|
|||||||||||||||
|
|
|||||||||||||||
       |
Feature Articles: Communication Science as a Compass for the Future Vol. 13, No. 11, pp. 19–24, Nov. 2015. https://doi.org/10.53829/ntr201511fa4 Deep Learning Based Distant-talking Speech Processing in Real-world Sound EnvironmentsAbstractThis article introduces advances in speech recognition and speech enhancement techniques with deep learning. Voice interfaces have recently become widespread. However, their performance degrades when they are used in real-world sound environments, for example, in noisy environments or when the speaker is some distance from the microphone. To achieve robust speech recognition in such situations, we must make progress in further developing various speech processing techniques. Deep learning based speech processing techniques are promising for expanding the usability of a voice interface in real and noisy daily environments. Keywords: deep learning, automatic speech recognition, speech enhancement
1. IntroductionIn recent years, the use of voice-operable smartphones and tablets has become widespread, and their usefulness has been widely recognized. When a user speaks carefully into a terminal, that is, a microphone(s) (Fig. 1(a)), his/her voice is usually accurately recognized, and the device works as expected. On the other hand, there is a growing need for voice interfaces that can work when a user speaks at a certain distance from the microphones. For example, when we record the discussion in a meeting, as shown in Fig. 1(b), we may want to employ a terminal on the table and avoid the use of headset microphones. Furthermore, when users talk to voice-operated robots or digital signage, the users would talk to them from a certain distance.
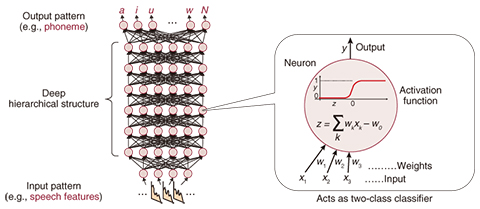
However, the current speech recognition accuracy of voice-operable devices is generally insufficient when the speaker is far away from the microphone. This is because of the considerable effect of noise and reverberation and because the users speak freely with little awareness of the microphones when the microphones are some distance away. We are therefore studying distant speech recognition and working on speech enhancement and speech recognition techniques to expand the usability of a voice interface in real-world sound environments. There are two main factors that degrade the automatic speech recognition of distant speech; (1) the quality of speech recorded with a distant microphone is severely degraded by background noise, for example, air conditioners and room reverberation. Moreover, in a multi-person conversation, the speakers’ voices sometimes overlap. (2) As the users speak freely without regard to the microphones, their utterances become fully spontaneous and therefore tend to include ambiguous pronunciations and abbreviations. Speech enhancement techniques are essential in order to cope with such complex difficulties, and these include noise reduction, reverberation reduction (dereverberation), speech separation, and spontaneous speech recognition techniques. 2. Deep learning in speech processingWe have been studying the aforementioned speech processing techniques in order to achieve distant speech recognition in the real world. In recent years, we have been working on speech processing methods based especially on deep learning. Deep learning is a machine learning method that uses a deep neural network (DNN), as shown in Fig. 2. Deep learning has recently come under the spotlight because in 2011 and 2012 it was shown to outperform conventional techniques in many research fields including image recognition and compound activity prediction. High performance has also been achieved with deep learning in speech recognition tasks, and therefore, deep learning based speech processing techniques have been intensively researched in recent years. In 2011, we began working on deep learning based techniques for automatic recognition of spontaneous speech [1]. It should be noted that a deep learning based real-time speech recognizer developed by NTT Media Intelligence Laboratories has already been released [2]. We have also proven that deep learning improves speech enhancement techniques such as noise reduction when deep learning is effectively leveraged. The remainder of this article describes our speech recognition and speech enhancement techniques that employ deep learning.
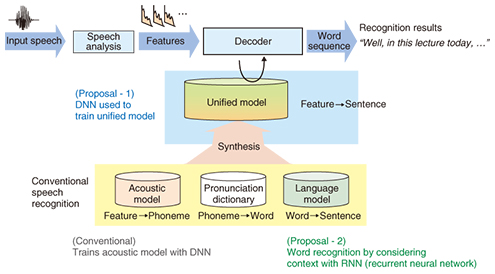
3. Speech recognition with deep learningGeneral automatic speech recognition techniques translate features into phonemes, phonemes into words, and words into sentences, by respectively using an acoustic model, a pronunciation dictionary, and a language model (Fig. 3). Originally, deep learning based speech recognition employed a DNN to achieve accurate acoustic modeling, and it outperformed conventional speech recognition techniques that do not use deep learning.
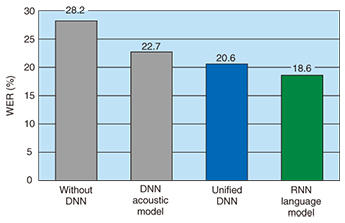
The aforementioned acoustic model, pronunciation dictionary, and language model are usually trained separately, so it has been difficult to consider the interaction between the phonetic and linguistic factors that are present in spontaneous speech. To address these complex factors, we proposed synthesizing the three models into a unified model (Fig. 3) and optimizing it by using a DNN [1]. We demonstrated that this unified model achieves highly accurate spontaneous speech recognition [1]. Moreover, we showed that a recurrent neural network (RNN), which is also a deep learning technique, in a language model provides further improvement in performance. An RNN based language model is effective for spontaneous speech recognition because its ability to hold the history of words enables us to recognize speech by considering a longer context. However, it is generally difficult to achieve fast automatic speech recognition while maintaining the complete contextual history. We therefore proposed an efficient computational algorithm for maintaining contexts and achieved fast and highly accurate automatic speech recognition [3]. The word error rates (WERs) in English lecture speech recognition are shown in Fig. 4. Without DNN indicates the WER before deep learning was employed. The DNN acoustic model shows the large effect of deep learning. We can also see that the unified DNN, where the unified model is optimized with a DNN, outperforms the conventional DNN acoustic model. Moreover, the RNN language model achieves the best performance, which is more than 4 points better than the conventional DNN acoustic model. The appropriate use of deep learning techniques significantly improves spontaneous speech recognition performance.
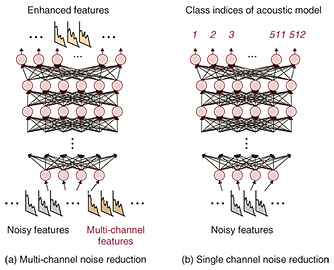
4. Speech enhancement with deep learningDeep learning also helps to improve speech enhancement performance. This section introduces two noise reduction techniques: a method for use with multiple microphones and a method for use with a single microphone. The first approach estimates the features of noise-reduced speech by using a DNN (Fig. 5(a)). Pairs consisting of clean and noisy speech signals are used to train the DNN to translate noisy speech features into clean speech features. The trained DNN is then used to estimate noise-reduced features when the input consists of noisy features. This method was originally used for noise reduction with a single microphone, however, its extension to multi-microphone use was not obvious. We found that we can improve noise reduction performance by inputting additional features estimated with multi-microphone observations into a DNN. We also found that the probability of speech existing at each time-frequency slot, which can be estimated with a microphone array technique, provides us with an effective additional feature [4]. The results of an evaluation conducted under living room noise conditions (PASCAL CHiME challenge task) revealed the superiority of our proposed approach. Specifically, we obtained a reduced WER of 8.8% by using the proposed multi-microphone features compared to a value of 10.7% without them. The second noise reduction approach is for cases where we can use just a single microphone. This method is applied to calculate noise reduction filter coefficients by using probabilistic models of clean speech and noise without speech. Here, accurate model estimation is important for accurate filter design. We showed that DNN-based clean speech model estimation (Fig. 5(b)) achieves high-performance noise reduction [5]. Specifically, we constructed a clean speech model with a set of probabilistic models and utilized a DNN to discriminate the most suitable model for generating the observed noisy speech. With this proposed noise reduction approach, we obtained an improved WER of 19.6% for a noisy speech database (AURORA4), whereas the WER was 23.0% with a conventional method without a DNN.
It is worth mentioning that we do not use a DNN for noise model estimation. This is because it is difficult to obtain a sufficient quantity of noise data for DNN training due to the wide range of variations and momentary fluctuations of noise in the real world. With the proposed method, we estimate the noise model using an unsupervised method, and we simultaneously use a DNN for clean model selection. This approach achieves high-performance noise reduction in real-world sound environments by flexibly considering the variation of noisy signals. 5. OutlookWe believe that distant-talking speech processing is a key technology for expanding the usability of voice interfaces in actual daily life. In particular, conversational speech recognition and communication scene analysis in real-world sound environments are techniques that meet the needs of the times. These techniques should make a significant contribution to artificial intelligence (AI) speech input, which has recently attracted renewed interest for applications such as minute-taking systems in business meetings, intelligent home electronics, and a human-robot dialogue system for use in shopping centers. For these purposes, we need a highly accurate distant speech recognition technique that works in noisy environments. In addition, techniques for identifying the current speakers and for understanding what is going on around the AI device by recognizing, for example, environmental sound events [6], are also becoming more important. We are continuing to work on the development of essential techniques for distant-talking speech processing in order to expand the capabilities of voice interfaces to their fullest extent. References
|
||||||||||||||