 |
|||||||||||||||||||||
|
|
|||||||||||||||||||||
       |
Feature Articles: Collaborations with Universities Leading to Open Innovation in NTT's R&D Vol. 9, No. 10, pp. 24–28, Oct. 2011. https://doi.org/10.53829/ntr201110fa3 Automatic Generation of
English Cloze Questions
|
||||||||||||||||||||

| † | NTT Communication Science Laboratories Soraku-gun, 619-0237 Japan |
|---|
1. Introduction
With the development of information and communications technology (ICT), e-learning has become popular. One of its main benefits is that each user can learn in accordance with his or her own achievement level, interests, and pace. However, we need to prepare a huge quantity of learning materials in order to suit the levels and interests of a wide variety of users.
To resolve this problem, we are researching and developing systems that generate learning materials automatically. By fusing e-learning technology studied in Nagoya University and machine learning technology studied in NTT, we have developed a system that automatically generates multiple-choice cloze questions for English, which we call MAGIC (multiple-choice automatic generation system for cloze questions) [1]. Some examples of multiple-choice cloze questions are shown in Fig. 1. There were several reasons for focusing on this type of English questions. First, a lot of Japanese learn English, and English learning is in demand not only in Japan but all over the world. Second, this question type is common and used in TOEIC (test of English for international communication) and university entrance examinations.

Fig. 1. Input and output of MAGIC.
MAGIC takes English sentences as input. Users may input just one sentence or multiple sentences from newspaper articles and novels. MAGIC sorts the sentences in order of appropriateness for English questions and outputs sentences containing blanks and four options for each blank. Figure 1 shows an example of MAGIC's input and output.
MAGIC can be used for a variety of ways. First, by entering English sentences that match their own interests, users can learn while having fun. For example, users who like football can learn English using football articles, and users can learn using novels by authors that they like. Second, users can learn a type of English that suits their study purpose. For example, users can learn business English by using business news articles, scientific English by using scientific papers, and travel English by using travel guidebooks. Third, users can overcome their weak points by generating and learning questions that test them.
The interests and goals for learning depend on users, and they may change over time. Therefore, it is difficult to prepare learning materials that meet the diverse interests and goals of all users.
2. Rule extraction using machine learning
MAGIC has three components, which 1) sort sentences in order of appropriateness for English questions, 2) determine words to be blanked, and 3) generate multiple choices. The procedures of MAGIC are shown in Fig. 2. For these three components, we need rules for evaluating the appropriateness of English questions, selecting words to be blanked, and generating choices, respectively. However, such rules are not available, and humans do not generate questions by following explicit rules.
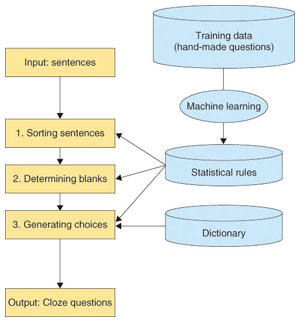
Fig. 2. Procedures of MAGIC.
MAGIC can automatically extract these rules by using machine learning techniques, which find statistical rules from given training data by using computers. The training data for MAGIC are manually generated English questions. By analyzing hand-made questions, we can extract rules for sorting sentences and generating blanked sentences with their multiple choices.
By changing the training data, we can change the question generating characteristics. For example, by using TOEIC questions for the training data, we can generate questions that are similar to TOEIC questions. We can also increase the level of difficulty by using high-level questions for the training.
3. Question generation procedures
In this section, we explain each component in detail.
3.1 Sorting sentences
Some of the input sentences might be appropriate and some of them might be inappropriate for English questions. For example, sentences that contain important idioms and have important grammar structures are more appropriate for questions. MAGIC sorts English sentences by comparing hand-made questions (training data) and standard English sentences by using preference learning [2]. An example is shown in Fig. 3. Preference learning enables us to assign high preference scores to sentences that are similar to the training data. The similarities can be calculated by using word appearance frequencies and parts of speech (POSs) in the sentences. By sorting input sentences in preference score order, users can learn English with appropriate sentences for questions.
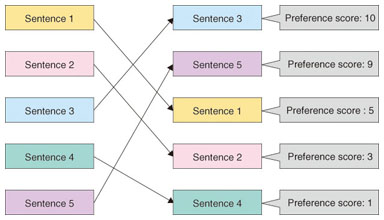
Fig. 3. Sorting sentences on the basis of preferences.
3.2 Determining blanks
Determining words to be blanked can be regarded as a sequence labeling problem in machine learning. The sequence labeling problem is to estimate an optimal label sequence for a given input sequence. In our case, the input sequence is a sentence (word sequence), and the output label sequence is a sequence that represents the blank's position. The label sequence can be represented as shown in Fig. 4, where B, I, and O are standard IOB2 tags indicating the blank's beginning and words inside and outside the blank, respectively. With MAGIC, we use Conditional Random Field (CRF) [3], which has achieved high performance in sequence labeling problems. As features for CRF, we used words around the blank and their POSs. We confirmed that by using these features, we could select the words to be blanked more accurately than by using conventional methods.

Fig. 4. Determining blanks by using sequence labeling.
3.3 Generating choices
MAGIC generates multiple choices on the basis of statistical information and patterns obtained from the training data. We classify a set of choices into two types by the blank's POS. The first type is a POS that restricts words that can be chosen. For example, when the preposition of is blanked, the alternative choices are likely to be other prepositions such as to, in, and at. The words of an interrogative and auxiliary verb are also included in this type as well as prepositions. With this type, we can generate choices by considering the POS and word probabilities. The second type is a part of speech that has patterns in conjugation, orthography, or meaning. This type includes verbs, adjectives, and nouns. For example, patterns include various conjugations of the same base word (ask, asked, asking, asks), the same prefix or postfix (defective, elective, emotive, active), and similar meanings (told, said, spoke, talked). This type lets us select a pattern in accordance with the POS and generate choices using dictionaries. The flow of choice generation is shown in Fig. 5.
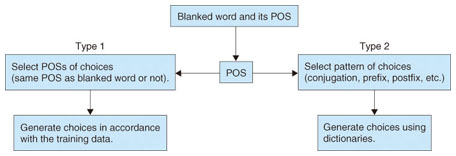
Fig. 5. Flow of choice generation.
4. Conclusion
We are developing a system for automatically generating English cloze questions. We would like to sort sentences in order of user interests or difficulties [4], and this leads to personalized learning. We would also like to extend the system so that it can generate questions for learning other languages besides English and to generate learning materials in other subjects such as history and mathematics.
References
| [1] | T. Goto, T. Kojiri, T. Watanabe, T. Iwata, and T. Yamada, "Automatic Generation System of Multiple-choice Cloze Questions and Its Evaluation," Knowledge Management & E-Learning: An International Journal (KM&EL), Vol. 2, No. 3, pp. 210–224, 2010. |
|---|---|
| [2] | M. Collins and N. Duffy, "New Ranking Algorithms for Parsing and Tagging: Kernels over Discrete Structures, and the Voted Perceptron," Proc. of the 40th Annual Meeting of the Association for Computational Linguistics, pp. 263–270, 2001. |
| [3] | J. Lafferty, A. McCallum, and F. Pereira, "Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data," Proc. of the 18th International Conf. on Machine Learning, pp. 282–289, 2001. |
| [4] | T. Iwata, T. Kojiri, T. Yamada, and T. Watanabe, "Recommendation for English Multiple-choice Cloze Questions Based on Expected Test Scores," International Journal of Knowledge-based Intelligent Engineering Systems, Vol. 15, No. 1, pp. 15–24, 2011. |
 |
|
|---|---|
 |
|
 |
|
 |
|
 |
|