|
|||||||||||||||
|
|
|||||||||||||||
       |
Feature Articles: Communication Science that Enables corevo®—Artificial Intelligence that Gets Closer to People Vol. 15, No. 11, pp. 35–39, Nov. 2017. https://doi.org/10.53829/ntr201711fa6 Personalizing Your Speech Interface with Context Adaptive Deep Neural NetworksAbstractThis article introduces our recent progress in speaker adaptation of neural network based acoustic models for automatic speech recognition. Deep neural networks have greatly improved the performance of speech recognition systems, enabling the recent widespread use of speech interfaces. However, recognition performance still greatly varies from one speaker to another. To address this issue, we are pursuing research on novel deep neural network architectures that enable rapid adaptation of network parameters to the acoustic context, for example, the speaker voice characteristics. The proposed network architecture is general and can potentially be used to solve other problems requiring adaptation of neural network parameters to some context or domain. Keywords: deep learning, automatic speech recognition, speaker adaptation
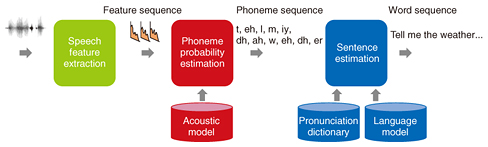
1. IntroductionAutomatic speech recognition (ASR) is being used more and more in our everyday life. For example, it is now common to speak to our smartphones to ask for the weather forecast or the nearest restaurant. Communication agents such as home assistants and robots are also starting to enter our living rooms, suggesting that speech may become a common modality for accessing information in the near future. The rapid expansion of ASR based products has been made possible by the significant recognition performance gains achieved through the recent introduction of deep neural networks (DNNs) [1]. However, simply using DNNs does not solve all the issues. Speech recognition performance can still greatly vary depending on the acoustic context such as the speaker voice characteristics or the noise environment. In this article, we describe our approach to tackle this problem by making the ASR system adaptive to the acoustic context. To achieve this, we have developed a novel DNN architecture that we call context adaptive DNN (CADNN) [2]. A CADNN is a neural network whose parameters can change depending on the external context information such as speaker or noise characteristics. This enables us to rapidly generate an ASR system that is optimal for recognizing speech from a desired speaker, opening the way to better ASR performance. In the remainder of this article, we briefly review how current ASR systems work, focusing on the acoustic modeling part. We then describe in more detail the proposed CADNN and a speaker adaptation experiment we conducted to confirm its potential. We conclude this article by discussing some outlooks on potential extensions of CADNNs to achieve online speaker adaptation and applications to other research areas. 2. Deep learning based acoustic modelingA speech recognition system is composed of several components, as illustrated in Fig. 1. First, there is a feature extraction module, which extracts speech features from each short time frame of about 30 ms of a speech signal. Then, the acoustic model computes the probability that a speech feature corresponds to a given phoneme. Finally, the decoder finds the best word sequence given the input sequence of features by taking into account the phoneme probabilities obtained from the acoustic model, a pronunciation dictionary that maps the phoneme sequences to words, and scores obtained from the language model that outputs the probability of word sequences. In the remainder of this article, we focus our discussion on the acoustic model, and in particular on speaker adaptation.
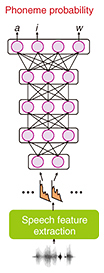
Recently developed acoustic models use DNNs to map speech features to phoneme probabilities. An example of such an acoustic model is shown in Fig. 2. A DNN consists of several hidden layers that perform a nonlinear transformation of their input. With these stacked hidden layers, a DNN can model a complex mapping between its input features and its outputs. In the context of acoustic modeling, the inputs are speech features and the outputs are phoneme probabilities. Training such a DNN requires a large amount of speech data, from a few dozen hours to thousands of hours, depending on the task. The training data must also include the actual spoken phoneme sequences that can be derived from manual transcriptions of the utterances. With such training data, the acoustic model training follows the standard procedure for training DNNs such as error backpropagation with stochastic gradient descent.
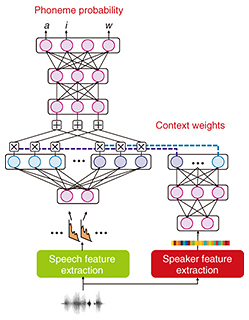
To ensure that the acoustic model can well recognize speech in a variety of acoustic contexts such as for different speakers, the training data must contain speech from a large variety of speakers. Using such diverse training data enables us to obtain a good model on average. However, the DNN may not be optimal for a given speaker seen during the deployment of the recognition system because of the speaker’s specific speaking style, which may result in poorer ASR performance for that particular speaker. Solving this issue requires us to adapt the acoustic model to the desired speaker. However, adapting the acoustic model is challenging because it is often difficult to obtain the large amount of speech data with transcription that would be needed to train an acoustic model for the desired context. Specifically, it is impractical to require several hours of speech from each user to create a personalized acoustic model. In many applications, acoustic model adaptation should thus be rapid, that is, requiring a small amount of speech data such as a few seconds, and unsupervised, meaning it does not require transcribed data. 3. CADNNExtensive research has been done to find approaches for adapting an acoustic model to speakers. A recent promising attempt consists of informing the DNN about the speaker by adding to its input an auxiliary feature describing the speaker characteristics. Such approaches have interesting properties because the speaker feature can be computed with only a few seconds of speech data, and they do not require transcriptions. However, simply adding an auxiliary feature to the input of a DNN has only a limited effect, as it can only partially adapt the DNN parameters. In this article, we describe an alternative way to exploit auxiliary information through a CADNN. The idea behind CADNN is that a network trained for a given context should be optimal to recognize speech in that acoustic context. For example, we could build different networks to recognize speech from female and male speakers. Adaptation could then be realized simply by selecting the network corresponding to the target acoustic context. Such a naïve approach raises two issues. First, only part of the training data can be used for training each of the separate models. This would seem to be suboptimal because, for example, some speech characteristics are common to all speakers, and thus, better models could be trained when exploiting all the training data. Another issue is that it is unclear how to select the acoustic model in an optimal way. The CADNN addresses these issues by making only part of the network dependent on the acoustic context. Moreover, we propose to select the model parameters using auxiliary features representing the acoustic context such as the speaker characteristics. A schematic diagram of a CADNN is shown in Fig. 3 [3]. As illustrated in the figure, a CADNN has one hidden layer replaced by a context adaptive layer, that is, a layer that is split into several sublayers, each associated with a different acoustic context class.
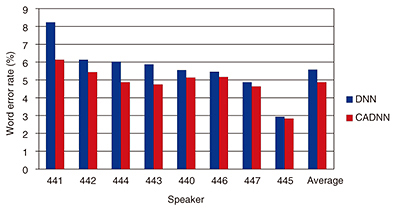
For example, with two acoustic context classes, we could have a sublayer for male speakers and a sublayer for female speakers. The output of the hidden layer is obtained as a weighted sum of the output of each sublayer, with context weights derived from the auxiliary features. In our implementation, the context weights are computed from a small auxiliary network that has the auxiliary features as inputs. The outputs are the context weights that are optimal for recognizing speech for that acoustic context. A CADNN has several interesting properties. The auxiliary network and the CADNN can be connected and trained jointly. This means that we can obtain context weights that are optimal for the acoustic context. Moreover, using such a joint training scheme, we do not need to explicitly define the acoustic context classes; they can be automatically learned from the training data during the training procedure. Finally, since except for the factorized layer, the rest of the network is shared among all the different acoustic context classes, all the training data can be used to train the parameters of the network. 4. Rapid speaker adaptation with CADNNA CADNN can be used to achieve rapid speaker adaptation of acoustic models. The graph in Fig. 4 shows the word error rate for recognition of English sentences read from the Wall Street Journal. Note that lower word error rates indicate better ASR performance. Our baseline system consists of a DNN with five hidden layers with ReLU (rectified linear unit) activations. The proposed CADNN uses a similar topology to that of the baseline DNN but has its second hidden layer replaced with a context adaptive layer, with four context classes. As auxiliary features, we use features representing speakers that are widely used for speaker recognition tasks. These auxiliary features were computed using a single utterance, which corresponds in this experiment to less than 10 s of speech data. Moreover, the speaker features can be obtained without transcriptions.
These results demonstrate that the proposed CADNN was able to significantly improve ASR performance, with a relative improvement of about 10% over the baseline. Since only a few seconds of speech data without transcriptions are sufficient to compute the auxiliary features, this experiment proves that CADNN can achieve rapid unsupervised speaker adaptation. 5. OutlookThe proposed CADNN appears promising for unsupervised rapid speaker adaptation of acoustic models. Potential further improvement could be achieved by developing better speaker representation for the auxiliary features [4]. Moreover, extension of the proposed scheme to online adaptation, where the adaptation process could start with even less data, is also a challenging research direction [5]. Finally, the proposed CADNN architecture is general and could be applied to other problems. For example, we are currently exploring the use of the same principle to extract a target speaker from a mixture of speakers [6]. We also believe that the proposed CADNN could be employed in other fields requiring context or domain adaptation of DNNs. References
|
||||||||||||||