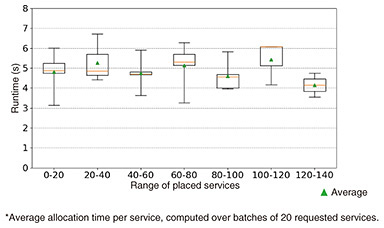
4.1 Random systemFigures 3(a), (b) show the results for the number of used resources and Figures 3(c), (d) illustrate resource utilization for best and worst cases, respectively. To evaluate the impact of the characteristics of heterogeneous computational resources without considering the impact of parallel processing, we also evaluated our method without parallel processing. Compared with the conventional method, our method decreased the number of resources by an average of 20 to 46% and increased the average resource utilization by an average of 16 to 20%. The difference arises from whether the characteristics of heterogeneous computational resources are accounted for. The conventional method without parallel processing struggles to allocate suitable resources, leading to lower performance and the need for additional resources. In contrast, our method effectively matches resources to VFRs, reducing the number of resources. It also improves resource utilization by accounting for the provisional utilization of resources on the basis of the impact of the characteristics of heterogeneous computational resources. Compared with the conventional method, our method with parallel processing decreased the number of resources by an average of 28 to 51% and increased the average resource utilization by an average of 29 to 35%. These results indicate that our method can further increase resource utilization and decrease the number of resources with parallel processing. The above findings clarify the importance of accounting for the characteristics of heterogeneous resources and parallel processing to maximize resource efficiency and utilization. 4.2 Realistic systemFigures 4(a), (b) show the results for the number of used resources and Figures 4(c), (d) illustrate resource utilization for best and worst cases, respectively. We evaluated the effectiveness of our method in practical cases. Compared with the conventional method, our method decreased the number of resources by an average of 41 to 49% and increased the average resource utilization by an average of 16 to 22%. These results indicate that our method will be beneficial in real-world environments. 4.3 RuntimeFigure 5 shows the distribution of the average allocation times for the 20 services in the random system, grouped by the number of services placed in the system. For each group, the box plot represents the variability of allocation time across different parameter settings, while the triangle marker indicates the average allocation time for each case. The results indicate that our method can allocate resources in all cases within ten seconds per service on average, which is considered acceptable for resource allocation before service execution. Although some variation in allocation time can be observed across different service groups, no clear increasing trend is observed as the number of placed services increases. This indicates that system usage has no effect on resource allocation time, even when the overall utilization of the system is high. These findings suggest that our method executes stable resource allocation regardless of system usage.
5. ConclusionWe introduced our resource allocation method for disaggregated computing that efficiently uses heterogeneous computational resources. The method explicitly accounts for both the performance characteristics of heterogeneous resources and the effects of parallel processing, enabling efficient execution of services through direct interconnection among heterogeneous computational resources. Simulation results on heterogeneous disaggregated systems indicate that our method reduces the number of required resources by an average of 28–51% in random systems and achieves effective resource utilization in realistic system configurations. These results highlight the importance of jointly considering heterogeneous resource characteristics and parallel processing in resource allocation. Runtime evaluation also confirms that our method can derive allocation solutions within a practical amount of time. Overall, the results indicate that our method effectively maximizes resource utilization while satisfying service-performance requirements in disaggregated computing systems. The insights obtained from this study are also applicable to future architectures such as IOWN DCI, where large-scale heterogeneous resource pooling and accelerator-centric communication are expected to play a key role. Our method may lead to significant cost reductions and lower energy consumption, offering a pathway toward more sustainable and economically viable datacenter operations. References
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||