|
|||||||||||||||||||||||
|
|
|||||||||||||||||||||||
       |
Feature Articles: Adapting to the Changing Present and Creating a Sustainable Future Vol. 20, No. 10, pp. 49–55, Oct. 2022. https://doi.org/10.53829/ntr202210fa7 AI Hears Your Voice as if It Were Right Next to You—Audio Processing Framework for Separating Distant Sounds with Close-microphone QualityAbstractWhen we capture speech using microphones far from a speaker (distant microphones), reverberation, voices from other speakers, and background noise become mixed. Thus, the speech becomes less intelligible, and the performance of automatic speech recognition deteriorates. In this article, we introduce the latest speech-enhancement technology for extracting high-quality speech as if it were recorded using a microphone right next to the speaker (close microphone) from the sound captured using multiple distant microphones. We discuss a unified model that enables dereverberation, source separation, and denoising in an overall optimal form, switch mechanism that enables high-quality processing with a small number of microphones, and their integration with deep learning-based speech enhancement (e.g., SpeakerBeam). Keywords: speech enhancement, microphone array, far-field speech recording
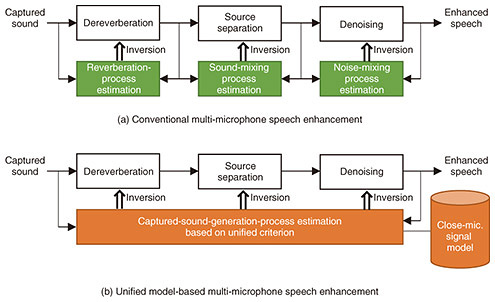
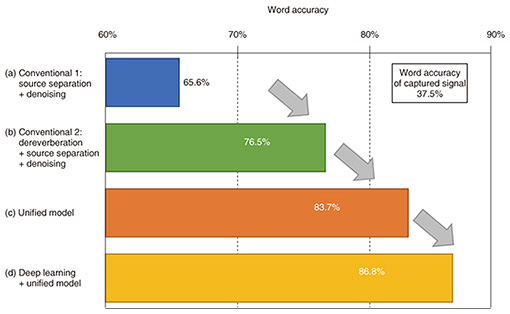
1. IntroductionHigh-quality speech applications using a microphone placed near the speaker’s mouth (close microphone) have been widely used, such as automatic speech recognition (ASR) using a smartphone and remote conferencing using a headset. For artificial intelligence (AI) to become a more practical assistant in our daily lives, it is required to handle speech in the same manner even when the speech is captured using microphones far from the speaker (distant microphones). However, with distant microphones, reverberation reflected from the walls or ceilings, voices from other speakers, and background noise become mixed. Therefore, the quality of the captured speech deteriorates significantly, and the performance of speech applications, such as ASR, greatly degrades. To solve this problem, we are developing speech-enhancement technology for extracting a high-quality voice of each speaker as if it were captured with a close microphone from sound captured with distant microphones. This article introduces the latest technology for multi-microphone speech enhancement that uses multiple microphones for achieving higher quality processing than with a single microphone. 2. Challenges for achieving close-microphone qualityTo extract a speech with close-microphone quality from sound captured using distant microphones, it is necessary to achieve three types of processing: dereverberation, source separation, and denoising. Dereverberation transforms a blurry speech with a distant impression into a clear speech with the impression of being right next to the microphone. When multiple speakers’ voices and background noise are mixed, they are separated into individual sounds by source separation and denoising. This makes it possible to extract each speaker’s voice with close-microphone quality. Conventional multi-microphone speech-enhancement methods achieve dereverberation, source separation, and denoising by estimating the generation processes of captured sound, in which sounds propagate from the sources to the microphones and mix, then applying the inverse of the estimated processes to the captured sound (Fig. 1(a)). Specifically, the processes of reverberation reflecting from walls or ceilings and reaching the microphones, multiple sounds coming from different directions and mixing, and noise coming from all directions and mixing are estimated, then their inversions are applied. For example, WPE (weighted prediction error) [1] developed by NTT is the world’s first dereverberation method. It can achieve almost perfect dereverberation by estimating the reverberation process of the captured sound without any prior knowledge on what environments in which the sound was captured (i.e., by blind processing), provided the captured sound does not contain noise. Independent component analysis [2, 3], which has been actively studied worldwide by researchers, including NTT, can achieve precise source separation by blind processing, provided the captured sound does not contain reverberation. However, these conventional multi-microphone speech-enhancement methods cannot be used to solve the three problems (reverberation, multiple sound sources, and noise) at the same time in an overall optimal form. It is impossible to simultaneously estimate all generation processes from the captured sound, which is a mixture of noise, reverberation, and multiple sounds, and execute the inversion of the entire process. Therefore, we have to apply each process in turn. For example, dereverberation is executed first assuming that noise is absent, so precise dereverberation is impossible. We then apply sound-source separation and denoising, assuming that reverberation is wholly suppressed; thus, the best performance cannot be achieved. It is therefore impossible to achieve overall optimal speech enhancement when combining these conventional methods. The sound captured using distant microphones almost always contains reverberation, multiple sound sources, and noise. For this reason, it has been considered critical to optimally apply the three types of processing, dereverberation, source separation, and denoising, in an overall optimal form. 3. Unified model for dereverberation, source separation, and denoisingIn response to this, we devised a unified model that can solve the three problems in an overall optimal form [4, 5]. The unified model first mathematically models the general properties that close-microphone quality speech and noise must satisfy. It can then enable overall optimum processing by optimizing each type of processing on the basis of the unified criterion that the sound obtained from combining the three types of processing best satisfies the close-microphone property (Fig. 1(b)). For example, we can significantly improve ASR using distant microphones with the unified model (Figs. 2(a)–(c)).
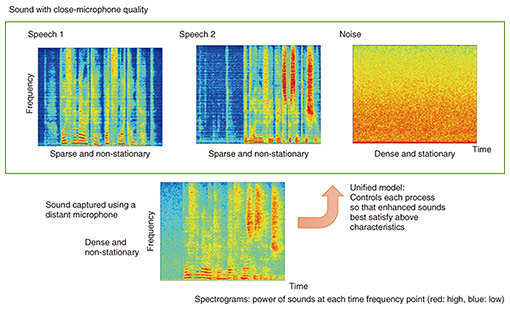
Figure 3 shows a spectrogram of two speech signals and noise captured using a close microphone and the mixture of them captured using a distant microphone. The speech signals captured using the close microphone are sparse signals in which the sound concentrates in separate local areas, and are non-stationary signals that change with time. In contrast, noise is a dense and stationary signal in which the sound spreads over a wider area and does not change much with time. However, the mixture captured using a distant microphone has different characteristics. It is denser than the speech signals with close-microphone quality and more non-stationary than noise with close-microphone quality.
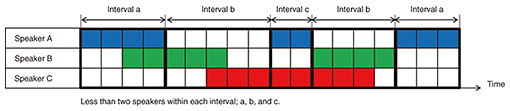
The unified model uses the differences in these sound characteristics. It controls dereverberation, source separation, and denoising so that the sound resulting from their application best satisfies the characteristics of speech and noise with close-microphone quality. For example, in dereverberation, we estimate the reverberation-generation process and apply its inversion so that the sound obtained in combination with source separation and denoising best satisfies the close-microphone quality. Similarly, we optimize source separation and denoising by estimating the sound-generation process and applying its inversion to best satisfy the close-microphone quality when combined with dereverberation. With the aim of achieving close-microphone quality, it has become possible to execute overall optimum processing when combining all types of processing. We have also developed computationally efficient algorithms for unified model-based multiple microphone speech enhancement [6, 7]. For example, the processing using the unified model illustrated in Fig. 2 (executing overall optimization of dereverberation, source separation, and denoising using eight microphones) can now be completed in real time using a Linux computer. When we limit the problem to extracting a speaker’s voice by blind processing from background noise and little reverberation, we can reduce the computational cost to the extent that real-time processing is possible even with an embedded device. 4. Switch mechanism enabling accurate estimation with a smaller number of microphonesA switch mechanism is an applied technology using the unified model and enables highly accurate estimation even with a relatively small number of microphones [8, 9]. With conventional multi-microphone speech-enhancement methods, it is necessary to use a sufficiently large number of microphones for precise processing compared with the number of sound sources included in the captured sound. This hinders the application of multi-microphone speech enhancement to real-life problems. To solve this problem, we introduce a switch mechanism that can improve estimation accuracy with a small number of microphones. The idea of this switch mechanism is summarized as follows. Even when the captured sound contains many sound sources, the number of sources appearing simultaneously can be smaller when counting them within each short time interval. Let us explain this using Fig. 4. The horizontal axis is time, and a horizontal bar in each color represents when each of the three speakers speaks. When we divide the horizontal axis into short intervals a, b, and c, as shown in the figure, only two speakers are speaking in each time interval even though there are three speakers in total. With this interval division, we can improve multi-microphone speech enhancement by applying it separately to each short interval with the decreased number of speakers. We call this a switching mechanism because we switch speech enhancement for each short interval.
When combined with the unified model, the switch mechanism can perform best. We can use the unified model to optimize the interval-wise application of speech enhancement and the switch mechanism’s time interval division. This unified model-based speech enhancement can optimize the all processing types (dereverberation, source separation, and denoising) with the switch mechanism so that the enhanced speech best satisfies the close-microphone quality. 5. Unified model as a versatile technique of audio-signal processingAs described above, our unified model provides theoretically and practically excellent guidelines for integrating the three processing types in speech enhancement that we have conventionally combined in more heuristic ways. The unified model can provide a mechanism to achieve overall optimization even when combining more complicated processing approaches such as the switch mechanism. We can use the unified model as a versatile technique providing a basis for future audio-signal processing-technology development. 6. Future direction: optimal integration with deep learningDeep learning is another fundamental approach to speech enhancement, and its integration with multi-microphone speech-enhancement methods is vital for the future development. While deep learning can conduct processing that is difficult with multi-microphone speech enhancement, such as voice characteristics-based selective listening using SpeakerBeam, a deep learning-based approach for computational selective hearing based on the characteristics of the target speaker’s voice [10], it also has severe limitations. For example, with deep learning-based speech enhancement, improvement in ASR performance is minimal, and sound quality largely degrades due to reverberation. Therefore, both deep learning and multi-microphone speech-enhancement methods complement each other, thus are indispensable. For example, even when the ASR performance or quality of enhanced speech does not much improve solely by deep learning-based speech enhancement, they can be improved when combined with the multi-microphone speech enhancement. Figure 2(d) shows that the combined approach further improves ASR performance compared with solely using the unified model-based multi-microphone speech enhancement. Speech enhancement will have much higher functionality and quality through developing an optimal integration method for both deep learning and multi-microphone speech enhancement. References
|
||||||||||||||||||||||